import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
import torch
from torch.distributions.normal import Normal
from torch.autograd import Variable
from typing import List, Optional
class GaussianGradientBoosting:
def __init__(self,
learning_rate: float = 0.025,
max_depth: int = 1,
n_estimators: int =100):
self.learning_rate: float = learning_rate
self.max_depth: int = max_depth
self.n_estimators: int = n_estimators
self.init_mu: Optional[float] = None
self.mu_trees: List[DecisionTreeRegressor] = []
self.init_sigma: Optional[float] = None
self.sigma_trees: List[DecisionTreeRegressor] = []
self.is_trained: bool = False
def predict(self, X: np.array) -> np.array:
assert self.is_trained
mus = self._predict_mus(X).reshape(-1,1)
log_sigmas = np.exp(self._predict_log_sigmas(X).reshape(-1,1))
return np.concatenate([mus, log_sigmas], 1)
def _predict_raw(self, X: np.array) -> np.array:
assert self.is_trained
mus = self._predict_mus(X).reshape(-1,1)
log_sigmas = self._predict_log_sigmas(X).reshape(-1,1)
return np.concatenate([mus, log_sigmas], 1)
def fit(self, X: np.array, y: np.array) -> None:
self._fit_initial(y)
self.is_trained = True
for _ in range(self.n_estimators):
y_pred = self._predict_raw(X)
gradients = self._get_gradients(y, y_pred)
mu_tree = DecisionTreeRegressor(max_depth=self.max_depth)
mu_tree.fit(X, gradients[:,0])
self.mu_trees.append(mu_tree)
sigma_tree = DecisionTreeRegressor(max_depth=self.max_depth)
sigma_tree.fit(X, gradients[:,1])
self.sigma_trees.append(sigma_tree)
def _fit_initial(self, y: np.array) -> None:
assert not self.is_trained
self.init_mu = np.mean(y)
self.init_sigma = np.log(np.std(y))
def _get_gradients(self, y: np.array, y_pred: np.array) -> np.array:
y_torch = torch.tensor(y).float()
y_pred_torch = Variable(torch.tensor(y_pred).float(), requires_grad=True)
normal_dist = Normal(y_pred_torch[:,0], torch.exp(y_pred_torch[:,1])).log_prob(y_torch).sum()
normal_dist.backward()
return y_pred_torch.grad.numpy()
def _predict_mus(self, X: np.array) -> np.array:
output = np.zeros(len(X))
output += self.init_mu
for tree in self.mu_trees:
output += self.learning_rate * tree.predict(X)
return output
def _predict_log_sigmas(self, X: np.array) -> np.array:
output = np.zeros(len(X))
output += self.init_sigma
for tree in self.sigma_trees:
output += self.learning_rate * tree.predict(X)
return output
Introduction
In today’s tech landscape, Kubernetes has become synonymous with scalable and resilient application hosting. But what happens when you combine it with the relatively humble task of hosting a static blog? Well, I went down that rabbit hole and set up this blog on a bare-metal Kubernetes cluster. To be exact, this is the second time I have done this. After switching back and forth between various content management systems for blogs, I have decided it was finally time to move back to a static quarto site, hosted on good old K8s.
Could I have done this with GitHub Pages? Sure. Did I want to take the long (and more complicated) route? Absolutely.
Let me walk you through my experience setting up a Kubernetes-powered blog, and how it all came together.
Design Goals
From the outset, I had some design goals for this project:
- Cost-effectiveness: I wanted the whole setup to be cheap. No managed Kubernetes, no fancy cloud providers — just affordable VMs running the underlying Kubernetes nodes.
- Continuous deployment: Any push to the blog’s master branch in GitHub should automatically deploy the latest blog content.
- Notebooks integration: There also exists another repository where I store rather raw, uncommented experiments in Jupyter notebooks, too. Despite them being mostly code-only, I found that they might still be interesting to read, so they should be included here as well. Thus, each deployment of the main blog should also copy and include all notebooks from this second repository.
- Simplicity: Although the underlying infrastructure is rather complex, deploying and updating the blog should be rather simple. This means, ideally, no crazy CRD extensions but only out-of-the-box Kubernetes resources where possible.
Kubernetes Cluster Setup
Node Setup
Since managed Kubernetes was out of the question, I opted for a bare-metal Kubernetes setup with VMs. I rented three virtual machines from Contabo, a fairly budget-friendly hosting provider (no affiliation on my end). While they are not the most reliable VM provider and spinning up a new VM takes quite some time, they are cheap and things are working nicely most of the time.
With three machine as cluster nodes, I created one master and two worker nodes. This obviously doesn’t ensure high availability at all but keep in mind that we are still talking about a personal blog and not a critical production environment.
To automate some initial configuration, I created an Ansible playbook. The primary advantage here is being able to quickly tear down and rebuild the entire setup if necessary. As managing all necessary firewall configurations between the VMs turned out to be quite tedious, I also used WireGuard to set up a virtual network overlay. On the one hand, this adds some additional communication overhead. On the other hand, this only left the WireGuard port to worry about regarding communication amongst the cluster nodes.

Cluster Setup
For the Kubernetes cluster, I initially tried a raw kubeadm setup, but configuring Cilium as the CNI turned out to be much harder than expected. Accepting my defeat (for now), I went with Rancher’s RKE2 and things went relatively smooth from there. Installing ArgoCD then completed the, more or less, manual parts of the set-up. Every other installation is now managed by Argo.
Although persistent storage is not necessary at this point, I did some experiments that required setting up PVCs. As this is already an RKE2 cluster, it made sense to use Longhorn which was also reasonably straightforward to install.
Finally, to enable external traffic, I added metallb to the Kubernetes cluster and installed nginx to the control plane VM. Nginx then accepts external traffic and performs a proxy pass to the exposed metallb services.

You can find all cluster-wide ArgoCD installations here.
Hosting the Blog on Kubernetes
Now that the cluster was up and running, it was time to host the actual blog. Remember that an important goal is to keep the manual effort for deploying new edits at a minimum. As described by the quarto docs, the probably easiest way to host and deploy quarto sites is via GitHub. A simple GitHub Actions pipeline would be sufficient here to auto-deploy any updates to the underlying notebooks.
Since I want to keep open the option to add non-static functionality later on, this approach is unfortunately out of question. Rather, the implied automatism needs to be transferred to the more complex Kubernetes setup. At least I wanted to avoid having to manually update some image tag in the ArgoCD deployment, whenever I edited the blog.
First, I was playing around with a small customization of the git-sync image. The idea was to let the git-sync container poll for new commit in the blog repo and then trigger a Kubernetes Job to re-render the quarto files. The advantage here was that the repository containing the blog files only had to contain the notebooks and the quarto yaml files. In essence, the blog would have been more or less completely decoupled from any infrastructure or deployment assumptions. There was also still the issue of incorporating the notebooks from the other repository.

At some point, I realized that this is unnecessarily complex, so I decided to go with a single container that ultimately exposes a Caddy static file server. You can find the whole build process in the GitHub-Actions configuration and the corresponding Dockerfile.
Now, whenever the blog is updated, a new blog image is built and tagged with the current datetime. Inside the build process, we add the notebooks from the second repository and slightly modifies the quarto configuration to include those additional files. Vice versa, whenever the second repository is updated, that repo remotely triggers the blog’s build process, too. This has been working nicely, without any issues so far.
To avoid manual updates to the image tags, I have also added the ArgoCD Image Updater. By simply adding the annotations,
annotations:
argocd-image-updater.argoproj.io/image-list: blog=ghcr.io/sarems/blog
argocd-image-updater.argoproj.io/blog.update-strategy: alphabeticalto the ArgoCD application yaml, the Image Updater automatically polls the ghcr.io image repository for updates.

If it finds a new image, the Argo application is automatically updated to use the newer image. The only caveat is that ArgoCD deployment either needs to be done on a Helm chart or a Kustomization. Here, I went with a rather simple Helm chart.

Conclusion and takeaways
Could I have hosted this blog on GitHub Pages? Absolutely. But where’s the fun in that? At the very least, I have improved a bit on setting up Bare Metals clusters from scratch. I still see failing to set it up with raw kubeadm in time as a personal weakness, though…
Nevertheless, the whole setup has been running perfectly stable as of now. Keep in mind though that this is a rather small, personal blog with low traffic. Time will tell if this would keep up with larger traffic, but I am reasonably optimistic.
What is definitely cool with this approach is being able to host other applications on the cluster and then incorporating them in rendered notebooks. I have successfully tested this idea in an old version of this blog. Thus, I’ll hopefully soon find time to showcase more applied things on this blog rather than just writing about some theoretical model ideas.
If you have any questions or ideas for improvements, please feel free to write me an email. I’ll absolutely try to answer, but time is quite sparse these days.
Introduction
Gradient Boosting is a powerful machine learning technique that can be used for both regression and classification problems. Its fundamental idea is to combine weak, almost trivial base model into a single strong ensemble. A fairly unique feature of Gradient Boosting is the loss minimization by calculating derivatives with respect to the model output, rather than model parameters.
This allows for the distinct capability to use non-differentiable models as a base learner, typically decision trees. In fact, there is probably not a single popular Gradient Boosting library that does not rely on trees. This allows Boosting models to handle complex, non-smooth data generating processes fairly well. As a result, popular implementations like XGBoost and LightGBM regularly dominate Kaggle competitions and the like.
PyTorch on the other hand is rather well known for programming Deep Learning type models. Thus, the idea to use PyTorch for Gradient Boosting might seem a bit odd at first. However, its capabilities are not limited to just Neural Networks but it is actually a much richer framework for anything AutoDiff. Whatever function we can express in its domain language, PyTorch will find the corresponding derivatives.
Hence, it should be interesting to let PyTorch find the deriviatives for increasingly complex loss functions. Then, we can apply the standard Gradinent Boosting algorithm to fit simple Decision Trees to those derivatives. This way, we can hopefully create models that are more flexible than standard Gradient Boosting implementations, but still as powerful.
A quick recap on Gradient Boosting
As already mentioned, in Gradient Boosting we are interested in the derivatives of the loss function with respect to the model output:
Notice that, here, we don’t use the chain rule to extend the above to the model parameters. Rather, we stick to the above and perform gradient descent in, roughly speaking, function space. At each gradient descent step, we fit our base learner to the negative gradients with respect to the previous round’s model output:
Here, is the ensemble of the first
base learners, denoted as
. Notice also that the MSE criterion is not necessarily the only one possible. For simplicity, we will stick to it in this post, though.
Word of caution
As an important side-note, consider the following: If we use the squared loss, i.e.
the derivative with respect to the model output is simply the residual:
If you first learn about Gradient Boosting in the context of regression, you might now be tempted to think that your base learner should always estimate the residual. Given the above, however, this is obviously not the case.
Updating the ensemble
Next, we want to update our ensemble by adding the new base learner. As already mentioned, we do this by performing what looks like a gradient descent step in function space:
Here, is the learning rate. In practice, we usually use a small value like 0.01 or 0.001.
Initializing the ensemble
The final question that remains is how to initialize the ensemble. Since our goal is to minimize the loss function, we should use a model that acts accordingly. This initial model is typically just a constant value, set as the minimum of the loss function for all training inputs:
For the MSE loss, this is simply the mean of the target values. Keep in mind, again, that this is usually not the case for other loss functions.
Also, you will notice that in the below examples, I won’t always use the loss minimizing constant(s) to start the algorithm. While this might yield slightly worse results, it leads to less verbose code. If you want to replicate the results, you might therefore want to use the acatual loss minimizing constant(s).
The algorithm in summary
To summarize, the algorithm for Gradient Boosting is as follows:
- Initialize the ensemble with a constant value
- For each round
:
- Calculate the negative gradients with respect to the previous round’s model output
- Fit a base learner to the negative gradients
- Update the ensemble by performing a gradient descent step in function space
Gradient Boosting for conditional probability distributions
If you come from a Statistics background, you might be saddened by the lack of libraries for probabilistic Gradient Boosting. Despite the countless probability distributions that could well suit your data, you are usually limited to Bernoulli/Multinomial distributions via cross-entropy losses.
Thus, without further ado, let’s see how PyTorch can solve this problem for us. While we will implement the algorithm for a Gaussian distribution, it should be fairly easy to extend it to other distributions. The most characteristic feature here is that we need a Boosting model for each of the distribution’s parameters. In the Gaussian case, this means two models for the mean and standard deviation, respectively. Let us exemplify this by writing our full model as a stacked vector of two models:
In addition, we also need to ensure that the parameters are valid, i.e. positive for the standard deviation. Thus, we also have to map the output of the corresponding Gradient Boosting model to the positive, non-zero reals. This can be done, for example, via the -function.
For a single input , the full probabilistic description is now the following:
As usual for probabilistic models, we will use the negative log-likelihood as our loss function:
To initialize the model, we can use the maximum likelihood estimates for the mean and standard deviation:
and
Finally, we calculate the logarithm of to account for the exponentiation in the loss function. Keep in mind that the latter is not necessarily the optimtal initialization. However, it is a good starting point for our experiments.
We can now code our model as follows:
Let’s take look at some important code fragments. In particular, the steps in fit are interesting to us:
At first, self._fit_initial(y) initializes the model via the mean and log-standard deviation as described above. Next, we iterate over the number of rounds, as defined by the n_estimators variable. The _predict_raw method calculates the models’ outputs at , then we pass the results to
_get_gradients. In the latter, we then use PyTorch to differentiate the log-likelihood loss with respect to each output. Lucky for us, PyTorch already has the required log-likelihood function available via log_prob:
y_torch = torch.tensor(y).float()
y_pred_torch = Variable(torch.tensor(y_pred).float(), requires_grad=True)
normal_dist = Normal(y_pred_torch[:,0], torch.exp(y_pred_torch[:,1])).log_prob(y_torch).sum()
normal_dist.backward()
return y_pred_torch.grad.numpy()Notice that PyTorch requires a single scalar value as the final loss. Hence we need to sum the log-likelihoods for each input. It is easy to check that the respective derivatives are still as expected:
where denotes the index of the input
for which we want to calculate the derivative.
In a last step, we fit two sklearn.tree.DecisionTreeRegressor to the negative gradients. Since log_prob returns the positive (=“negative negative”) log-likelihood, the respective gradients will already have the correct signs.
Now, let us test our model on a simple toy problem. We define the data generating process as follows:
is uniformly distributed between -3 and 3, while
is normally distributed with a mean of
and a standard deviation of
. This makes the data heteroscedastic, i.e. the variance depends on the input
. As useful model should be able to capture both the conditional mean and standard deviation.
np.random.seed(123)
X = np.random.uniform(-3, 3, 1000).reshape(-1,1)
y = np.sin(X).reshape(-1) + np.random.normal(0, 1, 1000) * (0.05 + 0.1 * X.reshape(-1)**2)
plt.figure(figsize=(12,6))
plt.scatter(X, y, s=1)
model = GaussianGradientBoosting(n_estimators=200)
model.fit(X, y)
line = np.linspace(-3, 3, 1000).reshape(-1,1)
predictions = model.predict(line)
mean = predictions[:,0]
std = predictions[:,1]
plt.figure(figsize=(12,6))
plt.plot(line, np.sin(line), c='r')
plt.plot(line, mean, c='b')
plt.fill_between(line.reshape(-1), mean - 2*std, mean + 2*std, color='b', alpha=0.2)
plt.scatter(X, y, s=1)
This looks pretty good! We can see that the model is able to capture both the conditional mean and standard deviation. In particular, the model is able to capture the increasing variance for larger absolute .
From here, it would be relatively easy to extend the model to other distributions. We could, for example experiment with Gamma or Log-Normal distributions to handle target values that can only be positive. More advanced models could also incorporate censoring or truncation. As long as the respective log-likelihood loss is differentiable with respect to the model output, we will be able to optimize our model.
Varying Coefficient Boosting
A fairly common problem of many sophisticated machine learning models is that they are often a black-box. While predictive power can be much better than with simpler models, it is often hard to interpret the results. Hence, a model could make biased, unfair or physically wrong predictions without us even noticing. As a result, there is a growing interest in models that are more interpretable.
One such model is Varying Coefficient Regression. Here, we assume that the coefficients of a linear regression model are not constant but rather depend on the input. In the context of Gradient Boosting, this could look as follows:
Here, we have Boosting models, one for each coefficient in a linear regression model. In a sufficiently small neighborhood around
, the model can then be interpreted as a linear regression model with coefficients defined by the boosting model. Once we move outside of this neighborhood, the coefficients change accordingly.
Applying the squared error criterion to our Varying Coefficient model above, we now get
Again, we can let PyTorch differentiate the above with respect to each Gradient Boosting output. To initialize the model, we could, for example, start with the (constant) OLS regression coefficient. This would be the “correct” approach, given that we typically want to start with the constant minimizer of the mean loss function over all training points. Here, however, I decided to set and the remaining coefficients to zero.
Putting all of this together, we get the following model in Python:
class VaryingCoefficientGradientBoosting:
def __init__(self,
learning_rate: float = 0.025,
max_depth: int = 1,
n_estimators: int =100):
self.learning_rate: float = learning_rate
self.max_depth: int = max_depth
self.n_estimators: int = n_estimators
self.init_coeffs: Optional[float] = None
self.coeff_trees: List[List[DecisionTreeRegressor]] = []
self.is_trained: bool = False
@property
def n_coefficients(self) -> int:
if self.is_trained:
return self.init_coeffs.shape[1]
else:
return 0
def predict(self, X: np.array) -> np.array:
assert self.is_trained
X = np.concatenate([np.ones(shape = (len(X), 1)), X], 1)
coeffs = self._predict_coeffs(X)
predictions = np.sum(X * coeffs, 1)
return predictions
def _predict_raw(self, X: np.array) -> np.array:
assert self.is_trained
return self._predict_coeffs(X)
def fit(self, X: np.array, y: np.array) -> None:
X = np.concatenate([np.ones(shape = (len(X), 1)), X], 1)
self._fit_initial(X, y)
self.is_trained = True
for _ in range(self.n_estimators):
y_pred = self._predict_raw(X)
gradients = self._get_gradients(X, y, y_pred)
new_trees = []
for c in range(self.n_coefficients):
coeff_tree = DecisionTreeRegressor(max_depth=self.max_depth)
coeff_tree.fit(X, gradients[:,c])
new_trees.append(coeff_tree)
self.coeff_trees.append(new_trees)
def _fit_initial(self, X: np.array, y: np.array) -> None:
assert not self.is_trained
self.init_coeffs = np.zeros(shape = (1, X.shape[1]))
self.init_coeffs[0,0] = np.mean(y)
def _get_gradients(self, X: np.array, y: np.array, y_pred: np.array) -> np.array:
X_torch = torch.tensor(X).float()
y_torch = torch.tensor(y).float()
y_pred_torch = Variable(torch.tensor(y_pred).float(), requires_grad=True)
sse = -0.5 * (y_torch-(X_torch * y_pred_torch).sum(1)).pow(2.0).sum() #negative sse to get negative gradient
sse.backward()
grads = y_pred_torch.grad.numpy()
grads[grads > np.quantile(grads, 0.95)] = np.quantile(grads, 0.95)
grads[grads < np.quantile(grads, 0.05)] = np.quantile(grads, 0.05)
return grads
def _predict_coeffs(self, X: np.array) -> np.array:
output = np.zeros(shape = (len(X), self.n_coefficients))
output += self.init_coeffs
for tree_list in self.coeff_trees:
for c in range(self.n_coefficients):
output[:,c] += self.learning_rate * tree_list[c].predict(X)
return outputThis closely resembles the code for the probabilistic model from before. A key difference, however, is the following:
X_torch = torch.tensor(X).float()
y_torch = torch.tensor(y).float()
y_pred_torch = Variable(torch.tensor(y_pred).float(), requires_grad=True)
mse = -0.5 * (y_torch-(X_torch * y_pred_torch).sum(1)).pow(2.0).sum()
mse.backward()
grads = y_pred_torch.grad.numpy()
grads[grads > np.quantile(grads, 0.95)] = np.quantile(grads, 0.95)
grads[grads < np.quantile(grads, 0.05)] = np.quantile(grads, 0.05)Here, we clip the gradients at the 5% and 95% quantiles. The reason for that is solely an empirical one. Keeping the raw gradients led to some fairly unstable results, i.e. the model loss would usually diverge to infinity. It might be interesting to see the theoretical reason for this, but for now, we will stick with the application side.
Notice also that we introduce the intercept term by prepending a column of ones to the input matrix:
def fit(self, X: np.array, y: np.array) -> None:
X = np.concatenate([np.ones(shape = (len(X), 1)), X], 1)
...def predict(self, X: np.array) -> np.array:
assert self.is_trained
X = np.concatenate([np.ones(shape = (len(X), 1)), X], 1)
...This allows us to treat the respective intercept Boosting model like the other ones. Subsequently, some calculations become a bit simpler.
Now, let us test the model on a simple toy problem. We define the data generating process as before, but keep the variance constant:
np.random.seed(123)
X = np.random.uniform(-3, 3, 1000).reshape(-1,1)
y = np.sin(X).reshape(-1) + np.random.normal(0, 0.25, 1000)
plt.figure(figsize=(10,5))
plt.scatter(X, y, s=1)
model = VaryingCoefficientGradientBoosting(n_estimators=250, learning_rate=0.025)
model.fit(X, y)
line = np.linspace(-3, 3, 1000).reshape(-1,1)
predictions = model.predict(line)
plt.figure(figsize=(10,5))
plt.plot(line, np.sin(line), c='r')
plt.plot(line, predictions, c='b')
plt.scatter(X, y, s=1)
Again, the results look reasonable. As our new model has a neat interpretability feature, let us also run the model on an actual dataset. Here, I chose the California Housing dataset from scikit-learn. The dataset contains information about housing prices in California in the 1990s. The goal is to predict the median house value in a given block based on the remaining features.
To make things more interesting, we will also compare the results against standard Gradient Boosting from sklearn. Keep in mind, though, that the evaluation process is really simple and should not be considered a proper benchmark.
housing = fetch_california_housing()
X = housing.data
y = housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
X_mean = np.mean(X_train, 0)
X_std = np.std(X_train, 0)
X_train = (X_train - X_mean) / X_std
X_test = (X_test - X_mean) / X_std
y_mean = np.mean(y_train)
y_std = np.std(y_train)
y_train = (y_train - y_mean) / y_std
y_test = (y_test - y_mean) / y_std
np.random.seed(123)
model = VaryingCoefficientGradientBoosting(n_estimators=100, max_depth=2, learning_rate = 0.1)
model.fit(X_train, y_train)
predictions_varcoeff = model.predict(X_test)
rmse_varcoeff = np.sqrt(np.mean((predictions_varcoeff - y_test)**2))
gb_model = GradientBoostingRegressor(n_estimators=100, max_depth=2, learning_rate = 0.1)
gb_model.fit(X_train, y_train)
predictions_gb = gb_model.predict(X_test)
rmse_gb = np.sqrt(np.mean((predictions_gb - y_test)**2))
print(f"RMSE for varying coefficient model: {rmse_varcoeff}")
print(f"RMSE for gradient boosting model: {rmse_gb}")RMSE for varying coefficient model: 0.4724723297379694
RMSE for gradient boosting model: 0.4893399365654721This looks great. For the given hyperparameters and data, our approach is able to keep up with standard Gradient Boosting. Now, let us take a look at the coefficients of our model for a given input:
X_eval = np.concatenate([np.ones(shape=(1,1)), X_test[0,:].reshape(1,-1)], axis=1)
#need to prepend the intercept column manually, since _predict_coeffs() expects it
importances = pd.Series(model._predict_coeffs(X_eval).reshape(-1), index=["Intercept"]+housing.feature_names)
importances.sort_values().plot(kind='bar', figsize=(12,8))
Besides the intercept, House Age and Median incomde appear to be the most important features for the given input. For another input observation, we get the following:
X_eval = np.concatenate([np.ones(shape=(1,1)), X_test[10,:].reshape(1,-1)], axis=1)
importances = pd.Series(model._predict_coeffs(X_eval).reshape(-1), index=["Intercept"]+housing.feature_names)
importances.sort_values().plot(kind='bar', figsize=(12,8))
Here, the intercept term has much more relevance. Also, latitude and longitude are now the most influential features.
It might be debatable whether the intercept term is actually sensible. Technically, removing all other coefficients and only keeping the intercept would result in standard Gradient Boosting. As the latter is already sufficiently powerful in itself, why use varying coefficients at all? On the other hand, removing the intercept entirely would result in a degenerate model for an all-zero input vector.
The only possible prediction without an intercept term would then be zero as well, which is not what we want either. Another solution would be to model the intercept term as a constant, not via a Gradient Boosting model. As this would make the code more verbose, I decided to not do it here.
Combining Deep Learning with Boosted Trees
If you are confident with your Calculus skills, our usage of PyTorch so far might seem rather unneccessary. After all, we could have just calculated the derivatives by hand, without requiring a full-blown framework like PyTorch. While this would require more manual work, it would also be more efficient computation-wise. For that reason, we will now look at an example, where manual differentiation is not a viable option if you want to maintain a healthy social life.
The idea is fairly simple: Use a Convolutional Neural Network but replace the elements of the last weight matrix with Gradient Boosting varying coefficients. As this could easily blow up model complexity (consider one Boosting model for each element in a matrix), we only work with a rather simple example. In fact, we’ll reduce the MNIST dataset to only 0s and 1s to get a binary classification problem. Also, we let the penultimate layer only have two neurons, to reduce the final weight matrix to size
The rest of the model is just a standard CNN with some arbitrary hyperparameters:
class ConvolutionalNetWithBoostedTrees:
def __init__(self,
learning_rate: float = 0.025,
max_depth: int = 1,
n_estimators: int = 100,
n_booster: int = 2):
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.fc1 = torch.nn.Linear(7*7*32, 100)
self.fc2 = torch.nn.Linear(100, n_booster)
self.learning_rate: float = learning_rate
self.max_depth: int = max_depth
self.n_estimators: int = n_estimators
self.boosted_trees: List[List[DecisionTreeRegressor]] = []
self.init_coeffs: np.array = np.zeros(shape = (1, n_booster))
self.is_trained: bool = False
self.n_booster = n_booster
def predict(self, X: np.array):
x = torch.tensor(X).float()
x = torch.nn.functional.relu(self.conv1(x))
x = torch.nn.functional.max_pool2d(x, 2)
x = torch.nn.functional.relu(self.conv2(x))
x = torch.nn.functional.max_pool2d(x, 2)
x = x.view(-1, 7*7*32)
x = torch.nn.functional.relu(self.fc1(x))
x = self.fc2(x).detach().numpy()
coeffs = self._predict_coeffs(X.reshape(-1, 28*28))
logits = np.sum(x * coeffs, 1)
#sigmoid
return np.exp(logits) / (1 + np.exp(logits))
def fit(self, X: np.array, y: np.array, batch_size: int = 500):
self.is_trained = True
for _ in range(self.n_estimators):
idx = np.random.choice(len(X), batch_size, replace=False)
X_batch = X[idx]
y_batch = y[idx]
self._fit_single_step(X_batch, y_batch)
def _fit_single_step(self, X: np.array, y: np.array):
X_2d = X.reshape(-1, 28*28)
coeffs = self._predict_coeffs(X_2d)
coeffs_var = Variable(torch.tensor(coeffs).float(), requires_grad=True)
x = torch.tensor(X).float()
y = torch.tensor(y).float()
x = torch.nn.functional.relu(self.conv1(x))
x = torch.nn.functional.max_pool2d(x, 2)
x = torch.nn.functional.relu(self.conv2(x))
x = torch.nn.functional.max_pool2d(x, 2)
x = x.view(-1, 7*7*32)
x = torch.nn.functional.relu(self.fc1(x))
x = self.fc2(x)
logit = (x * coeffs_var).sum(1)
loss = torch.nn.functional.binary_cross_entropy_with_logits(logit, y)
loss.backward()
coeff_grads = coeffs_var.grad.numpy()
self._update_booster(X_2d, -coeff_grads)
self._update_network()
def _update_network(self):
self.conv1.weight.data -= self.learning_rate * self.conv1.weight.grad
self.conv2.weight.data -= self.learning_rate * self.conv2.weight.grad
self.fc1.weight.data -= self.learning_rate * self.fc1.weight.grad
self.fc2.weight.data -= self.learning_rate * self.fc2.weight.grad
self.conv1.weight.grad.zero_()
self.conv2.weight.grad.zero_()
self.fc1.weight.grad.zero_()
self.fc2.weight.grad.zero_()
def _update_booster(self, X: np.array, y: np.array) -> None:
tree_list = []
for c in range(self.n_booster):
tree = DecisionTreeRegressor(max_depth=self.max_depth, min_samples_leaf=50)
tree.fit(X, y[:,c])
tree_list.append(tree)
self.boosted_trees.append(tree_list)
def _predict_coeffs(self, X: np.array) -> np.array:
output = np.zeros(shape = (len(X), self.n_booster))
output += self.init_coeffs
for tree_list in self.boosted_trees:
for c in range(self.n_booster):
output[:,c] += self.learning_rate * tree_list[c].predict(X)
return outputSince we do all calculations except gradient by hand, our model class does not inherit from torch.nn.Module here. Also, the fit methods are now slightly different from before, which is due to the additional parameters that we need to learn. For each layer that doesn’t use Gradient Boosting, we need to manually implement the gradient steps. Think of this like fitting depth-0 Decision Trees (constant predictions) to a constant target for any input.
I.e., our model consists of a parameter vector, that is comprised of many constant and two varying parameters. The latter are the ones we want to model with Boosted Trees:
At each gradient descent step, the constant parameters are updated as usual, while the varying parameters are updated via Gradient Boosting:
For clarity, our loss now also depends explicitly on the input , not only via
. The first
elements are then updated in
def _update_network(self):
self.conv1.weight.data -= self.learning_rate * self.conv1.weight.grad
self.conv2.weight.data -= self.learning_rate * self.conv2.weight.grad
self.fc1.weight.data -= self.learning_rate * self.fc1.weight.grad
self.fc2.weight.data -= self.learning_rate * self.fc2.weight.grad
self.conv1.weight.grad.zero_()
self.conv2.weight.grad.zero_()
self.fc1.weight.grad.zero_()
self.fc2.weight.grad.zero_()while the Boosting models are updated in
def _update_booster(self, X: np.array, y: np.array) -> None:
tree_list = []
for c in range(self.n_booster):
tree = DecisionTreeRegressor(max_depth=self.max_depth, min_samples_leaf=50)
tree.fit(X, y[:,c])
tree_list.append(tree)
self.boosted_trees.append(tree_list)As we are dealing with binary classification, we can use the Binary Cross-Entropy loss directly from PyTorch. Notice that we use the logits for the training steps, i.e. the network output before applying the sigmoid activation function.
To speed things up, we also allow for random batch sampling which effectively makes this a Stochastic Gradient Descent algorithm. This is not strictly necessary, but it makes the training process much faster, in particular for the Boosting models.
Now, let us test our model on the MNIST dataset:
import torchvision
mnist_train = torchvision.datasets.MNIST(root='./data', train=True, download=True)
mnist_test = torchvision.datasets.MNIST(root='./data', train=False, download=True)
X_train = mnist_train.data.numpy()
y_train = mnist_train.targets.numpy()
X_test = mnist_test.data.numpy()
y_test = mnist_test.targets.numpy()
X_train = X_train[(y_train == 0) | (y_train == 1)]
y_train = y_train[(y_train == 0) | (y_train == 1)]
X_test = X_test[(y_test == 0) | (y_test == 1)]
y_test = y_test[(y_test == 0) | (y_test == 1)]
X_train = X_train.reshape(-1, 1, 28, 28)
X_test = X_test.reshape(-1, 1, 28, 28)np.random.normal(123)
torch.manual_seed(123)
model = ConvolutionalNetWithBoostedTrees(n_estimators=50, max_depth=3, learning_rate = 0.001)
model.fit(X_train, y_train, batch_size=500)
#evaluate
y_pred = model.predict(X_test)
np.mean(np.round(y_pred) == y_test)0.992434988179669Although this is a toy problem, almost 100% test accuracy is good. We can have confidence that our approach works in principle. As some final shenanigans, let us also consider a measure of local feature importance, concerning the boosting models. For a given input, each pixel and all Decision Trees, we count how often the given pixel (=feature) is encountered in each split rule. Then we can plot the result in an image plot:
# get all features in each node from root to leaf that target_x traverses in target_tree
def get_features_in_path(target_tree, target_x):
nodes = []
node = 0
nodes.append(node)
while node != -1:
if target_x[target_tree.tree_.feature[node]] < target_tree.tree_.threshold[node]:
node = target_tree.tree_.children_left[node]
else:
node = target_tree.tree_.children_right[node]
nodes.append(node)
#get all features in each node from root to leaf
feature_importances = np.zeros(28*28)
for node in nodes:
if node != -1:
target_feature = target_tree.tree_.feature[node]
if target_feature > -1:
feature_importances[target_feature] += 1
return feature_importances.reshape(28,28)
target_x = X_test[0].reshape(-1)
feature_importance = np.zeros(shape = (28,28))
for tree_list in model.boosted_trees:
for tree in tree_list:
feature_importance += get_features_in_path(tree, target_x)
plt.imshow(target_x.reshape(28,28), cmap='gray')
plt.imshow(feature_importance, cmap='Greens', alpha=0.85)
target_x = X_test[1].reshape(-1)
feature_importance = np.zeros(shape = (28,28))
for tree_list in model.boosted_trees:
for tree in tree_list:
feature_importance += get_features_in_path(tree, target_x)
plt.imshow(target_x.reshape(28,28), cmap='gray')
plt.imshow(feature_importance, cmap='Greens', alpha=0.85)
This could be interpreted as follows: The primary region of interest is around the center of the image (the deep green dots). 1s are mostly colored around there, while 0s will usually be blank around the center. In the bottom case of the 0, we see also some light regions at the left and right edges of the digit being of interest.
Keep in mind that this is just a freestyled measure of feature importance. We don’t even consider the remaining CNN parts of our model which is clearly insufficient. On the other hand, the output looks still reasonable and gives us at least some idea of what the model is doing.
In addition, larger or actual RGB images will likely be much harder to get right with this kind of model in general. Nevertheless, we have created a Gradient Boosting model where using PyTorch is actually a life-saver.
Conclusion
As we have seen, marrying Gradient Boosting with PyTorch can be a useful approach. Although manual derivatives will be faster, PyTorch allows us to handle arbitrarily complex models holistically. Since Gradient Boosting is generally a very powerful model, this might create opportunity to improve existing approaches that usually don’t include a Boosting component.
This also comes with a slight improvement for interpretability, as tree based methods provide at least some insight into a model’s inner workings. In one of the next articles, we’ll take a look how this all can also be used for time series models.
References
[1] Friedman, Jerome H. Greedy function approximation: A gradient boosting machine. Annals of statistics, 2001
[2] Hastie, Trevor; Tishbirani, Robert. Varying-coefficient models. Journal of the Royal Statistical Society Series B: Statistical Methodology, 1993
[2] Paszke, Adam, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 2019
Introduction
Last time, amongst other ideas, we looked at how to implement Varying Coefficient Boosting in PyTorch. These types of models are quite useful, as they are considerably flexible and (locally) interpretable at the same time.
By using Boosted Decision Trees, we even gain some interpretability for the coefficient functions themselves. The well-known predictive performance of Gradient Boosting also seems to apply for such models. Personally, I believe that these two aspects makes Gradient Boosting with Decision Trees the preferred base-method for the Varying Coefficient approach.
Today, we will look at how to apply this approach to geospatial data and data with a prevalent temporal component. Our main goal is to let the coefficients vary over space and/or time. This should improve interpretability even further - the model coefficients will only change per region or per time period. Especially for geospatial data, we can then make some neat geo-plots to visualize the results.
Adapting the Varying Coefficient model from before
If you take a close look at the previous implementation of Varying Coefficient Boosting, you will notice one important aspect: Our model presumed that the coefficient function features and the regression features are equivalent. I.e., in the model formula
we could not allow the in
to be different from the
in
. Now, however, input vector
is presumed to contain, for example,
and
or
and
. We therefore only want those features to be used in the
. For the actual regressors, we will use the remaining features,
.
Thus, we introduce X_reg and X_coeff in the .fit and .predict methods to differentiate both feature sets. Adjusting the existing model class is then fairly straightforward:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.preprocessing import StandardScaler
import json
import torch
from torch.autograd import Variable
import torch.optim as optim
import torch.nn as nn
from typing import List, Optional, Union
###Model
class VaryingCoefficientGradientBoosting:
def __init__(self,
learning_rate: float = 0.025,
max_depth: int = 1,
n_estimators: int =100):
self.learning_rate: float = learning_rate
self.max_depth: int = max_depth
self.n_estimators: int = n_estimators
self.init_coeffs: Optional[float] = None
self.coeff_trees: List[List[DecisionTreeRegressor]] = []
self.is_trained: bool = False
@property
def n_coefficients(self) -> int:
if self.is_trained:
return self.init_coeffs.shape[1]
else:
return 0
def predict(self, X_reg: np.array, X_coeff: np.array) -> np.array:
assert self.is_trained
X_reg = np.concatenate([np.ones(shape = (len(X_reg), 1)), X_reg], 1)
coeffs = self._predict_coeffs(X_coeff)
predictions = np.sum(X_reg * coeffs, 1)
return predictions
def _predict_raw(self, X_coeff: np.array) -> np.array:
assert self.is_trained
return self._predict_coeffs(X_coeff)
def fit(self, X_reg: np.array, X_coeff: np.array, y: np.array) -> None:
X_reg = np.concatenate([np.ones(shape = (len(X_reg), 1)), X_reg], 1)
self._fit_initial(X_reg, y)
self.is_trained = True
for _ in range(self.n_estimators):
coeff_pred = self._predict_raw(X_coeff)
gradients = self._get_gradients(X_reg, y, coeff_pred)
new_trees = []
for c in range(self.n_coefficients):
coeff_tree = DecisionTreeRegressor(max_depth=self.max_depth)
coeff_tree.fit(X_coeff, gradients[:,c])
new_trees.append(coeff_tree)
self.coeff_trees.append(new_trees)
def _fit_initial(self, X_reg: np.array, y: np.array) -> None:
assert not self.is_trained
self.init_coeffs = np.zeros(shape = (1, X_reg.shape[1]))
self.init_coeffs[0,0] = np.mean(y)
def _get_gradients(self, X_reg: np.array, y: np.array, coeff_pred: np.array) -> np.array:
X_torch = torch.tensor(X_reg).float()
y_torch = torch.tensor(y).float()
y_pred_torch = Variable(torch.tensor(coeff_pred).float(), requires_grad=True)
sse = -0.5 * (y_torch-(X_torch * y_pred_torch).sum(1)).pow(2.0).sum() #negative sse to get negative gradient
sse.backward()
grads = y_pred_torch.grad.numpy()
grads[grads > np.quantile(grads, 0.95)] = np.quantile(grads, 0.95)
grads[grads < np.quantile(grads, 0.05)] = np.quantile(grads, 0.05)
return grads
def _predict_coeffs(self, X_coeff: np.array) -> np.array:
output = np.zeros(shape = (len(X_coeff), self.n_coefficients))
output += self.init_coeffs
for tree_list in self.coeff_trees:
for c in range(self.n_coefficients):
output[:,c] += self.learning_rate * tree_list[c].predict(X_coeff)
return outputNot too difficult. Next, we can directly apply this updated model to the California Housing dataset.
Varying Coefficient Boosting for California Housing
To accomodate for our updated model, we obviously need to split our features into X_reg and X_coeff, too. Since we also want to keep using train_test_split from sklearn, which expects only one feature matrix, we apply the latter first. Also, for comparison, we will fit a regular Gradient Boosting model to the data. This requires another set of features, namely X_train_scaled and X_test_scaled where we use the full feature set for the standard Boosting model:
### Data
housing = fetch_california_housing()
X = housing.data
y = housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
X_train_reg = X_train[:, :-2]
X_train_coeff = X_train[:, -2:]
X_test_reg = X_test[:, :-2]
X_test_coeff = X_test[:, -2:]
X_reg_mean = np.mean(X_train_reg, 0)
X_reg_std = np.std(X_train_reg, 0)
X_train_reg = (X_train_reg - X_reg_mean) / X_reg_std
X_test_reg = (X_test_reg - X_reg_mean) / X_reg_std
X_full_mean = np.mean(X_train, 0)
X_full_std = np.std(X_train, 0)
X_train_scaled = (X_train - X_full_mean) / X_full_std
X_test_scaled = (X_test - X_full_mean) / X_full_std
y_mean = np.mean(y_train)
y_std = np.std(y_train)
y_train = (y_train - y_mean) / y_std
y_test = (y_test - y_mean) / y_std
### Models
np.random.seed(123)
model = VaryingCoefficientGradientBoosting(n_estimators=100, max_depth=2, learning_rate = 0.1)
model.fit(X_train_reg, X_train_coeff, y_train)
predictions_varcoeff = model.predict(X_test_reg, X_test_coeff)
rmse_varcoeff = np.sqrt(np.mean((predictions_varcoeff - y_test)**2))
gb_model = GradientBoostingRegressor(n_estimators=100, max_depth=2, learning_rate = 0.1)
gb_model.fit(X_train_scaled, y_train)
predictions_gb = gb_model.predict(X_test_scaled)
rmse_gb = np.sqrt(np.mean((predictions_gb - y_test)**2))For further comparison, we also fit a Varying Coefficient Neural Network. As with Varying Coefficient Boosting, the geographical features are used for the coefficient functions, while the remaining ones are used as regressors. The model is implemented in PyTorch, using the nn module. The model is fairly simple, with only one hidden layer:
class VaryingCoefficientNeuralNetwork(nn.Module):
def __init__(self, input_dim, varying_input_dim, hidden_dim):
super(VaryingCoefficientNeuralNetwork, self).__init__()
self.input_dim = input_dim
self.varying_input_dim = varying_input_dim
self.hidden_dim = hidden_dim
self.fc1 = nn.Linear(varying_input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, input_dim+1)
def forward(self, x, x_varying):
varying_coeffs = self.fc3(torch.relu(self.fc2(torch.relu(self.fc1(x_varying)))))
x_with_ones = torch.cat([torch.ones(x.shape[0], 1), x], 1)
result = torch.sum(x_with_ones * varying_coeffs, 1)
return result
def predict_coefficients(self, x_varying):
varying_coeffs = self.fc2(nn.Softplus()(self.fc1(x_varying)))
return varying_coeffs
np.random.seed(123)
torch.manual_seed(123)
model_net = VaryingCoefficientNeuralNetwork(input_dim=X_train_reg.shape[1]+1, varying_input_dim=X_train_coeff.shape[1], hidden_dim=10)
criterion = nn.MSELoss()
optimizer = optim.Adam(model_net.parameters(), lr=0.001)
X_train_reg_tensor = torch.tensor(X_train_reg).float()
X_train_reg_tensor = torch.cat([torch.ones(X_train_reg_tensor.shape[0], 1), X_train_reg_tensor], 1)
X_test_reg_tensor = torch.tensor(X_test_reg).float()
X_test_reg_tensor = torch.cat([torch.ones(X_test_reg_tensor.shape[0], 1), X_test_reg_tensor], 1)
X_train_coeff_tensor = torch.tensor(X_train_coeff).float()
X_test_coeff_tensor = torch.tensor(X_test_coeff).float()
y_train_tensor = torch.tensor(y_train).float()
num_epochs = 5000
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model_net(X_train_reg_tensor, X_train_coeff_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
predictions = model_net(X_test_reg_tensor, X_test_coeff_tensor)
rmse_var_coeff_net = np.sqrt(np.mean((predictions.detach().numpy() - y_test)**2))
print(f"RMSE for Varying Coefficient Boosting: {rmse_varcoeff}")
print(f"RMSE for Gradient Boosting: {rmse_gb}")
print(f"RMSE for varying coefficient Neural Network: {rmse_var_coeff_net}")RMSE for Varying Coefficient Boosting: 0.5317705220008321
RMSE for Gradient Boosting: 0.4893399365654721
RMSE for varying coefficient Neural Network: 0.6654126590680458By giving up a minor amount of accuracy, we can get a model that is much more interpretable. Now, we can visualize the coefficients on a map:
# Define the range of latitude and longitude
lat_range = np.linspace(np.min(X_train_coeff[:, 0]), np.max(X_train_coeff[:, 0]), 100)
lon_range = np.linspace(np.min(X_train_coeff[:, 1]), np.max(X_train_coeff[:, 1]), 100)
# Create the meshgrid
lat_mesh, lon_mesh = np.meshgrid(lat_range, lon_range)
# Flatten the meshgrid
lat_lon_mesh = np.concatenate([lat_mesh.reshape(-1, 1), lon_mesh.reshape(-1, 1)], 1)
# Predict using the model
predictions = model._predict_coeffs(lat_lon_mesh)[:,1]
# Create a basemap
m = Basemap(llcrnrlon=np.min(X_train_coeff[:, 1]), llcrnrlat=np.min(X_train_coeff[:, 0]),
urcrnrlon=np.max(X_train_coeff[:, 1]), urcrnrlat=np.max(X_train_coeff[:, 0]),
projection='lcc', lat_0=np.mean(X_train_coeff[:, 0]), lon_0=np.mean(X_train_coeff[:, 1]))
# Create a contour plot
plt.figure(figsize=(15, 15))
m.contourf(lon_mesh, lat_mesh, predictions.reshape(lat_mesh.shape), cmap='coolwarm',latlon=True, levels=200)
plt.colorbar(label='Predictions')
m.scatter(X[:, -1], X[:, -2], latlon=True, c=y, s=2)
m.drawcoastlines()
m.drawstates()
m.drawcountries()
plt.title('MedianIncome Coefficient (standardized)')
plt.show()
We see that the effect of MedInc is relatively stable throughout the many areas. In some coastal regions, particularly around Los Angeles and southern San Franscico/Palo Alto, the effect of Median Income is slightly higher. Compare this to the estimated, varying coefficient according to the Varying Coefficient Neural Network:
# Predict using the model
predictions = model_net.predict_coefficients(torch.tensor(lat_lon_mesh).float())[:,1].detach().numpy()
# Create a basemap
m = Basemap(llcrnrlon=np.min(X_train_coeff[:, 1]), llcrnrlat=np.min(X_train_coeff[:, 0]),
urcrnrlon=np.max(X_train_coeff[:, 1]), urcrnrlat=np.max(X_train_coeff[:, 0]),
projection='lcc', lat_0=np.mean(X_train_coeff[:, 0]), lon_0=np.mean(X_train_coeff[:, 1]))
# Create a contour plot
plt.figure(figsize=(15, 15))
m.contourf(lon_mesh, lat_mesh, predictions.reshape(lat_mesh.shape), cmap='coolwarm',latlon=True, levels=200)
plt.colorbar(label='Predictions')
m.scatter(X[:, -1], X[:, -2], latlon=True, c=y, s=2)
m.drawcoastlines()
m.drawstates()
m.drawcountries()
plt.title('MedianIncome Coefficient (standardized; Neural Network estimate)')
plt.show()
With the Varying Coefficient Neural Network, the coefficient variation is much different from before. Instead of rectangular areas, the coefficients are now varying much more smoothly. This is obviously due to Neural Networks only being able to model smooth functions. Boosted Trees on the the other hand can also account for non-smooth functions that change rapidly within a small area. With regards to geospatial data, this can obviously be limiting - here, for example, if neighborhood conditions change rather rapdidly.
Nevertheless, the model also accounts for coastal homes’ prices being more influenced by Median Income.
Varying Coefficient Boosting for Bike Sharing Demand
Next up, we take a look at the Bike Sharing Demand dataset from Kaggle. The dataset contains hourly bike rental data from Washington D.C. Month, weekday and hour are obviously key features here. Thus,
bike_sharing = fetch_openml("Bike_Sharing_Demand", version=2, as_frame=True)
df = bike_sharing.frame
X = df.iloc[:,2:-1]
X["time"] = np.arange(len(X)) #add time axis for linear trend
y = df.iloc[:,-1]
X["month_sin"] = np.sin(2 * np.pi * X["month"] / 12)
X["month_cos"] = np.cos(2 * np.pi * X["month"] / 12)
X["hour_sin"] = np.sin(2 * np.pi * X["hour"] / 24)
X["hour_cos"] = np.cos(2 * np.pi * X["hour"] / 24)
X["weekday_sin"] = np.sin(2 * np.pi * X["weekday"] / 7)
X["weekday_cos"] = np.cos(2 * np.pi * X["weekday"] / 7)
X.drop(["month", "hour", "weekday"], axis=1, inplace=True)
# Create dummy variables for the specified columns
dummy_cols = ["holiday", "workingday", "weather"]
dummy_df = pd.get_dummies(X[dummy_cols], drop_first=True)
# Concatenate the dummy variables with the remaining columns
X = pd.concat([X.drop(dummy_cols, axis=1), dummy_df], axis=1)
X_train = X.iloc[:-1000]
X_test = X.iloc[-1000:]
y_train = np.log(y.iloc[:-1000]+1)
y_test = np.log(y.iloc[-1000:]+1)
data_features = ["weather_heavy_rain", "weather_misty", "weather_rain", "temp", "feel_temp", "humidity", "windspeed", "time", "holiday_False", "workingday_False"]
X_train_reg = np.float32(X_train[data_features])
X_train_coeff = np.float32(X_train.drop(data_features, axis=1))
X_test_reg = np.float32(X_test[data_features])
X_test_coeff = np.float32(X_test.drop(data_features, axis=1))
X_reg_mean = np.mean(X_train_reg, 0)
X_reg_std = np.std(X_train_reg, 0)
X_train_reg = (X_train_reg - X_reg_mean) / X_reg_std
X_test_reg = (X_test_reg - X_reg_mean) / X_reg_std
X_full_mean = np.mean(X_train, 0)
X_full_std = np.std(X_train, 0)
X_train_scaled = (X_train - X_full_mean) / X_full_std
X_test_scaled = (X_test - X_full_mean) / X_full_std
y_mean = np.mean(y_train)
y_std = np.std(y_train)
y_train = (y_train - y_mean) / y_std
y_test = (y_test - y_mean) / y_std
np.random.seed(123)
model = VaryingCoefficientGradientBoosting(n_estimators=100, max_depth=2, learning_rate = 0.1)
model.fit(X_train_reg, X_train_coeff, y_train)
predictions_varcoeff = model.predict(X_test_reg, X_test_coeff)
rmse_varcoeff = np.sqrt(np.mean((predictions_varcoeff - y_test)**2))
gb_model = GradientBoostingRegressor(n_estimators=100, max_depth=2, learning_rate = 0.1)
gb_model.fit(X_train_scaled, y_train)
predictions_gb = gb_model.predict(X_test_scaled)
rmse_gb = np.sqrt(np.mean((predictions_gb - y_test)**2))np.random.seed(123)
torch.manual_seed(123)
model_net = VaryingCoefficientNeuralNetwork(input_dim=X_train_reg.shape[1], varying_input_dim=X_train_coeff.shape[1], hidden_dim=10)
criterion = nn.MSELoss()
optimizer = optim.Adam(model_net.parameters(), lr=0.001)
model_net = VaryingCoefficientNeuralNetwork(input_dim=X_train_reg.shape[1]+1, varying_input_dim=X_train_coeff.shape[1], hidden_dim=10)
criterion = nn.MSELoss()
optimizer = optim.Adam(model_net.parameters(), lr=0.001)
X_train_reg_tensor = torch.tensor(X_train_reg).float()
X_train_reg_tensor = torch.cat([torch.ones(X_train_reg_tensor.shape[0], 1), X_train_reg_tensor], 1)
X_test_reg_tensor = torch.tensor(X_test_reg).float()
X_test_reg_tensor = torch.cat([torch.ones(X_test_reg_tensor.shape[0], 1), X_test_reg_tensor], 1)
X_train_coeff_tensor = torch.tensor(X_train_coeff).float()
X_test_coeff_tensor = torch.tensor(X_test_coeff).float()
y_train_tensor = torch.tensor(y_train).float()
num_epochs = 5000
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model_net(X_train_reg_tensor, X_train_coeff_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
predictions = model_net(X_test_reg_tensor, X_test_coeff_tensor)
rmse_var_coeff_net = np.sqrt(np.mean((predictions.detach().numpy() - y_test)**2))
print(f"RMSE for Varying Coefficient Boosting: {rmse_varcoeff}")
print(f"RMSE for Gradient Boosting: {rmse_gb}")
print(f"RMSE for varying coefficient Neural Network: {rmse_var_coeff_net}")RMSE for Varying Coefficient Boosting: 0.4491864065123828
RMSE for Gradient Boosting: 0.4917861604236747
RMSE for varying coefficient Neural Network: 0.4621447551672892This time, the Varying Coefficient Boosting model even outperforms the standard Gradient Boosting model. Let us now compare how the Varying Coefficient Boosting model and the Varying Coefficient Neural Network model estimate the coefficient for the temp feature:
result_dict = {}
index = []
datalist = []
for hour in range(24):
for month in range(12):
for weekday in range(7):
datalist.append([
np.sin(2 * np.pi * hour / 24),
np.cos(2 * np.pi * hour / 24),
np.sin(2 * np.pi * month / 12),
np.cos(2 * np.pi * month / 12),
np.sin(2 * np.pi * weekday / 7),
np.cos(2 * np.pi * weekday / 7),
])
index.append(f"{hour+1},{month+1},{weekday+1}")
predictions_vcb = model._predict_coeffs(np.array(datalist))
predictions_vcnn = model_net.predict_coefficients(torch.tensor(np.array(datalist)).float()).detach().numpy()
for i in range(len(predictions)):
result_dict[index[i]] = {"vcb": f"{predictions_vcb[i,0]:.4f} + ... + {predictions_vcb[i,4]:.4f} * temp + ...",
"vcnn": f"{predictions_vcnn[i,0]:.4f} + ... + {predictions_vcnn[i,4]:.4f} * temp + ..."}
result_dict_json = json.dumps(result_dict)
html_template = f"""
<!DOCTYPE html>
<html>
<head>
<title>Model Selector</title>
</head>
<body>
<div style="text-align:center;">
<label for="hour">Hour:</label>
<input type="range" id="hour" name="hour" min="1" max="24" value="12" oninput="updateModel()">
<span id="hourValue">12</span><br>
<label for="month">Month:</label>
<input type="range" id="month" name="month" min="1" max="12" value="8" oninput="updateModel()">
<span id="monthValue">6</span><br>
<label for="weekday">Weekday:</label>
<input type="range" id="weekday" name="weekday" min="1" max="7" value="3" oninput="updateModel()">
<span id="weekdayValue">3</span><br>
<p>Varying Coefficient Boosting: <span id="vcbOutput"></span></p>
<p>Varying Coefficient Neural Network: <span id="vcnnOutput"></span></p>
</div>
<script>
var modelData = {result_dict_json};
function updateModel() {{
var hour = document.getElementById('hour').value;
var month = document.getElementById('month').value;
var weekday = document.getElementById('weekday').value;
document.getElementById('hourValue').textContent = hour;
document.getElementById('monthValue').textContent = month;
document.getElementById('weekdayValue').textContent = weekday;
var vcbModelString = modelData[hour + ',' + month + ',' + weekday]['vcb'];
document.getElementById('vcbOutput').textContent = vcbModelString || 'No model available';
var vcnnModelString = modelData[hour + ',' + month + ',' + weekday]['vcnn'];
document.getElementById('vcnnOutput').textContent = vcnnModelString || 'No model available';
}}
// Initial update
updateModel();
</script>
</body>
</html>
"""
with open('interactive_model_selector.html', 'w') as f:
f.write(html_template)We find that the Varying Coefficient Network predict a negative temp coefficient at hour=12, month=8, weekday=3. On the contrary, the Varying Coefficient Boosting model appears to mostly predict a positive coefficient. This might be a good occassion to ask a domain expert for their opinion. Then, we could fine-tune the varying coefficients by, for example, requiring the coefficient to be either all-negative or all-positive.
References
[1] Hastie, Trevor; Tishbirani, Robert. Varying-coefficient models. Journal of the Royal Statistical Society Series B: Statistical Methodology, 1993
[2] Yue, Mu; LI, Jialiang; Cheng, Ming-Yen. Two-step sparse boosting for high-dimensional longitudinal data with varying coefficients. Computational Statistics & Data Analysis, 2019
[3] Zhou, Yichen; Hooker, Giles. Decision tree boosted varying coefficient models. Data Mining and Knowledge Discovery, 2022
Introduction
Disclaimer: Title heavily inspired by this great talk.
As the name implies, today we want to consider almost trivially simple models. Although the current trend points towards complex models, even for time-series models, I am still a big believer in simplicity. In particular, when your dataset is small, the subsequent ideas might be useful.
To be fair, this article will probably be most valuable for people who are just starting out with time-series analysis. Anyone else should check the table of contents first and decide for themselves if they want to continue.
Personally, I am still quite intrigued by how far you can push even the most simplistic time-series models. The upcoming paragraphs show some ideas and thoughts that I have been gathering on the topic over time.
Models with pure i.i.d. noise
We start with the simplest (probabilistic) way to model a (univariate) time-series. Namely, we want to look at plain independently, identically, distributed randomness: This implies that all our observations follow the same distribution at any point in time (identically distributed). Even more importantly, we presume no interrelation between observations at all (independently distributed). Obviously, this precludes any autoregressive terms as well.
Probably your first question is if such models aren’t too simplistic to be useful for real-world problems. Certainly, most time-series are unlikely to have no statistical relationship with their own past.
While those concerns are true by all means, we can nevertheless deduce the following:
Any time-series model that is more complex than a pure-noise model should also produce better forecasts than a pure-noise model.
In short, we can at least use random noise as a benchmark model. There is arguably no simpler approach to create baseline benchmarks than this one. Even smoothing techniques will likely require more parameters to be fitted.
Besides this rather obvious use-case, there is another potential application for i.i.d. noise. Due to their simplicity, noise models cand be useful for very small datasets. Consider this: If big, complex models require large datasets to prevent overfitting, then simple models require only a handful of data.
Of course, it is debatable what dataset size can be seen as ‘small’.
Integrated i.i.d. noise
Now, things are becoming more interesting. While raw i.i.d. noise cannot account for auto-correlation between observations, integrated noise can. Before we do a demonstration, let us introduce the differencing operator: If you haven’t heard about differencing for time-series problems yet - great! If you have, then you can hopefully still learn something new.
Definition of an integrated time-series
With the difference operator in our toolbox, we can now define an integrated time-series
A time-series
is said to be integrated of order
with seasonality
if
is a stationary time-series.
There are several ideas in this definition that we should clarify further:
First, you probably noticed the concept of exponentiating the difference operator. You can simply think of this as performing the differentiation several times. For the squared difference operator, this would look as follows: As we will see, multiple difference operators allow us to handle different time-series patterns at once.
Third, it is common convention to simply write We will happily adopt this convention here. Also, we call such time-series simply integrated without referencing its order or seasonality.
Obviously, we also need to re-transform a difference representation back to its original domain. In our notation, this means we invert the difference transformation, i.e. must hold for arbitrary difference transformations. If we expand this formula, we get
These simplifications follow from the fact the difference operator is a linear operator (we won’t cover the details here). Technically, the last equation merely says that the next observation is a sum of this observation plus a delta.
In a forecasting problem, we will typically have a prediction for the change Let’s denote this prediction as
to stress that it is not the actual change, but a predicted one. Thus, the forecast for the integrated time-series is
Afterwards, we apply this logic recursively as far into the future as our forecast should go:
Integrated noise for seemingly complex patterns
By now, you can probably imagine what is meant by an integrated noise model. In fact, we can come up with countless variants of an integrated noise model by just chaining some difference operators with random noise.
Linear trends from integrated time-series
One possibility would be a simply integrated time-series, i.e.
It is an interesting exercise to simulate data from such a model using a plain standard normal distribution.
As it turns out, samples from this time-series appear to exhibit linear trends with potential change points. However, it is clear that these trends and change points occur completely at random.
This implies that simply fitting piece-wise linear functions to forecast such trends can be a dangerous approach. After all, if the changes are occurring at random, then all linear trend lines are mere artifacts of the random data-generating process.
As an important disclaimer, though, ‘unpredictable’ means unpredictable from the time-series itself. An external feature might still be able to accurately forecast potential change points. Here, however, we presume that the time-series is our solely available source of information.
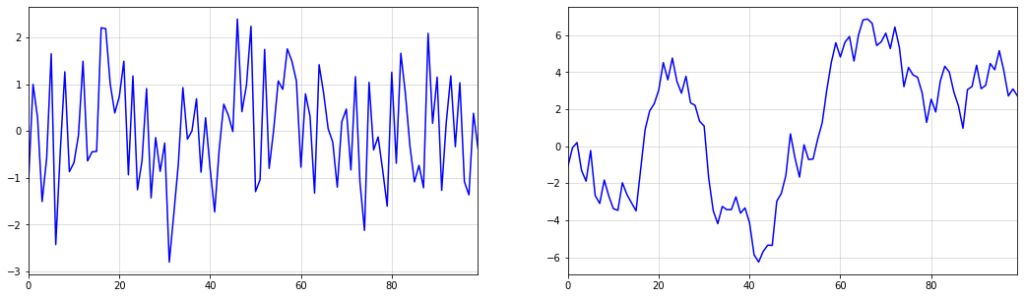
Below, you can see an example of the described phenomenon. While there appears to be a trend change at around t=50, this change is purely random. The upward trend after t=50 also stalls at around t=60. Imagine how your model would have performed if you extrapolated the upward trend after t=60.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(321)
plt.figure(figsize = (16,5))
plt.plot(np.cumsum(np.random.normal(size = 100)),color="blue")
plt.margins(x=0)
plt.grid(alpha=0.5);
Of course, the saying goes ‘never say never’, even in those settings. However, you should really know what you are doing if you apply such models.
Seasonal patterns
Similarly to how a simple integration produceds trends, we can also create seasonal patterns:
Formally, we now need the s-th difference of our seasonal process to be a stationary process, e.g. The inverse operation - transforming the i.i.d. process back to the seasonally integrated - works similarly to the one before:
You can think of the inverse operation of seasonal differencing as a cumsum operation over s periods. Since I am not aware of a respective, native Python function, I decided to do
reshape->cumsum->reshape to get the desired outcome. Below is an example with :
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(321)
white_noise = np.random.normal(size = (100))
seasonal_series = np.cumsum(white_noise.reshape((25,4)),0).reshape(-1)
plt.figure(figsize = (16,5))
plt.plot(seasonal_series,color="blue")
plt.margins(x=0)
plt.grid(alpha=0.5);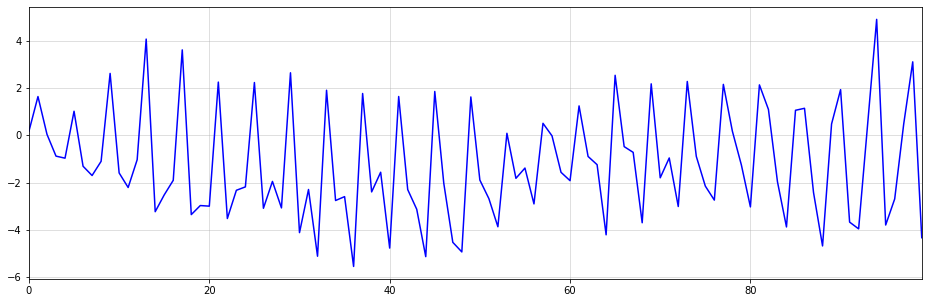
As you can see, the generated time-series looks reasonably realistic. We could easily sell this as quarterly sales numbers of some product to an unsuspecting Data Scientist.
We could even combine both types of integration to generate a seasonal time-series with trending behavior:
import matplotlib.pyplot as plt
np.random.seed(123)
white_noise = np.random.normal(size = (240))
integrated_series = np.cumsum(np.cumsum(white_noise.reshape((20,12)),0).reshape(-1))
plt.figure(figsize = (16,5))
plt.plot(integrated_series,color="blue")
plt.margins(x=0)
plt.grid(alpha=0.5);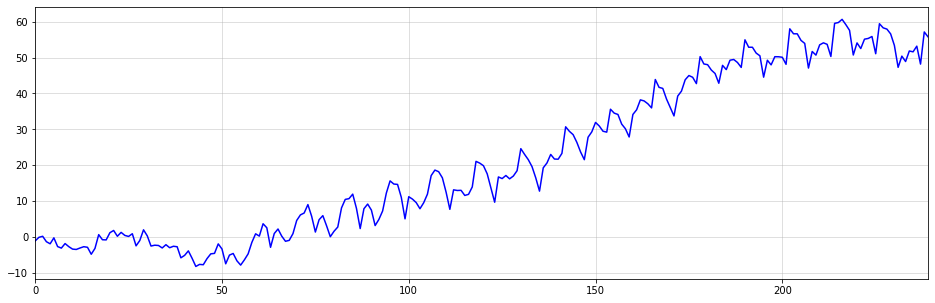
At this point, you will probably realize that the title of this article was a little click-baity. Integrated time-series are, in fact, purely linear models. However, I believe that most people wouldn’t consider a model with, more-or-less, zero parameters a typical linear model.
Memory effects through integration
Another interesting property of integrated time-series is the ability to model memory effects.
This effect can be seen particularly well when there are larger shocks or outliers in our data. Consider the below example, which shows seasonal integration of order over i.i.d. draws from a standard Cauchy distribution:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(987)
#cauchy distribution is equivalent to a Student-T with 1 degree of freedom
#see https://stats.stackexchange.com/questions/151854/a-normal-divided-by-the-sqrt-chi2s-s-gives-you-a-t-distribution-proof
heavy_tailed_noise = np.random.normal(size = (120))/np.sqrt(np.random.normal(size = (120))**2)
seasonal_series = np.cumsum(heavy_tailed_noise.reshape((10,12)),0).reshape(-1)
fig, axs = plt.subplots(figsize = (24,8), nrows=1, ncols=2)
axs[0].plot(heavy_tailed_noise,color="blue")
axs[0].margins(x=0)
axs[0].grid(alpha=0.5)
axs[1].plot(seasonal_series,color="blue")
axs[1].margins(x=0)
axs[1].grid(alpha=0.5);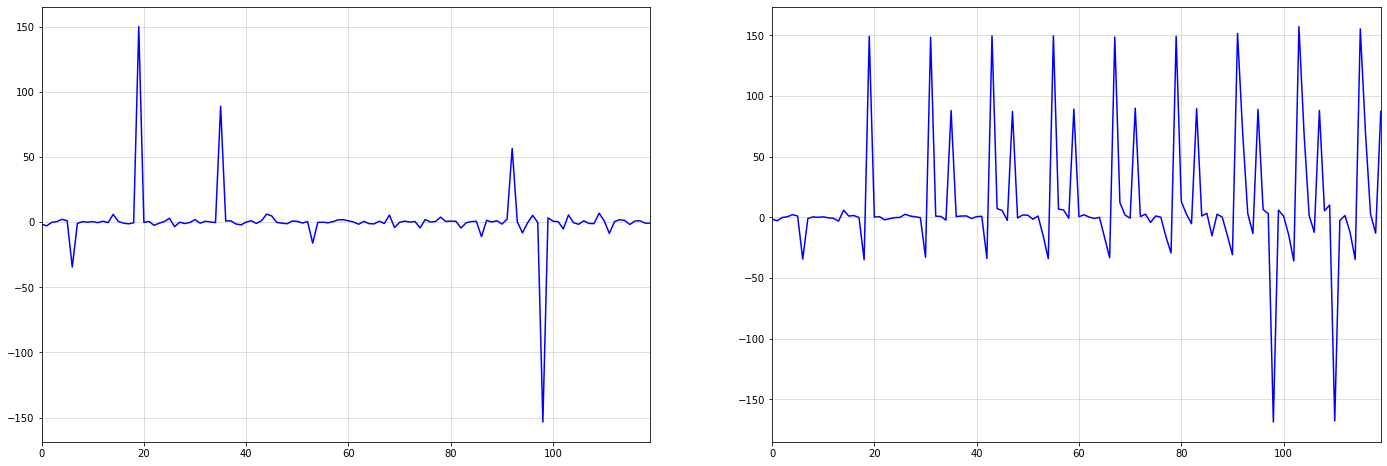
The first large shock in the i.i.d. Cauchy series at around t=20 is sustained over the whole integrated series on the right. Over time, more shocks occur, which are also sustained.
This memory property can be very useful in practice. For example, the economic shocks from the pandemic have caused persistent changes in many time-series.
Benchmarking against NBEATS and NHITS
Let us now use the AirPassengers dataset from Nixtla’s neuralforecast for a quick evaluation of the above ideas. If you are regularly reading my articles, you might remember the general procedure from this one.
First, we split the data into a train and test period, with the latter consisting of 36 months of data:
import pandas as pd
from neuralforecast.utils import AirPassengersDF
df = AirPassengersDF.iloc[:,1:]
df.columns = ["date","sales"]
df.index = pd.to_datetime(df["date"])
sales = df["sales"]
train = sales.iloc[:-36]
test = sales.iloc[-36:]
plt.figure(figsize = (16,8))
plt.plot(train,color="blue",label="Train")
plt.plot(test,color="red",label="Test")
plt.legend()
plt.margins(x=0)
plt.grid(alpha=0.5);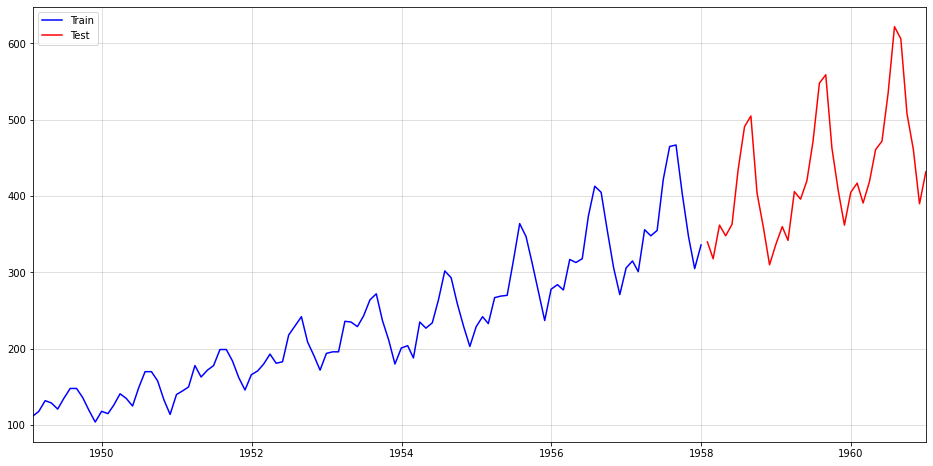
In order to obtain a stationary, i.i.d. series we perform the following transformation: First, the square-root stabilizes the increasing variance. The two differencing operators then remove seasonality and trend. For the respective re-transformation, check the code further down below.
rooted = np.sqrt(train)
diffed = rooted.diff(1)
diffed_s = diffed.diff(12).dropna()
plt.figure(figsize = (16,8))
plt.plot(diffed_s,color="blue",label="Train stationary")
plt.legend()
plt.margins(x=0)
plt.grid(alpha=0.5);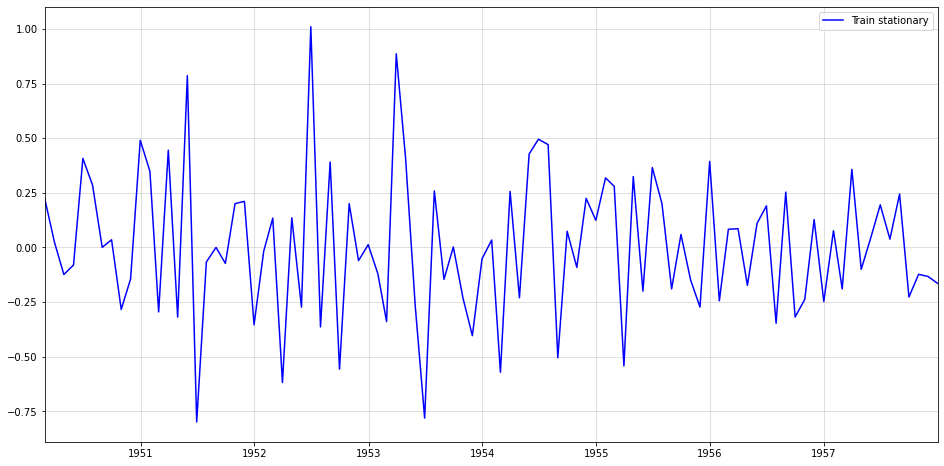
We can also check a histogram and density plot of the stabilized time-series:
from scipy.stats import gaussian_kde
plt.figure(figsize = (10,8))
plt.grid(alpha = 0.5)
plt.hist(diffed_s,bins=20,density = True,alpha=0.5, label = "Histogram of diffed time-series")
kde = gaussian_kde(diffed_s)
target_range = np.linspace(np.min(diffed_s)-0.5,np.max(diffed_s)+0.5,num=100)
plt.plot(target_range, kde.pdf(target_range),color="green",lw=3, label = "Gaussian Kernel Density of diffed time-series")
plt.legend();
Our stationary series looks also somewhat normally distributed, which is always a nice property.
Now, let us create the forecast for the test period. Presuming that we don’t know the exact distribution of our i.i.d. series, we simply draw from the empirical distribution via the training data. Hence, we simulate future values by reintegrating random samples from the empirical data:
full_sample = []
np.random.seed(123)
for i in range(10000):
draw = np.random.choice(diffed_s,len(test))
result = list(diffed.iloc[-12:].values)
for t in range(len(test)):
result.append(result[t]+draw[t])
full_sample.append(np.array(((rooted.iloc[-1])+np.cumsum(result[12:]))**2).reshape(-1,1))
reshaped = np.concatenate(full_sample,1)
result_mean = np.mean(reshaped,1)
lower = np.quantile(reshaped,0.05,1)
upper = np.quantile(reshaped,0.95,1)
plt.figure(figsize = (14,8))
plt.plot(train, label = "Train",color="blue")
plt.plot(test, label = "Test",color="red")
plt.grid(alpha = 0.5)
plt.plot(test.index, result_mean,label = "Simple model forecast",color="green")
plt.legend()
plt.fill_between(test.index,lower,upper,alpha=0.3,color="green");
This looks very good - the mean forecast is very close to the test data. In addition, our simulation allows us to empirically sample the whole forecast distribution. Therefore, we can also easily add confidence intervals.
Finally, let us see how our approach compares against rather complex time-series models. To do so, I went with Nixtla’s implementation of NBEATS and NHITS:
from copy import deepcopy
from neuralforecast import NeuralForecast
from neuralforecast.models import NBEATS, NHITS
train_nxt = pd.DataFrame(train).reset_index()
train_nxt.columns = ["ds","y"]
train_nxt["unique_id"] = np.ones(len(train))
test_nxt = pd.DataFrame(test).reset_index()
test_nxt.columns = ["ds","y"]
test_nxt["unique_id"] = np.ones(len(test))
horizon = len(test_nxt)
models = [NBEATS(input_size=2 * horizon, h=horizon,max_epochs=50),
NHITS(input_size=2 * horizon, h=horizon,max_epochs=50)]
nf = NeuralForecast(models=models, freq='M')
nf.fit(df=train_nxt)
Y_hat_df = nf.predict().reset_index()
nbeats = Y_hat_df["NBEATS"]
nhits = Y_hat_df["NHITS"]
rmse_simple = np.sqrt(np.mean((test.values-result_mean)**2))
rmse_nbeats = np.sqrt(np.mean((test.values-nbeats.values)**2))
rmse_nhits = np.sqrt(np.mean((test.values-nhits.values)**2))
pd.DataFrame([rmse_simple,rmse_nbeats,rmse_nhits], index = ["Simple", "NBEATS", "NHITS"], columns=["RMSE"])Global seed set to 1
Global seed set to 1| RMSE | |
|---|---|
| Simple | 25.502159 |
| NBEATS | 44.069832 |
| NHITS | 62.713951 |
As we can see, our almost trivial model has beaten two sophisticated time-series models by a fair margin. Of course, we need to emphasize that this doesn’t allow to draw any general conclusions.
Rather, I’d expect the neural models to outperform our simple approach for larger datasets. Nevertheless, as a benchmark, those trivial models are always a worthwhile consideration.
Takeaways - What do we make of this?
As stated multiple times throughout this article:
A seemingly complex time-series could still follow a fairly simple data-generating process.
In the end, you might spend hours trying to fit an overly complex model even though the underlying problem is almost trivial. At some point, somebody could come along, fit a simple ARIMA(1,0,0), and still outperform your sophisticated neural model.
To avoid the above worst-case scenario, consider the following idea:
When starting out with a new time-series problem, always start with the simplest possible model and use it as a benchmark for all other models.
Although this is common knowledge in the Data Science community, I feel like it deserves particular emphasis in this context. Especially due to nowadays’ (to some extent justified) hype around Deep Learning, it can be tempting to directly start with something fancy.
For many problems, this might just be the right way to go. Nobody today would consider a Hidden Markov Model for NLP today when LLM embeddings are available almost for free now.
Once your time-series becomes large, however, modern Machine Learning will likely be better. In particular, Gradient Boosted Trees are very popular for such large-scale problems.
A more controversial approach would be, you guessed it, Deep Learning for time-series. While some people believe that these models don’t work as well here, their popularity at tech firms like Amazon probably speaks for itself.
References
[1] Hamilton, James Douglas. Time series analysis. Princeton university press, 2020.
[2] Hyndman, Rob J., & Athanasopoulos, George. Forecasting: principles and practice. OTexts, 2018.
Introduction
As you can probably tell by my other articles (for example here, here and here), I am a big fan of GARCH models. Forecasting conditional variance is arguably the best we can get in predicting stock returns out of themselves.
Still, the GARCH family is no silver bullet that suddenly makes you a stock wizard. Countless variations imply that there is no single best approach to handle conditional variance.
Today, let us look at one interesting variant of GARCH - namely, Varying Coefficient GARCH. If you are in a hurry, you can find the Jupyter notebook corresponding to this article here.
Drawbacks of traditional GARCH
First, we’ll quickly go through some limitations of the standard GARCH model. Although we have discussed them before, it’s always good to refresh important aspects of our models.
For simplicity, we will only go through GARCH(1,1). The generalized version just uses an arbitrary number of lags for both squared observations and variance. Also, we assume a constant mean of zero.
With that in mind, GARCH(1,1) follows the following equations: From these, we can derive two important issues:
The linear assumption of GARCH
GARCH makes the relatively light assumption of variance being a linear combination of past data. On the one hand, this goes very well with Occam’s razor. Simpler models are very often more robust.
One observation I often make when experimenting with more flexible GARCH models is overfitting. Consider a very bad probabilistic model for some data. If you allow variance to be very flexible, you just need to make that variance very large. Then, all of your training observations will still achieve a reasonably well likelihood or model fit.
using Distributions, Random, Printf, Plots
Random.seed!(123)
data = randn(100)
dist1 = Normal(-3,0.5)
dist2 = Normal(-3,4)
ll1 = mean(logpdf.(dist1,data))
ll2 = mean(logpdf.(dist2,data))
line = collect(-8:0.1:8)
p1 = plot(line, pdf.(dist1,line), label="Model density", size=(1000,500),
ylim=(-0.02,1), title=@sprintf "Model LogLikelihood: %.3f" ll1)
plot!(p1, line,pdf.(Normal(),line),color=:red, label="True density")
scatter!(p1, data, zeros(100), label="Sampled data")
vline!(p1, [-3], color=1, linestyle=:dash, lw=2, label = "Model distribution mean")
p2 = plot(line, pdf.(dist2,line), label="Model density", size=(1000,500),
ylim=(-0.02,1), title=@sprintf "Model LogLikelihood: %.3f" ll2)
plot!(p2, line,pdf.(Normal(),line),color=:red, label="True density")
scatter!(p2, data, zeros(100), label="Sampled data")
vline!(p2, [-3], color=1, linestyle=:dash, lw=2, label = "Model distribution mean")
plot(p1,p2, size=(1000,500), fmt=:png)
Thus, the linearity assumption guarantees a sensible amount of model regularization. On the other hand, this might nevertheless be too restrictive when linearity is clearly not present in the data.
The Gaussian assumption
Probably the most common assumption of all foundational statistical and econometrical models. In standard GARCH, we presume Gaussian observations as well. The only difference to your standard time-series models is that we are predicting variance, not the mean.
As mentioned countless times before, real-world data is almost never Gaussian. This is particularly the case for stock market returns, where GARCH is probably used the most. Hence, a fundamental assumption of our model stands in conflict with real-world observations.
In practice, the Gaussian distribution is often replaced by something more flexible. Examples include the location-scale Student-t distribution or the Generalized Beta distribution.
Today, we are considering the linearity issue of GARCH. For a possible treatment of the Gaussian issue, you can also take a look at this article of mine.
Motivation for Varying Coefficient GARCH
As already mentioned, the linearity assumption can be limiting. The obvious fix would be to just use some non-linear alternative and call it a day. However, there are two issues with that. Let us start with the bigger one first:
It is difficult to prove stability of non-linear models. Depending on our particular model, it can be tricky, if not impossible to ensure that it is well behaved. At worst, we could see the forecast going completely bonkers over time.
With a plain linear model and some fundamental theory, it is straightforward to ensure that this doesn’t happen. Using an arbitrary model, though, this advantage can easily vanish.
The second issue is that standard non-linear models are hard to interpret. Consider again the standard GARCH setup: We can easily reason about the effect of each ‘factor’ in our model. Without further ado, we could also include additional factors like company sector, etc. in our model.
Obviously, this is not possible with an arbitrary, non-linear alternative anymore. Thus, considering both the above issues, a varying coefficient model becomes quite attractive.
Varying coefficient models
The straightforward rationale of varying coefficient models is the following: If fixed parameters are restrictive, why not just make them dynamic?
And indeed, this is what varying coefficient models are all about. Our primary goal is to move from static coefficient to ones that are dynamic given different inputs.
In a linear regression model, this could look as follows: The coefficients are simply a function of the inputs. Thus, each input can have a unique set of linear model parameters. This allows us to model non-linear functions in a - locally - linear fashion.
For standard regression models there exists a lot of previous research dating back into the nineties. Nowadays, we also see some modern approaches to varying coefficient models.
One example is this fairly recent paper which uses neural networks to model varying coefficients on a large scale. There, the approach is used for image classification. The findings are quite impressive - the model is able to highlight reasonable image sections that are most relevant for the model output.
Obviously, there also exists previous work on varying coefficient GARCH already, see for example
To keep things easy for now, we’ll use a fairly simplistic variant. From there, you can try different variations yourself.
Varying Coefficient GARCH
Let us re-state the standard GARCH(1,1) equations from before: An alternative with varying coefficients then makes the coefficients a function of some variables of interest:
Let us, again for simplicity, use a feedforward neural network to model the varying coefficients:

Now, we can take advantage of linearity in the varying coefficients and ensure stationarity via for all
For static coefficient GARCH, it is relatively easy to ensure this stationarity condition. Just use one of the popular optimization packages and enter the respective linear constraint.
In the varying coefficient case this might, at first sight, not be as obvious. Libraries for neural networks don’t allow any constraints on the network output out-of-box. Thus, we need to build a solution to this problem ourselves.
For GARCH(1,1), this is actually very simple. We only need to find a transformation of our network output, that ensures stationarity. In fact, we can simply do the following: By playing around with the sigmoid function, we can quickly find a suitable transformation. For arbitrary GARCH order, this can be more of a hassle, so we won’t consider this case here.
Some rationale behind the model
You might wonder why we don’t make the parameters dependent on squared past realizations and past variance. For the latter, it shouldn’t make that much of a difference if we used variance instead of standard deviation.
For past observations, though, there is a clear advantage: Negative and positive realizations of the time-series can affect future variance differently. In the stock market example, large negative returns are likely to cause greater variance in subsequent periods. This is, for example, the philosophy behind the TGARCH model.
As for the neural network, we could also use other popular function approximators. This includes Regression Splines or higher order polynomials. Given their still undefeated popularity, I decided that neural networks would be the most interesting choice.
A quick demonstration of varying coefficient GARCH
In other GARCH articles, I have primarily used Python for the implementation. Today, let us use Julia for fun and education. Personally, I find the language much more efficient for some quick experiments. On the other hand, deployment is less of a pleasure if you need to manage the JIT overhead.
We begin with the usual data loading process. Here, I used 5 years of DAX data from yahoo finance and calculated the log-returns of the adjusted close price. The final 100 observations are kept in a holdout set:
using Plots, CSV, DataFrames
#https://de.finance.yahoo.com/quote/%5EGDAXI/history?period1=1515801600&period2=1673568000&interval=1d&filter=history&frequency=1d&includeAdjustedClose=true
df = CSV.File("../data/GDAXI.csv") |> DataFrame
a_close_raw = df[!,["Adj Close", "Date"]]
a_close_nonull = a_close_raw[findall(a_close_raw[!,"Adj Close"].!= "null"),:]
a_close = parse.(Float32, a_close_nonull[!,"Adj Close"])
returns = diff(log.(a_close))
train = returns[1:end-99]
train_idx = a_close_nonull[!,"Date"][2:end-99]
test = returns[end-99:end]
test_idx = a_close_nonull[!,"Date"][end-99:end]
plot(train_idx,train, label="^GDAXI daily returns - Train", size = (1200,600), fmt=:png)
plot!(test_idx, test, label="^GDAXI daily returns - Test")
Next, we create our varying coefficient GARCH. As Julia is more or less a functional language, there aren’t any classes, unlike Python.
Also, we do not store the latent state of our model (= the conditional variance) over time. This is due to the fact that Zygote, one of Julia’s AutoDiff libraries, doesn’t allow mutating arrays. Rather, we recursively call the respective function and pass the current state to the next function call.
(Technically, it is possible to store intermediate states in a Zygote.Buffer. Let us here use the functional variant anyway for educational purposes.)
using Flux, Distributions
struct VarCoeffGARCH
constant::Vector{Float32}
net::Chain
x0::Vector{Float32}
end
Flux.@functor VarCoeffGARCH
VarCoeffGARCH(net::Chain) = VarCoeffGARCH([-9], net, [0.0])
function garch_mean_ll(m::VarCoeffGARCH, y::Vector{Float32})::Float32
sigmas, _ = garch_forward(m,y)
conditional_dists = Normal.(0, sigmas)
return mean(logpdf.(conditional_dists, y))
end
#Use functional implementation to calculate conditional stddev.
#Then, we don't need to store stddev_t to calculate stddev_t+1
#and thus avoid mutation, which doesn't work with Zygote
#(could use Zygote.Buffer, but it's often discouraged)
function garch_forward(m::VarCoeffGARCH, y::Vector{Float32})
sigma_1, params_1 = m(m.x0[1], sqrt(softplus(m.constant[1])))
sigma_rec, params_rec = garch_forward_recurse(m, sigma_1, y, 1)
sigmas_result = vcat(sigma_1, sigma_rec)
params_result = hcat(params_1, params_rec)
return sigmas_result, params_result
end
function garch_forward_recurse(m::VarCoeffGARCH, sigma_tm1::Float32, y::Vector{Float32}, t::Int64)
sigma_t, params_t = m(y[t], sigma_tm1)
if t==length(y)-1
return sigma_t, params_t
end
sigma_rec, params_rec = garch_forward_recurse(m, sigma_t, y, t+1)
sigmas_result = vcat(sigma_t, sigma_rec)
params_result = hcat(params_t, params_rec)
return sigmas_result, params_result
end
function (m::VarCoeffGARCH)(y::Float32, sigma::Float32)
input_vec = vcat(y, sigma)
params = m.net(input_vec)
params_stable = get_garch_stable_params(params) #to ensure stationarity of the resulting GARCH process
return sqrt(softplus(m.constant[1]) + sum(input_vec.^2 .* params_stable)), params_stable
end
#transform both parameters to be >0 each and their sum to be <1
get_garch_stable_params(x::Vector{Float32}) = vcat(σ(x[1]), (1-σ(x[1]))*σ(x[2]))get_garch_stable_params (generic function with 1 method)Next, we create and train our varying coefficient GARCH model. Notice that I used a rather tiny architecture for the respective neural network. This hopefully counters the risk of overfitting to some extent.
If we were more engaged, we could experiment with different architectures. Here, however, this is left as an exercise to the reader.
using Random, Zygote
Random.seed!(123)
model = VarCoeffGARCH(Chain(Dense(2,2,softplus), Dense(2,2,softplus), Dense(2,2)))
params = Flux.params(model)
opt = ADAM(0.01)
for i in 1:500
grads = Zygote.gradient(()->-garch_mean_ll(model, train), params)
Flux.Optimise.update!(opt,params,grads)
if i%50==0
println(garch_mean_ll(model,train))
end
end2.973238
3.0015454
3.0188503
3.0298147
3.038704
3.0551393
3.0628562
3.0676363
3.0707815
3.0733144Notice that we get the gradients via AutoDiff from Zygote. Another popular approach for GARCH models is to use black-box gradients via finite differences. Given that our neural network could easily have many more parameters, this would quickly become infeasible.
After model fitting, we can plot the in-sample predictions to check if everything went well:
sigmas, params = garch_forward(model,train)
lower = quantile.(Normal.(0,sigmas),0.05)
upper = quantile.(Normal.(0,sigmas),0.95)
plot(train_idx, train, label="^GDAXI daily returns", size = (1200,600), title="In-Sample predictions", fmt=:png)
plot!(train_idx, zeros(length(lower)), ribbon=(upper,-lower),label = "90% CI")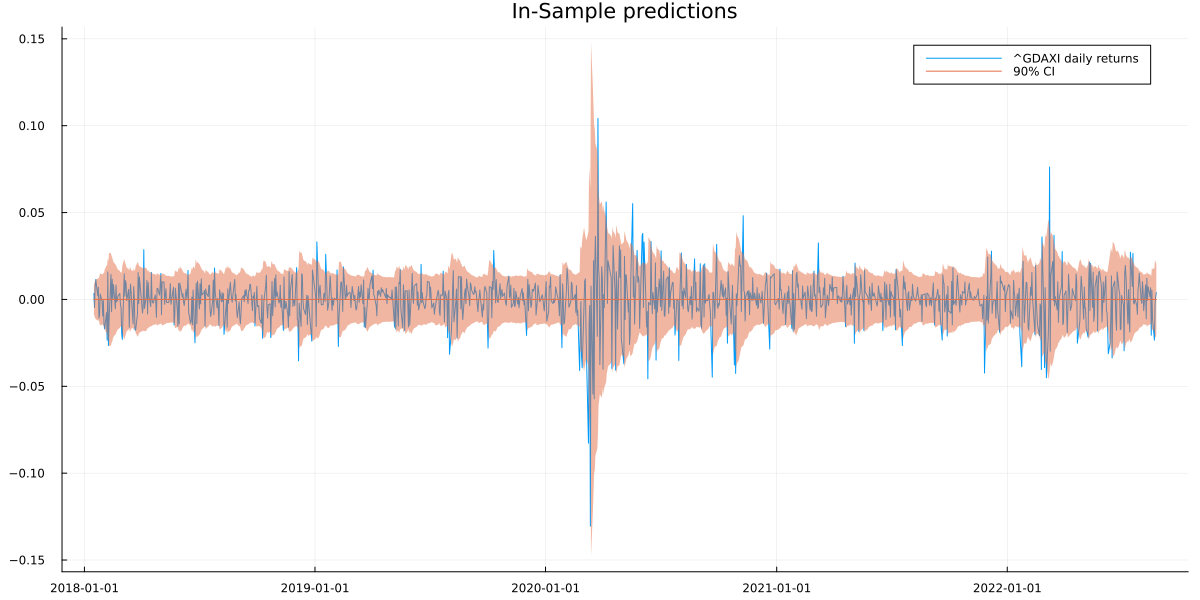
This looks like a reasonable GARCH prediction for in-sample data. To see if it also works out-of-sample, we generate a forecast via MC-sampling. This is necessary as we cannot integrate out the probabilistic forecast at for
analytically.
function garch_forward_sample(m::VarCoeffGARCH, sigma_tm1::Float32, y_tm1::Float32, t::Int64, T::Int64=100)
sigma_t, params_t = m(y_tm1, sigma_tm1)
sample_t = randn(Float32)*sigma_t
if t==T
return sigma_t, sample_t, params_t
end
sigma_rec, sample_rec, params_rec = garch_forward_sample(m, sigma_t, sample_t, t+1, T)
sigmas_result = vcat(sigma_t, sigma_rec)
sample_result = vcat(sample_t, sample_rec)
params_result = vcat(params_t, params_rec)
return sigmas_result, sample_result, params_result
end
Random.seed!(123)
mc_simulation = [garch_forward_sample(model, sigmas[end], train[end], 1) for _ in 1:25000]
sigma_sample = hcat(map(x->x[1], mc_simulation)...)
y_forecast_sample = hcat(map(x->x[2], mc_simulation)...)
params1_sample = hcat(map(x->x[3], mc_simulation)...)
params2_sample = hcat(map(x->x[3], mc_simulation)...)
y_forecast_mean = mean(y_forecast_sample,dims=2)[:]
y_forecast_lower = mapslices(x->quantile(x,0.05), y_forecast_sample, dims=2)[:]
y_forecast_upper = mapslices(x->quantile(x,0.95), y_forecast_sample, dims=2)[:]
plot(test[1:100], size = (1200,600), title = "100 steps ahead forecast", label="Test set", fmt=:png)
plot!(y_forecast_mean, ribbon = (y_forecast_upper.-y_forecast_mean, y_forecast_mean.-y_forecast_lower), label="Forecast and 90% CI")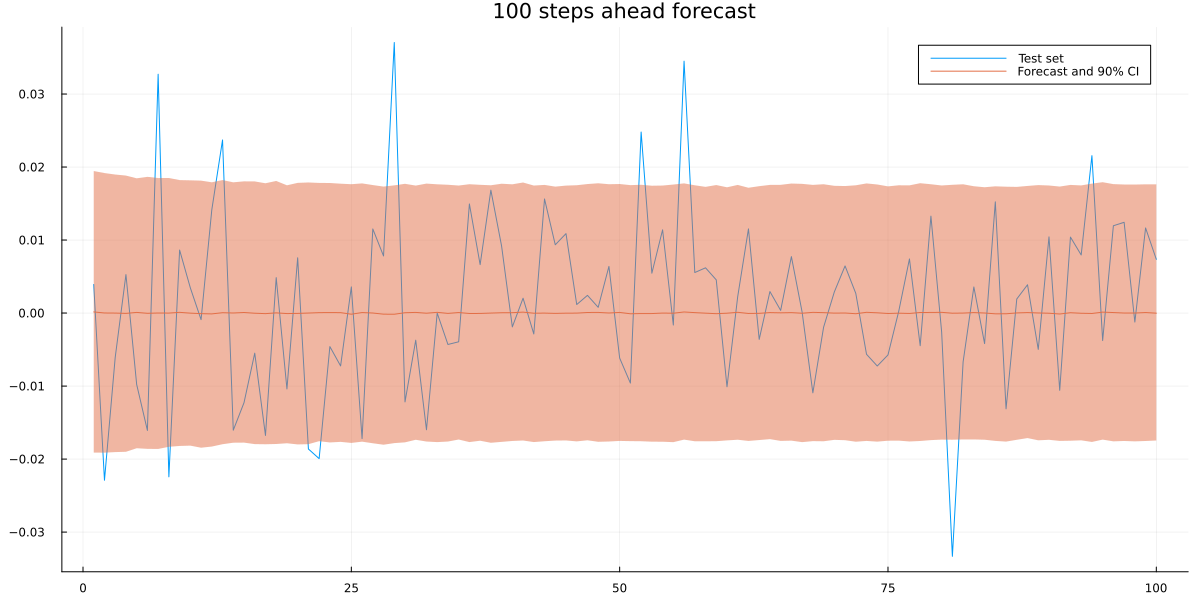
Again, a reasonably looking plot. Since we also want to check if we built anything useful, let us also compare to a standard GARCH(1,1) forecast. We need to integrate out numerically once more:
using ARCHModels
garch_model = fit(GARCH{1,1}, train)
garch_model_dummy = fit(GARCH{1,1}, train[1:end-1]) #to get latent variance of final training observation
Random.seed!(123)
var_T = predict(garch_model_dummy, :variance, 1)
y_T = train[end]
garch_coefs = garch_model.spec.coefs
mean_coef = garch_model.meanspec.coefs[1]
garch_sigma_sample = zeros(100,25000)
garch_forecast_sample = zeros(100,25000)
for i in 1:25000
sigma_1 = sqrt(garch_coefs[1] + garch_coefs[2]*var_T + garch_coefs[3]*(y_T-mean_coef)^2)
garch_sigma_sample[1,i] = sigma_1
forecast_sample = randn()*sigma_1+mean_coef
garch_forecast_sample[1,i] = forecast_sample
for t in 2:100
var_tm1 = garch_sigma_sample[t-1,i]^2
eps_tm1 = (garch_forecast_sample[t-1,i]-mean_coef)^2
sigma_t = sqrt(garch_coefs[1] + garch_coefs[2]*var_tm1 + garch_coefs[3]*eps_tm1)
garch_sigma_sample[t,i] = sigma_t
forecast_sample = randn()*sigma_t+mean_coef
garch_forecast_sample[t,i] = forecast_sample
end
end
garch_forecast_mean = mean(garch_forecast_sample,dims=2)[:]
garch_forecast_lower = mapslices(x->quantile(x,0.05), garch_forecast_sample, dims=2)[:]
garch_forecast_upper = mapslices(x->quantile(x,0.95), garch_forecast_sample, dims=2)[:]
plot(test[1:100], size = (1200,600), title = "100 steps ahead forecast", label="Test set", fmt=:png)
plot!(y_forecast_mean, ribbon = (y_forecast_upper.-y_forecast_mean, y_forecast_mean.-y_forecast_lower), label="VarCoef GARCH forecast")
plot!(garch_forecast_mean,
ribbon = (garch_forecast_upper.-garch_forecast_mean, garch_forecast_mean.-garch_forecast_lower),
label="Standard GARCH forecast", alpha=0.5)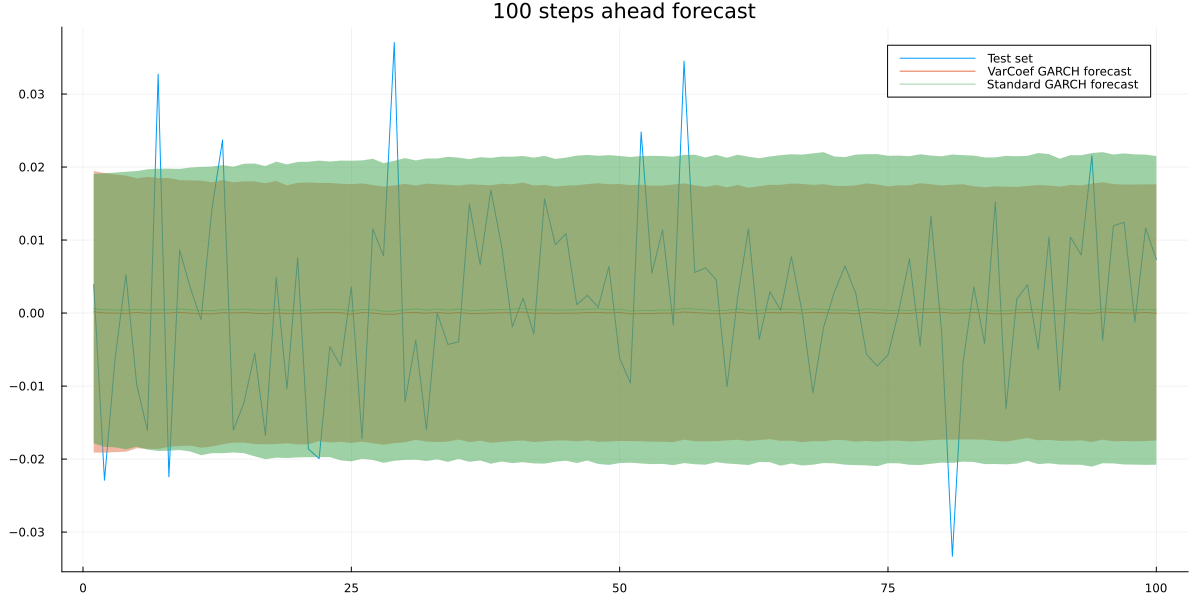
The standard GARCH model produces a larger forecast interval. To make both models comparable quantitatively, we use the average out-of-sample log-likelihoods:
using KernelDensity
var_coef_ll = mean([log(pdf(kde(y_forecast_sample[t,:]),test[t])) for t in 1:100])
standard_ll = mean([log(pdf(kde(garch_forecast_sample[t,:]),test[t])) for t in 1:100])
println(var_coef_ll)
println(standard_ll)3.006017233022985
3.0003596946242705Our model has a slightly better out-of-sample log-likelihood. Obviously, we could likely improve this with different architectures and/or a higher GARCH model order. Just try not to overfit!
Finally, we can take a look at the behaviour of the varying coefficients. One interesting view is past in-sample observations against each coefficient. For comparison, I also added the fixed coefficient from standard GARCH:
using LaTeXStrings
title = plot(title = "Varying coefficient GARCH: "*L"\sigma^2_t=\omega + \alpha^{NN}(y_{t-1},\sigma_{t-1})y^2_{t-1}+\beta^{NN}(y_{t-1},\sigma_{t-1})σ^2_{t-1}", grid = false, showaxis = false)
p1 = scatter(train[1:end-1], params[1,2:end], label=:none, guidefontsize=15)
xlabel!(p1,L"y_{t-1}")
ylabel!(p1,L"\alpha_t")
hline!([garch_coefs[3]], color=:red, label="Parameter in GARCH model")
p2 = scatter(train[1:end-1], params[2,2:end], label=:none, guidefontsize=15)
xlabel!(p2,L"y_{t-1}")
ylabel!(p2,L"\beta_t")
hline!([garch_coefs[2]], color=:red, label="Parameter in GARCH model")
plot(title, p1, p2, layout = @layout([A{0.01h}; [B C]]), size = (1200,600), left_margin=10*Plots.mm, bottom_margin=5*Plots.mm,fmt=:png)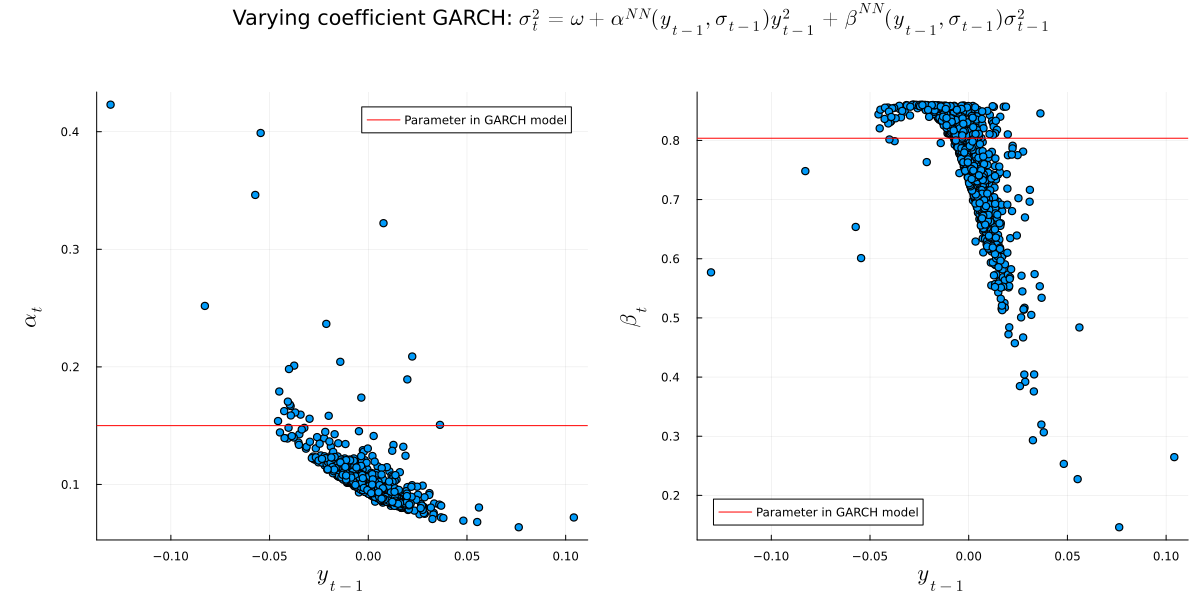
Interestingly, both varying coefficients are in the same ballpark as standard GARCH. This adds some confidence that we are on the right track.
Nevertheless, as mentioned above, there is possibly still a lot of room for improvement.
Conclusion
Now, where do we go from here? To put it bluntly, we have yet another GARCH variation that promises to fix one limitation of standard GARCH. With a little sophistication, we get a model that is flexible and fairly transparent at the same time.
Now we could, for example, easily introduce external factors to our model. The current state of the general economy or the company’s sector are likely to influence return volatility.
With our varying coefficient GARCH, we can account for such effects. At the same time, it is possible to validate the predicted effect of each feature.
The biggest advantage in my opinion is, however, that we don’t have to worry about stationarity. If we restrict our model to always yield valid GARCH coefficients, there is no risk of exploding forecasts.
This makes this model quite powerful, yet fairly simple to handle. If you have any questions about it, please let me know.
References
[1] Bollerslev, Tim. Modelling the coherence in short-run nominal exchange rates: a multivariate generalized ARCH model. The review of economics and statistics, 1990, p. 498-505.
[2] Donfack, Morvan Nongni; Dufays, Arnaud. Modeling time-varying parameters using artificial neural networks: a GARCH illustration. Studies in Nonlinear Dynamics & Econometrics, 2021, p. 311-343.
[3] Hastie, Trevor; Tishbirani, Robert. Varying coefficient models. Journal of the Royal Statistical Society: Series B (Methodological), 1993, p. 757-779.
Introduction
In the last article, we discussed one advantage of probabilistic forecasts over point forecasts - namely, handling time-to-exceedance problems. In this post, we will examine another limitation of point forecasts: Higher order statistical properties.
The ideas will be very familiar to those with a background in mathematics or statistics. Readers without formal training in either will therefore probably benefit the most from this article.
By the end of this post, you’ll have a better idea of how higher order statistical properties can impact the performance of your forecasts. In particular, we will see how point forecasts can actually completely fail without further adjustment.
Two examples of point forecast failure
To sensitize you for the issues of point forecasts, let us continue with two very simple examples. Both time-series admit to a pretty simple, auto-regressive data generating process.
We will generate enough data for an auto-regressive Gradient Boosting model to be sensible. Thus, we avoid both using a model that is too inflexible and overfitting due to a lack of data.
Example 1 - Auto-regressive variance (GARCH)
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(987)
time_series = [np.random.normal()*0.1, np.random.normal()*0.1]
sigs = [0.1, 0.1]
for t in range(2000):
sig_t = np.sqrt(0.1 + 0.24*time_series[-1]**2 + 0.24*time_series[-2]**2 + 0.24*sigs[-1]**2 + 0.24*sigs[-2]**2)
y_t = np.random.normal() * sig_t
time_series.append(y_t)
sigs.append(sig_t)
y = np.array(time_series[2:])
plt.figure(figsize = (16,8))
plt.plot(y, label = "Simulated Time-Series")
plt.grid(alpha = 0.5)
plt.legend(fontsize = 18);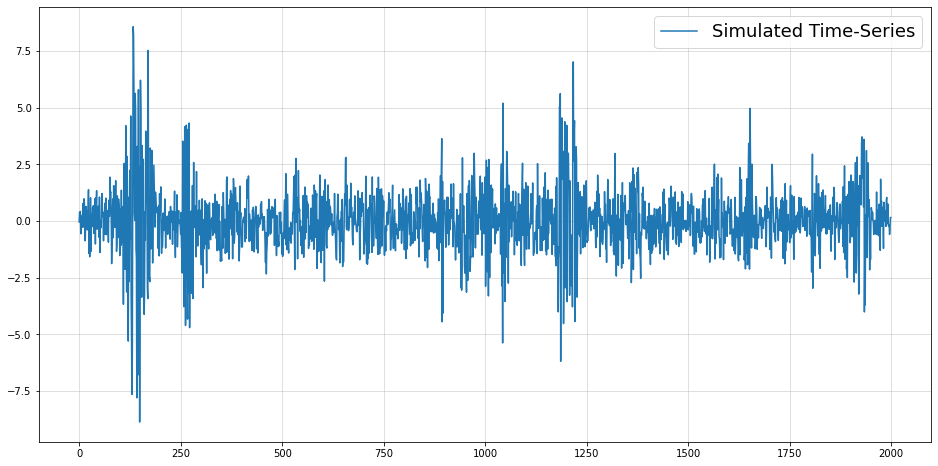
This is a standard GARCH time-series as they are frequently encountered in econometrics. If you want to get some ideas on how you can handle such data, I have also written a few articles:
- Random Forests and Boosting for ARCH-like volatility forecasts
- Multivariate GARCH with Python and Tensorflow
- Let’s make GARCH more flexible with Normalizing Flows
Anyway, let us use the cookie cutter approach of Machine Learning for time-series for now. Namely, we use Nixtla’s mlforecast package to build an auto-regressive Boosting model for us. (This is not meant to bash on the Nixtla package. In fact, it is really helpful and convenient if you know what you are doing.)
The results look as follows:
from mlforecast.utils import generate_daily_series
from sklearn.ensemble import GradientBoostingRegressor
from mlforecast import MLForecast
np.random.seed(987)
y_train = y[:1800]
y_test = y[1800:]
series = generate_daily_series(
n_series=1,
max_length=10000,
).iloc[:1800,:]
series["y"] = y_train
models = [
GradientBoostingRegressor(),
]
fcst = MLForecast(
models=models,
freq='D',
lags=[1, 2]
)
fcst.fit(series, id_col='index', time_col='ds', target_col='y')
predictions = fcst.predict(200)
plt.figure(figsize = (16,8))
plt.plot(y_test, label = "Test set")
plt.plot(predictions.iloc[:,1].values, label = "Gradient Boosting forecast", lw=3)
plt.grid(alpha = 0.5)
plt.legend(fontsize = 18);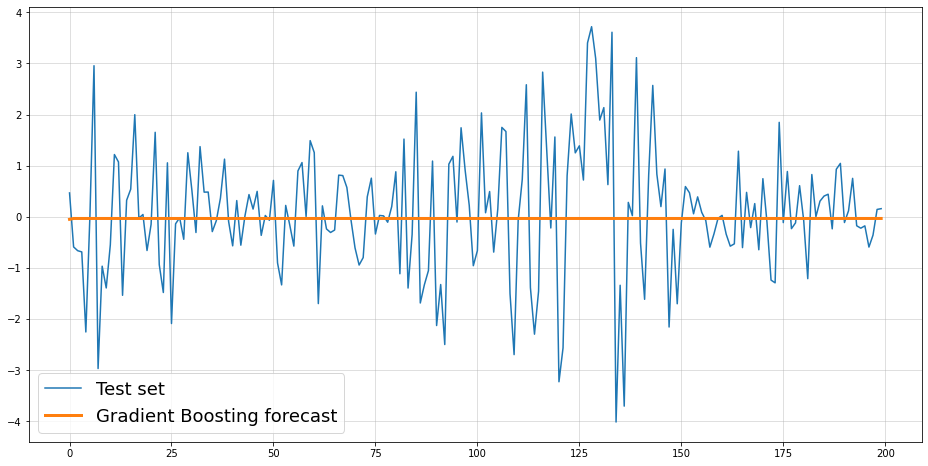
Unfortunately, the result does not help at all. Although we have provided the actual ground-truth number of lags, the forecast is practically useless.
Example 2 - Auto-regressive, non-Gaussian data
This next example follows a more cooked up data generating process. Nevertheless, this doesn’t preclude some real-world time-series following a similar logic, too:
from scipy.stats import beta
np.random.seed(321)
time_series = [beta(0.5,10).rvs()]
for t in range(2000):
alpha_t = 0.5 + time_series[-1] * 0.025 * t
beta_t = alpha_t * 20
y_t = beta(alpha_t, beta_t).rvs()
time_series.append(y_t)
y = np.array(time_series[1:])
plt.figure(figsize = (16,8))
plt.plot(y, label = "Simulated Time-Series")
plt.grid(alpha = 0.5)
plt.legend(fontsize = 18);
Let us check how a Gradient Boosting model performs for this case:
from mlforecast.utils import generate_daily_series
from sklearn.ensemble import GradientBoostingRegressor
from mlforecast import MLForecast
np.random.seed(987)
y_train = y[:1800]
y_test = y[1800:]
series = generate_daily_series(
n_series=1,
max_length=10000,
).iloc[:1800,:]
series["y"] = y_train
models = [
GradientBoostingRegressor(max_depth = 1),
]
fcst = MLForecast(
models=models,
freq='D',
lags=[1]
)
fcst.fit(series, id_col='index', time_col='ds', target_col='y')
predictions = fcst.predict(200)
plt.figure(figsize = (16,8))
plt.plot(y_test, label = "Test set")
plt.plot(predictions.iloc[:,1].values, label = "Gradient Boosting forecast", lw=3)
plt.grid(alpha = 0.5)
plt.legend(fontsize = 18);
Again, the forecast is utterly useless.
What has gone wrong with our point forecasts?
As you might know, sklearn.ensemble.GradientBoostingRegressor minimizes the mean-squared error (MSE) by default. The following is a well known property of MSE-minimization:
A distribution’s mean minimizes its mean-squared error.
Mathematically: where we presume an arbitrarily large set of admissable functions. Also, we implicitly need to assume that the conditional mean actually exists. This is reasonably likely for most well-behaved forecasting problems.
Thus, both of the above models aim to forecast the mean of the conditional distribution of our observations. The issue here is that the conditional mean is actually constant by construction.
This is obvious for the first example - each observation has a conditional mean of zero. For the second example, we would have to do some math for a formal proof that is left to the interested reader.
Now, although the conditional mean remains constant over time, our time-series is still far from being just pure noise. Predicting the mean via MSE-minimization was rather inadequate to describe the future.
We can go even further and proclaim:
Even a perfect (point-) forecasting model can be useless if the forecast quantity is uninformative.
We can visualize via plots of conditional densities against conditional means from our examples:
from scipy.stats import norm
np.random.seed(987)
line_1 = np.linspace(-4,4,250)
time_series = [np.random.normal()*0.1, np.random.normal()*0.1]
sigs = [0.1, 0.1]
conditional_pdfs_1 = [norm(0,0.1).pdf(line_1)]*2
conditional_means_1 = [0., 0.]
for t in range(2000):
sig_t = np.sqrt(0.1 + 0.24*time_series[-1]**2 + 0.24*time_series[-2]**2 + 0.24*sigs[-1]**2 + 0.24*sigs[-2]**2)
y_t = np.random.normal() * sig_t
time_series.append(y_t)
sigs.append(sig_t)
conditional_pdfs_1.append(norm(0,sig_t).pdf(line_1))
conditional_means_1.append(0.)
conditional_pdfs_1 = conditional_pdfs_1[2:]
conditional_means_1 = conditional_means_1[2:]
np.random.seed(987)
line_2 = np.linspace(0,1,250)
time_series = [beta(0.5,10).rvs()]
conditional_pdfs_2 = [beta(0.5,10).pdf(line_2)]
conditional_means_2 = [beta(0.5,10).mean()]
for t in range(2000):
alpha_t = 0.5 + time_series[-1] * 0.025 * t
beta_t = alpha_t * 20
y_t = beta(alpha_t, beta_t).rvs()
time_series.append(y_t)
conditional_pdfs_2.append(beta(alpha_t, beta_t).pdf(line_2))
conditional_means_2.append(beta(alpha_t, beta_t).mean())
conditional_pdfs_2 = conditional_pdfs_2[1:]
conditional_means_2 = conditional_means_2[1:]
_, (ax1, ax2) = plt.subplots(1,2, figsize = (16,8))
ax1.plot(line_1, conditional_pdfs_1[0], label = "Conditional density, t=1", lw=2, c="red")
ax1.plot(line_1, conditional_pdfs_1[999], label = "Conditioanl density, t=1000", lw=2, c="green")
ax1.plot(line_1, conditional_pdfs_1[1999], label = "Conditional density, t=2000", lw=2, c="blue")
ax1.axvline([conditional_means_1[0]], lw=3, c="purple", ls="dashed", label = "Constant, conditional mean")
ax1.grid(alpha = 0.5)
ax1.legend(fontsize=11)
ax1.set_title("Example 1", fontsize = 15)
ax2.plot(line_2, conditional_pdfs_2[0], label = "Conditional density, t=1", lw=2, c="red")
ax2.plot(line_2, conditional_pdfs_2[999], label = "Conditioanl density, t=1000", lw=2, c="green")
ax2.plot(line_2, conditional_pdfs_2[1999], label = "Conditional density, t=2000", lw=2, c="blue")
ax2.axvline([conditional_means_2[0]], lw=3, c="purple", ls="dashed", label = "Constant, conditional mean")
ax2.grid(alpha = 0.5)
ax2.legend(fontsize = 11)
ax2.set_title("Example 2", fontsize = 15);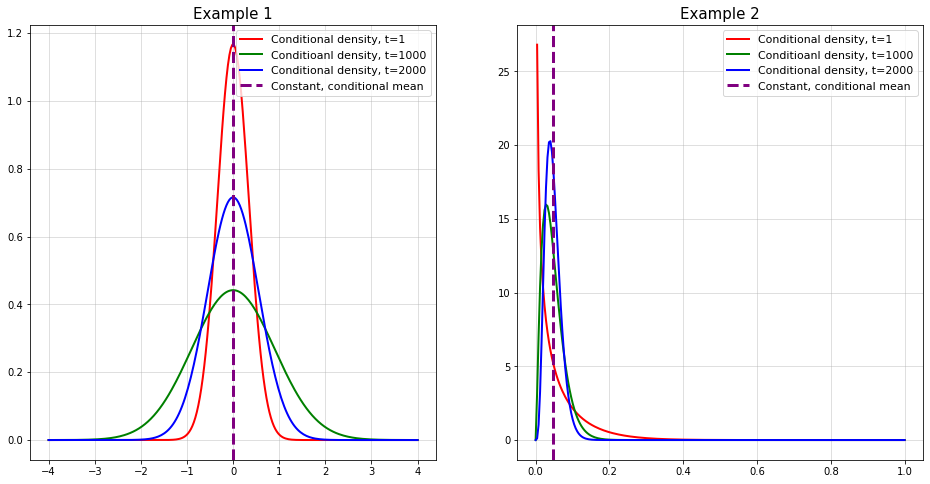
On the one hand, the conditional distribution is varying and can be predicted from past by construction. The conditional mean, however, is constant and does not tell us anything about the future distribution.
What can we do?
At first glance, the above issues paint a rather grim picture of the capabilities of raw point forecasts. As always, the situation is of course much more granular.
Therefore, let us discuss a rough pathway of what to do if your point forecasts aren’t really cutting it.
Assess if you even have a problem at all - point forecasts can still work
As we have just seen, point forecasts can fail miserably. Given that they are being widely used, however, indicates that they will cause trouble for your problem. Many forecasting problems can be solved reasonably well with standard approaches.
Sometimes, you just need to put in a little more effort into your model. Simply using another loss function or another non-linear transformation of your features might be sufficient. Once you observe that a point forecast simply won’t cut it though, it might be time to go probabilistic.
Two cases can be good indicators:
1) Your point forecasts show little variation and are almost constant.
Mathematically: This is what happened in our examples and should be visible in your model validation steps. As we have seen, there is no reason to conclude that something is wrong with your model or your data yet.
2) Occasional, large outliers frequently make your point forecasts useless.
This issue leads us into the domain of extreme-value theory and probably deserves a blog series of its own. Hence, we will only take a brief look at what is happening here.
As an exaggerated, yet illustrative example, consider the following time-series:
from scipy.stats import cauchy
np.random.seed(987)
plt.figure(figsize = (16,8))
plt.plot(cauchy(np.sin(0.1 * np.arange(250)),0.05).rvs(), label = "Noisy observations")
plt.plot(np.sin(0.1 * np.arange(250)), label = "Theoretical sine wave")
plt.grid(alpha = 0.5)
plt.legend(fontsize=12)
This is nothing more than samples from a Cauchy distribution whose location is determined by a sine. Now, let us see how the MSE evolves with increasing sample size if our (point-) forecast was just a continuance of the underlying sine:
np.random.seed(987)
T = 250000
large_sample = cauchy(np.sin(0.1 * np.arange(T)),0.05).rvs()
optimal_point_forecast = np.sin(0.1 * np.arange(T))
running_mse = np.cumsum((large_sample - optimal_point_forecast)**2)/np.arange(1,T+1)
plt.figure(figsize = (16,8))
plt.plot(running_mse, label = "Running MSE of Cauchy-Sine forecast")
plt.grid()
plt.legend(fontsize = 12)
Surprisingly, the MSE doesn’t even converge after 250.000 (!) observations. No matter how much data you observe, your average (!) squared error keeps growing. This is a property of a certain family of probability distributions that the Cauchy is part of.
You will likely never observe such a monstrosity in your day-to-day life. Almost all real-world time-series adhere to certain limitations that make an infinite MSE unlikely.
Nevertheless, it would be helpful to get at least some idea of how likely you will observe large outliers. Imagine, for example, how valuable a rough probability of an extreme collapse of the tourism sector could have been in 2019.
Adjust your definition of a ‘useful’ forecast
Of course it can be very difficult to convince your stakeholders of the above issues of point forecasts. For business folks, probabilistic approaches might look like unnecessary rocket science.
Rather, we typically measure forecasting success by how closely predictions match future observations. If something goes wrong, just add more data and hope that you’ll be better off next time. However, consider the underlying complexity of most time-series systems. What are your chances of ever collecting all the relevant data?
This is like trying to collect and process all relevant factors to predict the exact outcome of a game of roulette. While possible in theory, the sheer amount of granularity makes this impossible in practice.
Nevertheless, you might discover that there are some physical flaws in the roulette table. If these flaws are skewing the odds in a certain direction, making your bets accordingly could make you a fortune in the long run.
If we transfer this analogy to general forecasting problems, this leads us to a paradigm shift:
Instead of trying to predict the future as exactly as possible, forecast models should optimize our odds when betting on future outcomes.
Taking this betting metaphor further, we arrive at three conclusions for forecasting:
1) Real-world decisions are almost always made under uncertainty
Consider the following problem:
You are an ice cream vendor and want to optimize your daily inventoy. For simplicity, we presume that each day, you either
- Sell exactly
10pounds of ice-cream with a90%chance or - Sell
0pounds with a10%chance (because the weather is really bad, you know)
Also, presume that
- You can buy
1pound of ice cream for1money at the beginning of each day - Sell
1pound for1.2money - Your ice-cream inventory goes to zero at the end of each day (no overnight warehousing)
- If your total losses exceed
-10money you are going bankrupt
Imagine you are building a demand forecast model for that problem to decide how much ice-cream you want to sell. If you go the point-forecast + MSE route, your result would be as follows:
Expected demand is , therefore the MSE-minimizing forecast is also 9 per day. Are you going to buy
9 pounds of ice-cream each day? What about the risk of bankruptcy if you don’t sell anything multiple times in a row?
plt.figure(figsize = (16,8))
plt.stem([0.,10.], [0.1,0.9], linefmt='b-', markerfmt='bo', basefmt='black', label = "Probability Mass Function")
plt.plot([9,9],[0,1], c="red", lw=3, ls="dashed", label = "Expected value / MSE-Minimizer")
plt.xlabel("Ice-cream demand in pounds", fontsize=12)
plt.grid(alpha = 0.5)
plt.legend(fontsize = 12);
This is the point where uncertainty comes into play and you need to decide on how much risk you want to take. As often in life, this is another trade-off between profit and risk.
Unfortunately, the point-forecast alone doesn’t account for any uncertainty.
Let us now presume that we had a probabilistic forecast model that was able to predict the respective probability mass function (pmf). From here, we can derive our earnings for day
as a random variable given our inventory
:
This information could then be used in a stochastic program. The latter can be seen as a probabilistic extension to deterministic optimization. Here, we can also account for and optimize our risk when dealing with real-world uncertainty.
In fact, real-world complexity is worlds beyond our little ice-cream example. Consider yourself what this means for the likelihood that reality will diverge from your point forecasts.
2) Many small bets are safer than a few large ones
Back to the flawed roulette table, imagine that the probability of 0 is slightly higher than expected. Would you place all your chips on 0 in a single run or place small amounts on it for many rounds?
If you are unlucky, even the smallest possible bet size could lead you into bankruptcy. The chances of this happening are, nevertheless, much larger if you go all-in in a single turn. While it is beyond this article to discuss proper bet sizing, the Kelly criterion might be a useful start.
In practice, this could mean going from monthly forecasts to daily forecasts. That is of course a very simplistic recommendation. Subject to other factors, daily forecasts might still be less accurate or not useful at all. At this point, yours and your stakeholder’s expertise are necessary to find the right balance.
3) Sometimes, it’s better not to play the game at all
Let’s face it, there are always situations where you can only lose in the long run. If the signal-to noise ratio of your time-series is too low, it can be impossible to provide useful predictions.
Hedge funds with very deep pockets are paying absurd sums of money for alternative data. All that just to make their forecasts a tiny bit more accurate than that of their competitors. Unless you have access to the same data (if it is even good at all), you are unlikely to consistently outperform them on the same bets.
In case you have reached this point, you might want to look for new data to improve your forecasts. If that doesn’t help either, it could even make sense to rely on respective forecasts altogether.
Create multiple point forecasts of relevant summary statistics
Instead of focusing on forecasting mean via MSE-minimzation (or median through MAE-minimization), you could predict other quantities that describe your distribution.
In Example 1, the most obvious would be conditional variance You can find a short overview on how to forecast conditional variance in this article.
Once your model predicts a period of high variance, you could decide to play it safer. What ‘playing it safe’ means is obviously depending on the context of your forecasting problem.
Example 2 might also benefit from a conditional variance forecast. However, notice that conditional skewness is also playing a role here. One approach to deal with this situation might be a forecast of conditional quantiles, i.e. This is known as quantile regression and, e.g., sklearn’s GradientBoostingRegressor actually implements the respective loss.
Which quantities you should choose will ultimately depend on your specific problem. The biggest advantage here is that you don’t make any assumptions about the underlying distribution. Rather, you just let your model ‘learn’ the important aspects of the distribution that you care about.
On the other hand, it will be difficult to perform stochastic optimization with this approach. After, all you just compress the most relevant information into a several point forecasts. If you want to calculate the formally best decision given some forecast, you will therefore likely have to
Replace your point forecast by a probabilistic forecast
The most challenging but also the most holistic approach. As we saw, the success of probabilistic methods often depends on the probability distribution you choose.
Technically, non-parametric and ML methods can learn a probability distribution from the data, too. Keep in mind though, that time-series problems often involve much fewer observations than your typical ML use-case. As a result, these approaches can easily fall prey to overfitting here.
Especially if you are a Python user, you will probably have to implement many models yourself. Contrary to R, the Python ecosystem around forecasting seems to be much more focused on point forecasts. In case you only need a SARIMAX-like solution, statsmodels will, however, be your friend.
Below, I also summarized the three different approaches to forecasting that we have discussed so far. Keep in mind that there are advantages and disadvantages to all three.

Conclusion
Hopefully, you now have a better idea of the pitfalls of point forecasts. While point forecasts are not bad per se, they just show you an incomplete picture of what is happening in an uncertain world.
On the other hand, probabilistic forecasts offer a much richer perspective on the future of a given time-series. If you need a sound approach to handle the uncertainty of real-world complex systems, this is the way to go. Keep in mind, though, that this route will require more manual effort in many situations.
References
[1] Hamilton, James Douglas. Time series analysis. Princeton university press, 2020.
[2] Hyndman, Rob J., & Athanasopoulos, George. Forecasting: principles and practice. OTexts, 2018.
Executive summary by ChatGPT
Probabilistic forecasts are a more comprehensive way to predict future events compared to point forecasts. Probabilistic forecasts involve creating a model that predicts the entire probability distribution for a given future period, providing insight into all likely outcomes.
This allows for the derivation of both point and interval forecasts. Point forecasts are easier to communicate to non-technical stakeholders, but probabilistic forecasts provide a more complete picture of potential outcomes.
Probabilistic forecasts can also be used to answer questions about hitting times, or the first time a time-series enters a given subset of observation space. Hitting time probabilities are difficult to calculate analytically, but can be answered using Monte Carlo simulation with a probabilistic model.
Introduction
In Data Science, forecasting often involves creating the best possible model for predicting future events. Usually, the “best” model is one that minimizes a given error metric such as the Mean-Squared Error (MSE). The end result is then a list of values that depicts the predicted trajectory of the time-series. A statistician or econometrician would call this a point forecast.
More traditional forecasting models, typically forecast the whole probability distribution for a given future period. We will call those probabilistic forecasts from here on.
One amenity of probabilistic forecasts is the ability to derive both point forecasts and interval forecasts. Think of the latter as a time-series analogue of a confidence interval applied to a forecast.
Certainly, a point forecast is considerably easier to communicate to non-technical stakeholders. Who wants to deal with all likely outcomes - give me a single metric to base my decisions on!
Now, there is definitely a real risk of overly complicated solutions ending up your company’s drawer. Nevertheless, we should not reduce complexity too much, either, just to please our non-technical end users.
As an example, let us take a look at hitting time problems. This is a rather uncommon topic in your standard Data Science curriculum. Nevertheless, it is quite useful.
Hitting times and hitting time probabilities
For our purposes, we go with a very intuitive definition: A hitting time is simply the first time that out time-series enters some subset of observation space. Mathematically, where
and we presume that the time-series has realizations in the real numbers. The latter is not a necessary requirement but makes the problem a little more tangible.
One possible question we can ask is when the process exceeds a given threshold for the first time. The subset that we are interested in that case is with
the threshold of interest. Now, when we are talking about a hitting time probability, we want to know the probability distribution over the hitting time, i.e.
For a continuous-time time-series, p is usually a probability density.. As most time-series problems in Data Science are discrete, though, let us also concentrate on that case. Consequently, p is a probability mass function which is usually easier to handle.
Unfortunately, hitting time probabilities are hard to calculate analytically and often intractable.
Luckily, a probabilistic model can answer hitting time questions via Monte-Carlo simulation. We will look at this approach further down below.
At first, the idea of hitting time probability might look like a nice toy problem with little practical relevance. However, consider even a simple capacity planning problem. A company might have to decide when to expand their operational capacity due to increased demand.
On the one hand, this can certainly be answered by a point forecast to some extent. Just pick the timestamp where you forecast exceeds the threshold as your predicted hitting time. If a point forecast was sufficient in the first place, a ‘point forecast’ of the hitting time will surely work fine, too.
Let us see what happens in a simple example:
Hitting time probabilities in the wild
To keep it simple, we use the good old Air Passengers dataset. Keep in mind that a single experiment is far from sufficient to draw any generalizing conclusions.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("../data/AirPassengers.csv")
df.index = pd.to_datetime(df["Month"])
y = df["#Passengers"]
plt.figure(figsize = (16,6))
plt.plot(y,label = "#Passengers")
plt.grid(alpha = 0.5)
plt.title("AirPassengers.csv")
plt.legend();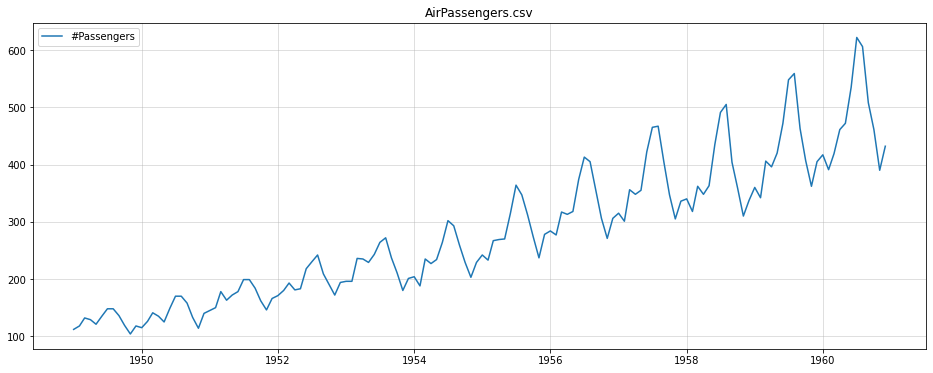
While the data is heavily outdated, it is simplistic enough to help us make a point quickly.
Hitting time point predictions
First let us consider how to solve the hitting time problem using a standard point forecast. In the end, we can only determine when our forecast hits a certain threshold deterministically.
Here, I chose the arbitrary threshold of 550 passengers. For a fictitious airline company behind the data, this could give an important clue for when to increase fleet capacity.
For the point forecast approach, the procedure is now straightforward:
- Fit an arbitrary time-series model (Here we’ll use a SARIMAX (12,1,1,1) model to capture trend and yearly seasonality).
- Forecast over a horizon that is sufficiently long for the time-series to exceed the given threshold.
- Mark the timestamp where the forecast exceeds the threshold for the first time as your hitting time.
With statsmodels.tsa.sarimax.SARIMAX, this looks as follows:
from statsmodels.tsa.statespace.sarimax import SARIMAX
import numpy as np
y_train = y.iloc[:-36]
y_test = y.iloc[-36:]
model = SARIMAX(endog = y_train,
order = (1,1,1),
seasonal_order=(0,1,0,12)).fit(disp=0)
point_forecast = model.forecast(36)
plt.figure(figsize=(16,6))
plt.plot(y_test, label="Out-of-sample data")
plt.plot(point_forecast, label="SARIMAX point forecast")
plt.axvline(point_forecast.index[np.argmax(point_forecast>=550)], color="red", label="Point forecast hitting time")
plt.grid(alpha=0.5)
plt.title("Hitting time via point forecast")
plt.legend();/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/statsmodels/tsa/base/tsa_model.py:471: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/statsmodels/tsa/base/tsa_model.py:471: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
self._init_dates(dates, freq)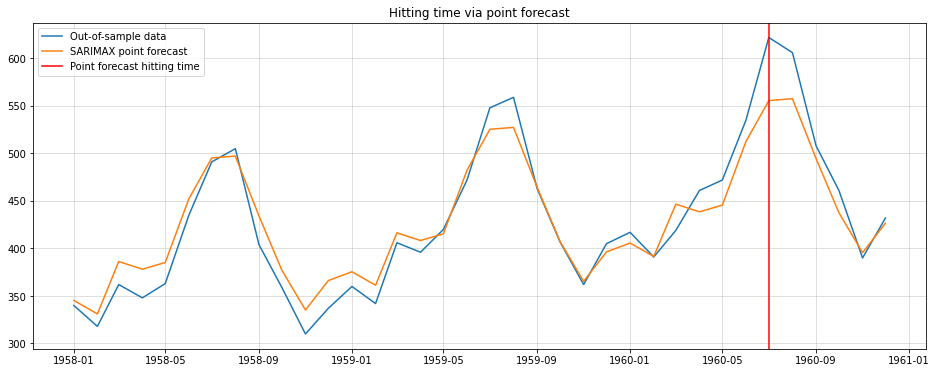
Looking at the out-of-sample set in hindsight, we see that our hitting time forecast was one year late. In a real-world application, being one year late could be arbitrarily bad for your business case.
As we will see, the probabilistic variant gives a much more complete picture. Unfortunately, we cannot calculate the respective probability mass function in closed form.
Monte-Carlo estimation of hitting time probabilities
Luckily, statsmodels’ SARIMAX provides both mean and standard deviation forecasts. As the forecast distribution is Gaussian, we can use that knowledge for a Monte-Carlo simulation. From there, we can estimate the probability for each month being the hitting time for C=550:
import numpy as np
from scipy.stats import norm
means = model.get_forecast(100).predicted_mean
stds = model.get_forecast(100).se_mean
np.random.seed(123)
hits = [np.argmax(norm(means,stds).rvs()>=550) for _ in range(10000)]
hit_dates = [means.index[hit] for hit in hits]
probs = pd.Series(hit_dates).value_counts()/10000
plt.figure(figsize=(16,6))
plt.bar(probs.index, probs.values,width=12, label = "Forecasted hitting time probabilities")
plt.axvline(means.index[int(np.mean(hits))], color="purple",label = "Approx. mean hitting time", lw=4, ls="dashed")
plt.axvline(means.index[np.argmax(model.forecast(36)>=550)],color="red", label = "Point forecast hitting time", lw=4, ls="dashed")
plt.axvline(means.index[np.argmax(y_test>=550)],color="green", label = "Actual hitting time (y>=550)", lw=4, ls="dashed")
plt.grid(alpha = 0.5)
plt.title("Hitting time probabilities via probabilistic forecast")
plt.legend();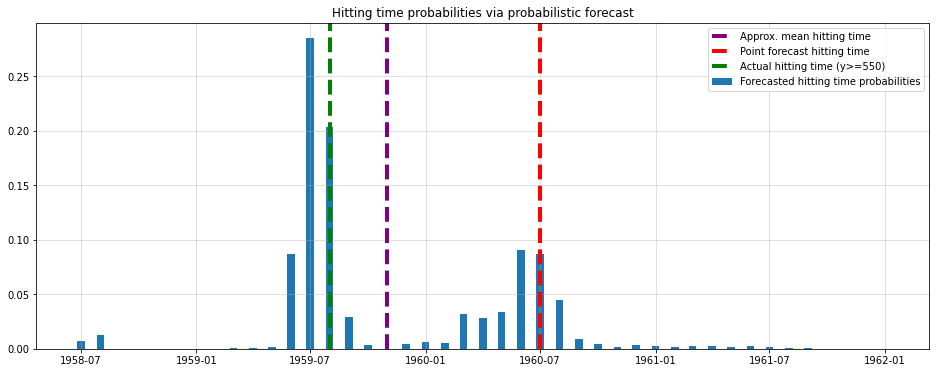
This looks much better. Our model predicts that the time-series will is most likely to exceed the threshold one year before the point forecast prediction. The hindsight data also agrees much better with this prediction.
Additionally, we see that the point forecast hitting time (red line) is not the expectation (purple line) of the probabilistic variant either. This is significant in so far as the point forecast of the actual time-series is in fact the mean of the probabilistic forecast.
Due to the underlying dynamic of SARIMAX, however, this does not translate to the mean hitting time.
Finally, let us look at the Cumulative Distribution Function of our mass function estimate:
plt.figure(figsize=(16,6))
plt.plot(probs.sort_index().cumsum(), lw=3, label="Hitting time probability c.d.f.")
plt.grid(alpha = 0.5)
plt.legend()
plt.title("Cumulative distribution of hitting time probabilities");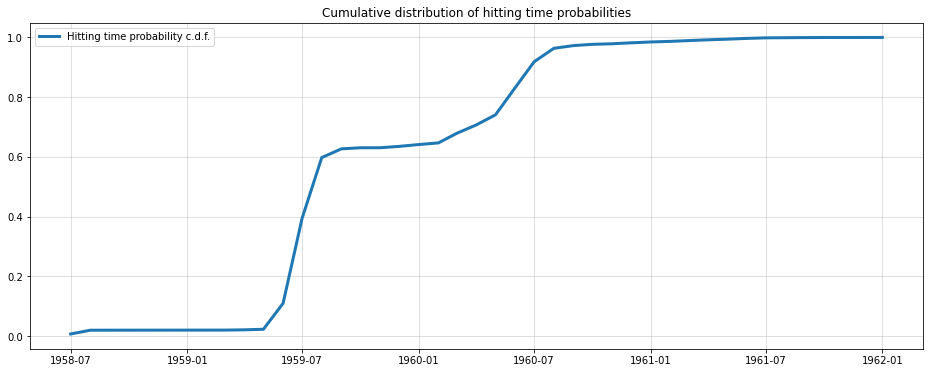
Here, the probability of threshold exceedance is already beyond 60% by the second year and not the third. Another reason why the point forecast hitting time is inappropriate.
Conclusion
While working with point forecasts is often more convenient, such complexity reduction can be too much in some instances. Even in this rather simple example, the ‘simple’ approach was already off by one year.
Certainly, your particular hitting time problem might allow you to go the straightforward route. Keep in mind, however, that you will only be able to judge quality of your forecast after the fact. By then it will obviously be too late to switch to the more sophisticated but also more holistic approach discussed above.
In the end, a probabilistic forecast can always be reduced to a single point-forecast. Vice-versa, this is unfortunately not the case. Personally, I can more than recommend the probabilistic route as there are many other advantages to it.
In future articles, I am planning to provide more insights about those other advantages. If you are interested, feel free to subscribe to get notified by then.
References
[1] Bas, Esra. Basics of Probability and Stochastic Processes. Springer International Publishing, 2019.
[2] Hamilton, James Douglas. Time series analysis. Princeton university press, 2020.
[3] Hyndman, Rob J., and George Athanasopoulos. Forecasting: principles and practice. OTexts, 2018.
Introduction
In the last article, we discussed how Decision Trees and Random Forests can be used for forecasting. While mean and point forecasts are the most obvious applications, they might not always be the most useful ones.
Consider the classic example of financial returns, where the conditional mean is hard, if not impossible, to predict. Conditional variance on the other hand has been shown to exert some auto-regressive properties that can be modelled. In fact there exist countless models from the (G)ARCH-family that enjoy widespread popularity.
Most GARCH models make primarily linear assumptions about the auto-regressive patterns. This begs the question if we can introduce non-linear relationships for more flexibility. Given the promising performance of tree models for mean forecasts, the roadmap is clear. Can we build respective models for variance forecasts?
Conditional variance and modelling options
Although there exists a lot of information on conditional variance models on the internet, let us quickly walk through the basics. For more insights, feel free to study the references in the GARCH wikipedia article. Alternatively, you might also get some additional insights from these two articles here and here.
To get started, we state our forecast target: Pretty simple - we want to predict variance of a time-series based on the series’ past realizations. There is only one problem: We do not observe the time-series’ variance.
Of course, this is also true when for the time-series’ mean. However, by minimizing the mean-squared-error, our model will generate predictions for the mean (a.k.a. expected value). In a time-series modelling problem, this looks as follows:
the set of all admissible models
In words: A model that minimizes the MSE of the conditionals can be used as an estimator for the conditional mean. Of course, this requires the set of admissible models to be large enough. A linear model, for example, will fail as an approximation for a highly non-linear conditional mean.
Luckily, Decision Tree ensembles are very flexible and thus should make a decent set of candidate models.
Now hopes are up that there exists a suitable loss function that will find a similar estimator for conditional variances. Indeed there is a very convenient way:
Estimating Variance directly
This approach requires only a tiny bit of probability theory and a loose assumption on our data. Recall that the variance of any random variable can be decomposed as follows: Notice that the expectation on the right can be estimated via the MSE minimization from before. Thus, with a respective estimator (e.g. Decision Tree ensemble), we can make use of the next formula:
Obviously, we don’t observe the actual conditional mean but only have our tree-based estimator at hand. Therefore:
Plugging this back into the variance formula, we get:
This implies that the variance of our target variable equals the expectation of the squared mean-transformed variable.
Notice that we conditioned the transformed variable on the lagged original time-series. We can equally condition the transformed variable on the lagged transformed time-series. The latter is obviously much more convenient and popular. Thus, we’ll use this approach from now on.
Going back to our first equation, we can now easily build an estimator for this mean: We can now conclude the following:
If we train another model to minimize MSE on the squared transformed variable, that model becomes an estimator for the conditional variance.
Obviously, this method has one caveat: The model must only produce non-negative predictions. Otherwise, there is no guarantee that we won’t receive negative variance predictions on a test set.
This is where Decision Trees and Random Forests come in handy. The squared data for training is always non-negative. Therefore, a trained Decision Tree will only produce non-negative predictions, too.
A raw linear regression model on the other hand would not have such guarantees. Unfortunately, this also excludes Gradient Boosted Trees from the range of possible models. Standard Boosting produces a weighted sum of Decision Trees. Consequently, a single negative weight could result in negative predictions.
There is, nevertheless, a way to make Gradient Boosting work as well:
Using an adjusted loss function
Since Gradient Boosting is so powerful, it would be a bummer to not be able to use it for our problem. Luckily, most popular Boosting libraries allow to define custom loss functions. This is exactly what we will do here.
Consider again the mean-subtracted variable: As a result we can impose the following distributional assumption:
The output from a Gradient Boosting algorithm itself can be negative. Adding exponentiation ensures non-negative variance. Now we simply need to translate the above into a log-likelihood loss function and calculate gradient and hessian. Then we plug everything into a Boosting algorithm:
Keep in mind that we need to apply the chain-rule to our additional exponential transformation.For Microsoft’s LightGBM package, our custom loss would now look as follows:
#see e.g. https://hippocampus-garden.com/lgbm_custom/
def gaussian_loss(y_pred, data):
y_true = data.get_label()
loglikelihood = -0.5*np.log(2*np.pi) - 0.5*y_pred - 0.5/np.exp(y_pred)*y_true**2
#remember that boosting minimizes the loss function but we want to maximize the loglikelihood
#thus, need to return the negative loglikelihood to the Boosting algorithm
#also applies to gradient and hessian below
return "loglike", -loglikelihood, False
def gaussian_loss_gradhess(y_pred, data):
y_true = data.get_label()
exp_pred = np.exp(y_pred)
#pay attention to the chain rule as we exp() the Boosting output before plugging it into the loglikelihood
grad = -0.5 + 0.5/exp_pred*y_true**2
hess = -0.5/exp_pred*y_true**2
return -grad, -hessNow, let us implement both approaches and compare them against benchmark models:
Tree ensembles for volatility forecasts in Python
In general, the implementation should be straightforward. Apart from avoiding careless mistakes, there is nothing too special that be need to be aware of.
As a dataset, we’ll use five years of standardized Dow Jones log-returns:
import pandas as pd
import numpy as np
import yfinance as yf
import matplotlib.pyplot as plt
symbol = "^DJI"
data = yf.download(symbol, start="2017-10-01", end="2022-10-01")
returns = np.log(data["Close"]).diff().dropna()
n_test = 30
train = returns.iloc[:-n_test]
train_mean = train.mean()
train_std = train.std()
train = (train-train_mean)/train_std
test = returns.iloc[-n_test:]
test = (test-train_mean)/train_std #be careful to spill information over into the test period
plt.figure(figsize = (16,6))
plt.plot(train, color = "blue", label = "Train data")
plt.plot(test, color = "red", label = "Test data")
plt.grid(alpha = 0.5)
plt.margins(x=0)
plt.legend()[*********************100%***********************] 1 of 1 completed
Notice that we are performing a z-Normalization. This will make the subsequent GARCH model more robust to degenerate scaling of the time-series. Also, we reserve the last 30 days of data for a test set. Be careful not to introduce lookahead bias here.
Finally, it is reasonable to presume that conditional expected returns are always zero, i.e. Otherwise, somebody else would have likely discovered this anomaly before us and arbitraged it away. Therefore, we don’t need to apply the mean-subtraction in the first place. Rather, we’ll directly use raw log-returns for our variance estimation.
Random Forest volatility forecasts
For the Random Forest model, we use [sklearn's](https://scikit-learn.org/stable/?ref=sarem-seitz.com) RandomForestRegressor. To limit the risk of overfitting, we run the algorithm with a max_depth=3. Given the typically noisy behaviour of financial time-series, such regularization seems reasonable.
Finally, we set k=5 which lets our algorithm consider the past five observations for forecasting. While we could set this lower or higher, there is a tradeoff between omitting information and overfitting. In production, you would obviously do more backtesting to find the optimal number of lags.
In code, we now have
from sklearn.ensemble import RandomForestRegressor
n_lags = 5
train_lagged = pd.concat([train**2]+[train.shift(i) for i in range(1,n_lags+1)],1).dropna()
y_train = train_lagged.iloc[:,0]
X_train = train_lagged.iloc[:,1:]
forest_model = RandomForestRegressor(max_depth=3, n_estimators=100, n_jobs=-1, random_state=123)
forest_model.fit(X_train.values, y_train.values)/var/folders/2d/hl2cr85d2pb2kfbmsng3267c0000gn/T/ipykernel_70730/2717592527.py:5: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only.
train_lagged = pd.concat([train**2]+[train.shift(i) for i in range(1,n_lags+1)],1).dropna()RandomForestRegressor(max_depth=3, n_jobs=-1, random_state=123)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestRegressor(max_depth=3, n_jobs=-1, random_state=123)
To generate forecasts, we apply Monte-Carlo sampling. Then, we use those samples to estimate the 90% forecast interval. This is necessary because our model can only predict conditional variance one step ahead. Presuming Gaussian noise, this looks as follows:
from scipy.stats import norm
samp_size = 50000
Xt = pd.DataFrame(pd.concat([train.shift(i) for i in range(n_lags)],1).dropna().iloc[-1,:].values.reshape(1,-1))
Xt = pd.concat([Xt for _ in range(samp_size)])
Xt.columns = X_train.columns
np.random.seed(123)
forest_samples = []
for t in range(len(test)):
pred = forest_model.predict(Xt.values).reshape(-1,1)
samp = norm(0, 1).rvs(samp_size).reshape(-1,1)*np.sqrt(pred)
forest_samples.append(samp)
Xt = pd.DataFrame(np.concatenate([np.array(samp).reshape(-1,1),Xt.values[:,:-1]],1))
Xt.columns = X_train.columns
forest_samples_matrix = np.concatenate(forest_samples,1)
forest_std = np.std(forest_samples_matrix,0)
forest_lower = np.quantile(forest_samples_matrix,0.05,0)
forest_upper = np.quantile(forest_samples_matrix,0.95,0)/var/folders/2d/hl2cr85d2pb2kfbmsng3267c0000gn/T/ipykernel_70730/1944271020.py:5: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only.
Xt = pd.DataFrame(pd.concat([train.shift(i) for i in range(n_lags)],1).dropna().iloc[-1,:].values.reshape(1,-1))50000 samples per timestamp should suffice for now. If you need more accuracy, feel free to increase this amount by a lot.
Gradient Boosting volatility forecasts
The Gradient Boosting variant is quite similar to the Random Forest approach. We only need to take care of the LightGBM-specifics for data preprocessing. Also keep in mind that our target now needs to be the raw, z-normalized time-series, not the squared one.
import lightgbm as lgb
train_lagged = pd.concat([train]+[train.shift(i) for i in range(1,n_lags+1)],1).dropna()
y_train = train_lagged.iloc[:,0]
X_train = train_lagged.iloc[:,1:]
train_data = lgb.Dataset(X_train.values, label=y_train.values)
param = {"num_leaves":2, "learning_rate":0.1, "seed": 123}
num_round = 1000
boosted_model = lgb.train(param, train_data, num_round, fobj=gaussian_loss_gradhess, feval=gaussian_loss)
np.random.seed(123)
boosted_samples = []
for t in range(len(test)):
pred = boosted_model.predict(Xt.values).reshape(-1,1)
samp = norm(0, 1).rvs(samp_size).reshape(-1,1)*np.sqrt(np.exp(pred))
boosted_samples.append(samp)
Xt = pd.DataFrame(np.concatenate([np.array(samp).reshape(-1,1),Xt.values[:,:-1]],1))
Xt.columns = X_train.columns
boosted_samples_matrix = np.concatenate(boosted_samples,1)
boosted_std = np.std(boosted_samples_matrix,0)
boosted_lower = np.quantile(boosted_samples_matrix,0.05,0)
boosted_upper = np.quantile(boosted_samples_matrix,0.95,0)/var/folders/2d/hl2cr85d2pb2kfbmsng3267c0000gn/T/ipykernel_70730/729234487.py:3: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only.
train_lagged = pd.concat([train]+[train.shift(i) for i in range(1,n_lags+1)],1).dropna()[LightGBM] [Warning] Using self-defined objective function
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000495 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 1275
[LightGBM] [Info] Number of data points in the train set: 1223, number of used features: 5
[LightGBM] [Warning] Using self-defined objective functionTo check if our models are actually any good, let us compare them against two benchmarks:
GARCH and kernel density benchmarks and evaluation
Since we want to improve conditional volatility forecasts, GARCH seems to be the most obvious comparison. To match the number of lags in our tree ensembles, we’ll use a GARCH(5,5) model.
As a second benchmark, let us use a simple i.i.d. kernel density fit. I.e. we presume that each future observation is drawn independently from the same density as the training data:
from arch import arch_model
from scipy.stats import gaussian_kde
am = arch_model(train, p=n_lags,q=n_lags)
res = am.fit(update_freq=5)
forecasts = res.forecast(horizon=len(test), reindex=False).variance.values[0,:]
garch_samples_matrix = res.forecast(horizon=len(test), simulations = 50000, reindex=False, method = "simulation").simulations.values[0,:,:]
garch_std = np.std(garch_samples_matrix,0)
garch_lower = np.quantile(garch_samples_matrix,0.05,0)
garch_upper = np.quantile(garch_samples_matrix,0.95,0)
iid_kde = gaussian_kde(train)
iid_kde_samp = iid_kde.resample((50000*len(test))).reshape(50000,len(test))
kde_lower = np.quantile(iid_kde_samp,0.05,0)
kde_upper = np.quantile(iid_kde_samp,0.95,0)Iteration: 5, Func. Count: 75, Neg. LLF: 1688.2522911700148
Iteration: 10, Func. Count: 145, Neg. LLF: 1524.6402966915884
Iteration: 15, Func. Count: 216, Neg. LLF: 1306.756160681614
Iteration: 20, Func. Count: 281, Neg. LLF: 1306.5361795921172
Optimization terminated successfully (Exit mode 0)
Current function value: 1306.5361512322356
Iterations: 23
Function evaluations: 320
Gradient evaluations: 23At last, the actual evaluation. As a performance measure, we want to use the out-of-sample log-likelihood - the higher the better. That way we will see which forecasted probability density performs best on our test set.
Since we could only sample from the forecast distributions, we’ll fit a kernel density to each of the Monte-Carlo samples. For our benchmark, we obviously have the kernel density fit from the training data already.
Finally, we calculate the log-likelihood for the kernel densities as a proxy:
benchmark_lpdfs = [iid_kde.logpdf(test[i])[0] for i in range(len(test))]
garch_lpdfs = [gaussian_kde(garch_samples_matrix[:,i]).logpdf(test[i])[0] for i in range(len(test))]
forest_lpdfs = [gaussian_kde(forest_samples_matrix[:,i]).logpdf(test[i])[0] for i in range(len(test))]
boosted_lpdfs = [gaussian_kde(boosted_samples_matrix[:,i]).logpdf(test[i])[0] for i in range(len(test))]
fig, (ax1,ax2,ax3,ax4) = plt.subplots(4,1,figsize=(19,18))
st = fig.suptitle("Symbol: "+symbol, fontsize=20)
ax1.plot(train.iloc[-50:], color = "blue", label = "Last 50 observations of training set")
ax1.plot(test, color = "red", label = "Test set")
ax1.grid(alpha = 0.5)
ax1.margins(x=0)
ax1.fill_between(test.index, forest_lower, forest_upper, color="orange", alpha=0.5, label="Random Forest ARCH - 90% forecast interval")
ax1.legend()
ax1.set_title("Random Forest ARCH - Test set loglikelihood: {}".format(str(np.sum(forest_lpdfs))[:7]), fontdict={'fontsize': 15})
ax2.plot(train.iloc[-50:], color = "blue", label = "Last 50 observations of training set")
ax2.plot(test, color = "red", label = "Test set")
ax2.grid(alpha = 0.5)
ax2.margins(x=0)
ax2.fill_between(test.index, boosted_lower, boosted_upper, color="orange", alpha=0.5, label="Boosted Tree ARCH - 90% forecast interval")
ax2.legend()
ax2.set_title("Gradient Boosting ARCH - Test set loglikelihood: {}".format(str(np.sum(boosted_lpdfs))[:7]), fontdict={'fontsize': 15})
ax3.plot(train.iloc[-50:], color = "blue", label = "Last 50 observations of training set")
ax3.plot(test, color = "red", label = "Test set")
ax3.grid(alpha = 0.5)
ax3.margins(x=0)
ax3.fill_between(test.index, garch_lower, garch_upper, color="orange", alpha=0.5, label="GARCH (5,5) - 90% forecast interval")
ax3.legend()
ax3.set_title("GARCH(5,5)- Test set loglikelihood: {}".format(str(np.sum(garch_lpdfs))[:7]), fontdict={'fontsize': 15})
ax4.plot(train.iloc[-50:], color = "blue", label = "Last 50 observations of training set")
ax4.plot(test, color = "red", label = "Test set")
ax4.grid(alpha = 0.5)
ax4.margins(x=0)
ax4.fill_between(test.index, kde_lower, kde_upper, color="orange", alpha=0.5, label="I.i.d. Kernel Density - 90% forecast interval")
ax4.legend()
ax4.set_title("I.i.d. KDE - Test set loglikelihood: {}".format(str(np.sum(benchmark_lpdfs))[:7]), fontdict={'fontsize': 15})Text(0.5, 1.0, 'I.i.d. KDE - Test set loglikelihood: -46.681')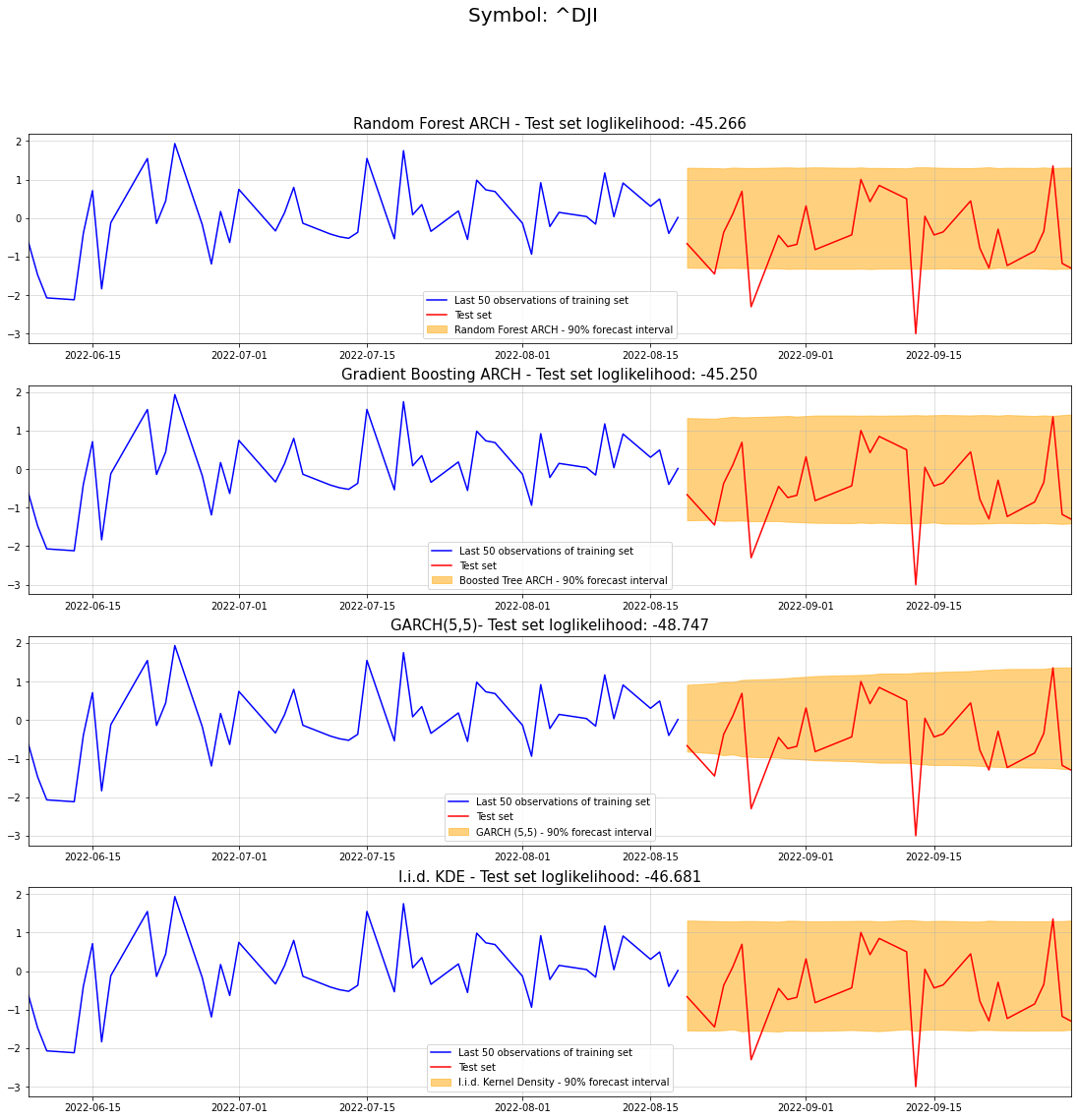
In fact, our tree models perform best for our 30 day test set. Surprisingly, the GARCH model performed worse than our kernel density benchmark. Keep in mind though that a single evaluation doesn’t allow any generalizing conclusions.
Nevertheless, our Random Forest and Gradient Boosting ARCH models appear to work reasonably well.
Conclusion
This article gave a quick demonstration of how tree ensembles can be used for volatility forecasts. Although the example models could possibly be enhanced a lot, the initial ideas already seem to work quite well.
Possible enhancement could be a better choice of conditional distributions. I.e. all our models, except the kernel density benchmark, worked with Gaussianity assumptions. In for financial time-series, this might obviously be a sub-optimal choice. If, for example, we wanted to account for heavy conditional tails, a Student’s T-distribution would be better suited.
References
[1] Breiman, Leo. Random forests. Machine learning, 2001, 45.1, p. 5-32.
[2] Bollerslev, Tim. Modelling the coherence in short-run nominal exchange rates: a multivariate generalized ARCH model. The review of economics and statistics, 1990, p. 498-505.
[3] Ke, Guolin, et al. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 2017, 30
Introduction
Today, Deep Learning dominates many areas of modern machine learning. On the other hand, Decision Tree based models still shine particularly for tabular data. If you look up the winning solutions of respective Kaggle challenges, chances are high that a tree model is among them.
A key advantage of tree approaches is that they typically don’t require too much fine-tuning for reasonable results. This is in stark contrast to Deep Learning. Here, different topologies and architectures can result in dramatical differences in model performance.
For time-series forecasting, decision trees are not as straightforward as for tabular data, though:
Challenges with trees and forests for forecasting
As you probably know, fitting any decision tree based methods requires both input and output variables. In a univariate time-series problem, however, we usually only have our time-series as a target.
To work around this issue, we need to augment the time-series to become suitable for tree models. Let us discuss two intuitive, yet false approaches and why they fail first. Obviously, the issues generalize to all Decision Tree ensemble methods.
Decision Tree forecasting as regression against time
Probably the most intuitive approach is to consider the observed time-series as a function of time itself, i.e. With some i.i.d. stochastic additive error term. In an earlier article, I have already made some remarks on why regression against time itself is problematic. For tree based models, there is another problem:
Decision Trees for regression against time cannot extrapolate into the future.
By construction, Decision Tree predictions are averages of subsets of the training dataset. These subsets are formed by splitting the space of input data into axis-parallel hyper rectangles. Then, for each hyper rectangle, we take the average of all observation outputs inside those rectangles as a prediction.
For regression against time, those hyper rectangles are simply splits of time intervals. More exactly, those intervals are mutually exclusive and completely exhaustive.
Predictions are then the arithmetic means of the time-series observations inside those intervals. Mathematically, this roughly translates to where
: training observations
Consider now using this model to predict the time-series at some time in the future. This reduces the above formula to the following:
In words: For any forecast, our model always predicts the average of the final training interval. Which is clearly useless…
Let us visualize this issue on a quick toy example:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
#create data with linear trend
np.random.seed(123)
t = np.arange(100)
y = t + 2 * np.random.normal(size = 100)#linear trend
t_train = t[:50].reshape(-1,1)
t_test = t[50:].reshape(-1,1)
y_train = y[:50]
y_test = y[50:]
tree = DecisionTreeRegressor(max_depth = 2)
tree.fit(t_train, y_train)
y_pred_train = tree.predict(t_train)
y_pred_test = tree.predict(t_test)
plt.figure(figsize = (16,8))
plt.plot(t_train.reshape(-1), y_train, label = "Training data", color="blue", lw=2)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_train[-1]],y_test]), label = "Test data",
color="blue", ls = "dotted", lw=2)
plt.plot(t_train.reshape(-1), y_pred_train, label = "Decision Tree insample predictions",
color="red", lw = 3)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_pred_train[-1]],y_pred_test]), label = "Decision Tree out-of-sample predictions",
color="purple", lw=3)
plt.grid(alpha = 0.5)
plt.axvline(t_train[-1], color="black", lw=2, ls="dashed")
plt.legend(fontsize=13)
plt.title("Decision Tree VS. Time-Series with linear trend", fontsize=15)
plt.margins(x=0)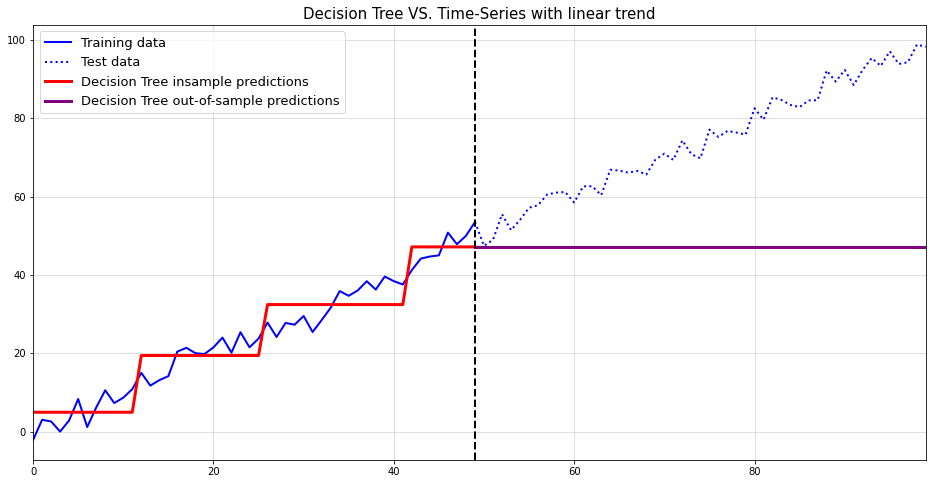
The same issues obviously arise for seasonal patterns as well:
#create data with seasonality
np.random.seed(123)
t = np.arange(100)
y = np.sin(0.5 * t) + 0.5 * np.random.normal(size = 100)#sine seasonality
t_train = t[:50].reshape(-1,1)
t_test = t[50:].reshape(-1,1)
y_train = y[:50]
y_test = y[50:]
tree = DecisionTreeRegressor(max_depth = 4)
tree.fit(t_train, y_train)
y_pred_train = tree.predict(t_train)
y_pred_test = tree.predict(t_test)
plt.figure(figsize = (16,8))
plt.plot(t_train.reshape(-1), y_train, label = "Training data", color="blue", lw=2)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_train[-1]],y_test]), label = "Test data",
color="blue", ls = "dotted", lw=2)
plt.plot(t_train.reshape(-1), y_pred_train, label = "Decision Tree insample predictions",
color="red", lw = 3)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_pred_train[-1]],y_pred_test]), label = "Decision Tree out-of-sample predictions",
color="purple", lw=3)
plt.grid(alpha = 0.5)
plt.axvline(t_train[-1], color="black", lw=2, ls="dashed")
plt.legend(fontsize=13)
plt.title("Decision Tree VS. Time-Series with seasonality", fontsize=15)
plt.margins(x=0)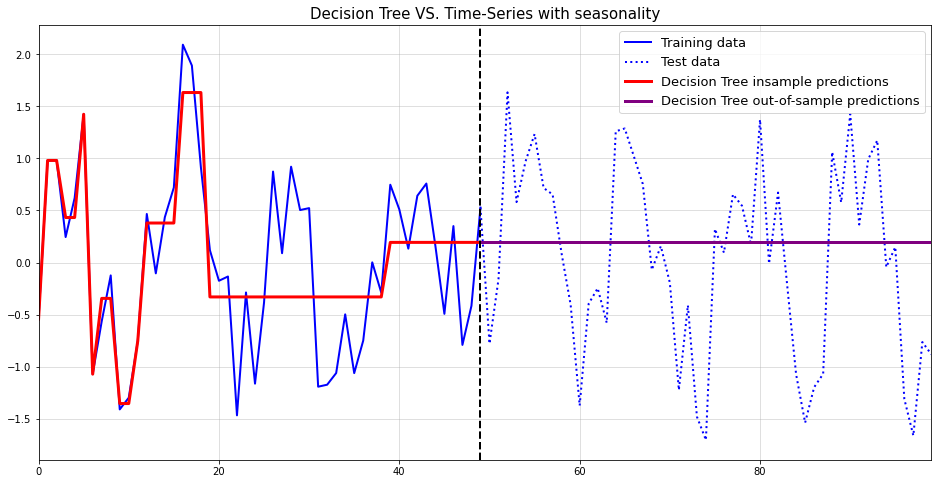
To generalize the above in a single sentence:
Decision Trees fail for out-of-distribution data but in regression against time, every future point in time is out-of-distribution.
Thus, we need to find a different approach.
Decision Trees for auto-regressive forecasting
A far more promising approach is the auto-regressive one. Here, we simply view the future of a random variable as dependent on its past realizations. While this approach is easier to handle than regression on time, it doesn’t come without a cost:
- The time-series must be observed at equi-distant timestamps: If your time-series is measured at random times, you cannot use this approach without further adjustments.
- The time-series should not contain missing values: For many time-series models, this requirement is not mandatory. Our Decision Tree/Random Forest forecaster, however, will require a fully observed time-series.
As these caveats are common for most popular time-series approaches, they aren’t too much of an issue.
Now, before jumping into an example, we need to take a another look at a previously discussed issue: Tree based models can only predict within the range of training data. This implies that we cannot just fit a Decision Tree or Random Forest to model auto-regressive dependencies.
To exemplify this issue, let’s do another example:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
import pandas as pd
#create data with linear trend
np.random.seed(123)
t = np.arange(100)
y = t + 2 * np.random.normal(size = 100)#linear trend
t_train = t[:50].reshape(-1,1)
t_test = t[50:].reshape(-1,1)
y_train = y[:50]
X_train_shift = np.concatenate([pd.Series(y_train).shift(t).values.reshape(-1,1) for t in range(1,6)],1)[5:,:]
y_train_shift = y_train[5:]
y_test = y[50:]
tree = DecisionTreeRegressor(max_depth = 2)
tree.fit(X_train_shift, y_train_shift)
y_pred_train = tree.predict(X_train_shift).reshape(-1)
Xt = np.concatenate([X_train_shift[-1,1:].reshape(1,-1),np.array(y_train_shift[-1]).reshape(1,1)],1)
predictions_test = []
for t in range(len(y_test)):
pred = tree.predict(Xt)
predictions_test.append(pred[0])
Xt = np.concatenate([Xt[-1,1:].reshape(1,-1),np.array(pred).reshape(1,1)],1)
y_pred_test = np.array(predictions_test)
plt.figure(figsize = (16,8))
plt.plot(t_train.reshape(-1), y_train, label = "Training data", color="blue", lw=2)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_train[-1]],y_test]), label = "Test data",
color="blue", ls = "dotted", lw=2)
plt.plot(t_train.reshape(-1)[5:], y_pred_train, label = "Decision Tree insample predictions",
color="red", lw = 3)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_pred_train[-1]],y_pred_test]), label = "Decision Tree out-of-sample predictions",
color="purple", lw=3)
plt.grid(alpha = 0.5)
plt.axvline(t_train[-1], color="black", lw=2, ls="dashed")
plt.legend(fontsize=13)
plt.title("Decision Tree VS. Time-Series with linear trend", fontsize=15)
plt.margins(x=0)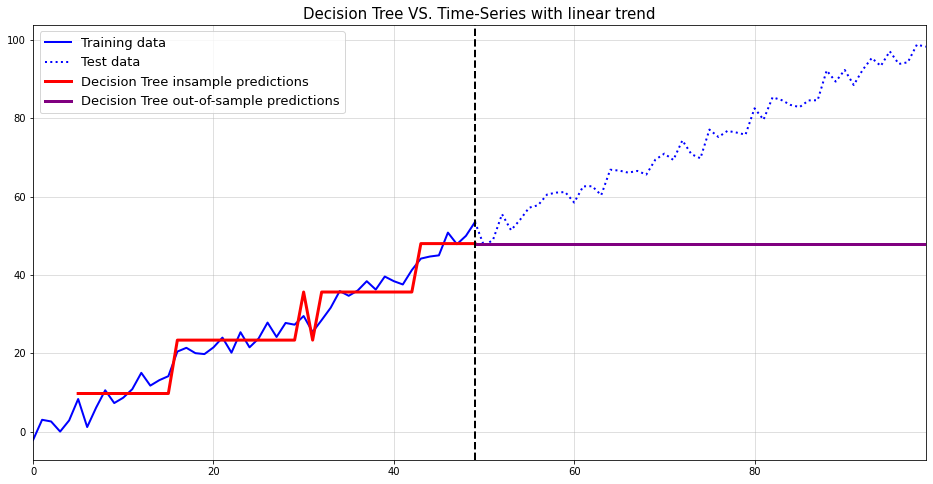
Again, not useful at all. To fix this last issue, we need to first remove the trend. Then we can fit the model, forecast the time-series and ‘re-trend’ the forecast.
For de-trending, we basically have two options:
- Fit a linear trend model - here we regress the time-series against time in a linear regression model. Its predictions are then subtracted from the training data to create a stationary time-series. This removes a constant, deterministic trend.
- Use first-differences - in this approach, we transform the time-series via first order differencing. In addition to the deterministic trend, this approach can also remove stochastic trends.
As most time-series are driven by randomness, the second approach appears more reasonable. Thus, we now aim to forecast the transformed time-series by an autoregressive model, i.e.
Obviously, differencing and lagging remove some observations from our training data. Some care should be taken to not remove too much information that way. I.e. don’t use too many lagged variables if your dataset is small.
To obtain a forecast for the original time-series we need to retransform the differenced forecast via and, recursively for further ahead forecasts:
For our running example this finally leads to a reasonable solution:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
#create data with linear trend
np.random.seed(123)
t = np.arange(100)
y = t + 2* np.random.normal(size = 100)#linear trend
t_train = t[:50].reshape(-1,1)
t_test = t[50:].reshape(-1,1)
n_lags = 10
y_train = y[:50]
X_train_shift = pd.concat([pd.DataFrame(y_train).shift(t) for t in range(1,n_lags)],1).diff().values[n_lags:,:]
y_train_shift = np.diff(y_train)[n_lags-1:]
y_test = y[50:]
tree = DecisionTreeRegressor(max_depth = 1)
tree.fit(X_train_shift, y_train_shift)
y_pred_train = tree.predict(X_train_shift).reshape(-1)
Xt = np.concatenate([X_train_shift[-1,1:].reshape(1,-1),np.array(y_train_shift[-1]).reshape(1,1)],1)
predictions_test = []
for t in range(len(y_test)):
pred = tree.predict(Xt)
predictions_test.append(pred[0])
Xt = np.concatenate([np.array(pred).reshape(1,1),Xt[-1,1:].reshape(1,-1)],1)
y_pred_test = np.array(predictions_test)
y_pred_train = y_train[n_lags-2]+np.cumsum(y_pred_train)
y_pred_test = y_train[-1]+np.cumsum(y_pred_test)
plt.figure(figsize = (16,8))
plt.plot(t_train.reshape(-1), y_train, label = "Training data", color="blue", lw=2)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_train[-1]],y_test]), label = "Test data",
color="blue", ls = "dotted", lw=2)
plt.plot(t_train.reshape(-1)[n_lags:], y_pred_train, label = "Decision Tree insample predictions",
color="red", lw = 3)
plt.plot(np.concatenate([np.array(t_train[-1]),t_test.reshape(-1)]),
np.concatenate([[y_pred_train[-1]],y_pred_test]), label = "Decision Tree out-of-sample predictions",
color="purple", lw=3)
plt.grid(alpha = 0.5)
plt.axvline(t_train[-1], color="black", lw=2, ls="dashed")
plt.legend(fontsize=13)
plt.title("Decision Tree VS. Time-Series with linear trend", fontsize=15)
plt.margins(x=0)/var/folders/2d/hl2cr85d2pb2kfbmsng3267c0000gn/T/ipykernel_67956/2778805950.py:16: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only.
X_train_shift = pd.concat([pd.DataFrame(y_train).shift(t) for t in range(1,n_lags)],1).diff().values[n_lags:,:]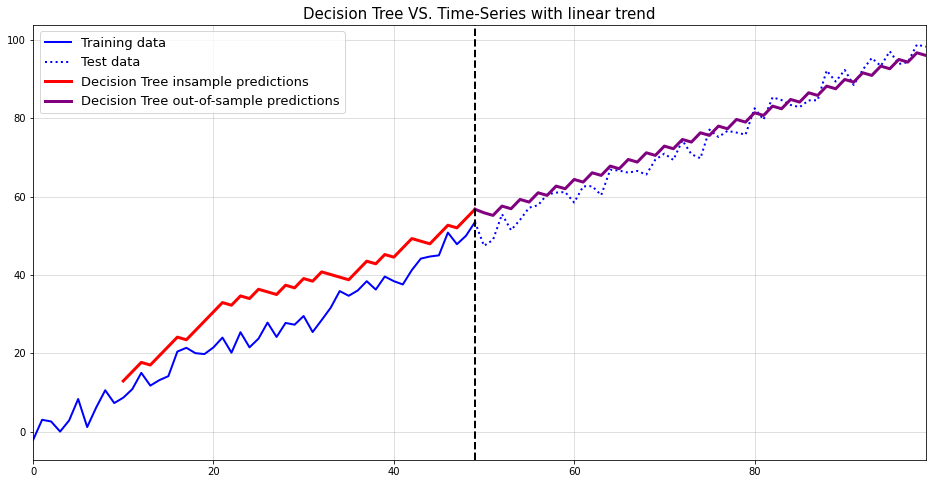
From trees to Random Forecast forecasts
Let us now apply the above approach to a real-world dataset. We use the alcohol sales data from the St. Louis Fed database. For evaluation, we use the last four years as a holdout set:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("../data/Alcohol_Sales.csv")
df.columns = ["date", "sales"]
df["date"] = pd.to_datetime(df["date"])
df = df.set_index("date")
df_train = df.iloc[:-48]
df_test = df.iloc[-48:]
plt.figure(figsize = (18,7))
plt.plot(df, label="Training data")
plt.plot(df_test, label = "Test data")
plt.grid(alpha=0.5)
plt.margins(x=0)
plt.title("Alcohol Sales")Text(0.5, 1.0, 'Alcohol Sales')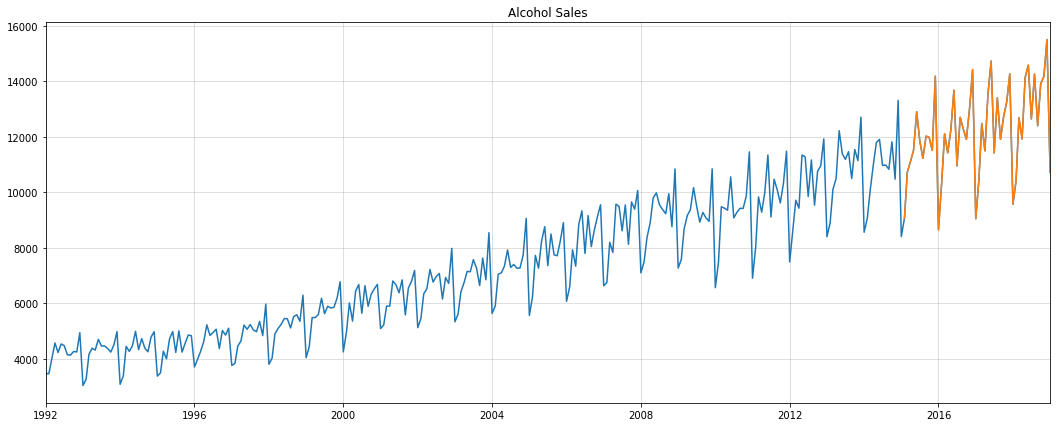
Growing an autoregressive Random Forest for forecasting
Since a single Decision Tree would be boring at best and inaccurate at worst, we’ll use a Random Forest instead. Besides the typical performance improvements, Random Forests allow us to generate forecast intervals.
To create Random Forest forecast intervals, we proceed as follows:
- Train an autoregressive Random Forest: This step is equivalent to fitting the Decision Tree as before
- Use a randomly drawn Decision Tree at each forecast step: Instead of just forest.predict(), we let a randomly drawn, single Decision Tree perform the forecast. By repeating this step multiple times, we create a sample of Decision Tree forecasts.
- Calculate quantities of interest from the Decision Tree sample: This could range from median to standard deviation or more complex targets. We are primarily interested in a mean forecast and the 90% predictive interval.
The following Python class does everything we need:
from sklearn.ensemble import RandomForestRegressor
from copy import deepcopy
class RandomForestARModel():
"""
Autoregressive forecasting with Random Forests
"""
def __init__(self, n_lags=1, max_depth = 3, n_estimators=1000, random_state = 123,
log_transform = False, first_differences = False, seasonal_differences = None):
"""
Args:
n_lags: Number of lagged features to consider in autoregressive model
max_depth: Max depth for the forest's regression trees
random_state: Random state to pass to random forest
log_transform: Whether the input should be log-transformed
first_differences: Whether the input should be singly differenced
seasonal_differences: Seasonality to consider, if 'None' then no seasonality is presumed
"""
self.n_lags = n_lags
self.model = RandomForestRegressor(max_depth = max_depth, n_estimators = n_estimators, random_state = random_state)
self.log_transform = log_transform
self.first_differences = first_differences
self.seasonal_differences = seasonal_differences
def fit(self, y):
"""
Args:
y: training data (numpy array or pandas series/dataframe)
"""
#enable pandas functions via dataframes
y_df = pd.DataFrame(y)
self.y_df = deepcopy(y_df)
#apply transformations and store results for retransformations
if self.log_transform:
y_df = np.log(y_df)
self.y_logged = deepcopy(y_df)
if self.first_differences:
y_df = y_df.diff().dropna()
self.y_diffed = deepcopy(y_df)
if self.seasonal_differences is not None:
y_df = y_df.diff(self.seasonal_differences).dropna()
self.y_diffed_seasonal = deepcopy(y_df)
#get lagged features
Xtrain = pd.concat([y_df.shift(t) for t in range(1,self.n_lags+1)],axis=1).dropna()
self.Xtrain = Xtrain
ytrain = y_df.loc[Xtrain.index,:]
self.ytrain = ytrain
self.model.fit(Xtrain.values,ytrain.values.reshape(-1))
def sample_forecast(self, n_periods = 1, n_samples = 10000, random_seed =123):
"""
Draw forecasting samples by randomly drawing from all trees in the forest per forecast period
Args:
n_periods: Ammount of periods to forecast
n_samples: Number of samples to draw
random_seed: Random seed for numpy
"""
samples = self._perform_forecast(n_periods, n_samples, random_seed)
output = self._retransform_forecast(samples, n_periods)
return output
def _perform_forecast(self, n_periods, n_samples, random_seed):
"""
Forecast transformed observations
Args:
n_periods: Ammount of periods to forecast
n_samples: Number of samples to draw
random_seed: Random seed for numpy
"""
samples = []
np.random.seed(random_seed)
for i in range(n_samples):
#store lagged features for each period
Xf = np.concatenate([self.Xtrain.iloc[-1,1:].values.reshape(1,-1),
self.ytrain.iloc[-1].values.reshape(1,1)],1)
forecasts = []
for t in range(n_periods):
tree = self.model.estimators_[np.random.randint(len(self.model.estimators_))]
pred = tree.predict(Xf)[0]
forecasts.append(pred)
#update lagged features for next period
Xf = np.concatenate([Xf[:,1:],np.array([[pred]])],1)
samples.append(forecasts)
return samples
def _retransform_forecast(self, samples, n_periods):
"""
Retransform forecast (re-difference and exponentiate)
Args:
samples: Forecast samples for retransformation
n_periods: Ammount of periods to forecast
"""
full_sample_tree = []
for samp in samples:
draw = np.array(samp)
#retransform seasonal differencing
if self.seasonal_differences is not None:
result = list(self.y_diffed.iloc[-self.seasonal_differences:].values)
for t in range(n_periods):
result.append(result[t]+draw[t])
result = result[self.seasonal_differences:]
else:
result = []
for t in range(n_periods):
result.append(draw[t])
#retransform first differences
y_for_add = self.y_logged.values[-1] if self.log_transform else self.y_df.values[-1]
if self.first_differences:
result = y_for_add + np.cumsum(result)
#retransform log transformation
if self.log_transform:
result = np.exp(result)
full_sample_tree.append(result.reshape(-1,1))
return np.concatenate(full_sample_tree,1)As our data is strictly positive, has a trend and yearly seasonality, we apply the following transformations:
- Logarithm transformation: Our forecasts then need to be re-transformed via an exponential transform. Thus, the exponentiated results will be strictly positive as well
- First differences: As mentioned above, this removes the linear trend in the data.
- Seasonal differences: Seasonal differencing works like first differences with higher lag orders. Also, it allows us to remove both deterministic and stochastic seasonality. The main challenge with all these transformations is to correctly apply their inverse on our predictions. Luckily, the above model has these steps implemented already.
Evaluating the Random Forest forecast
Using the data and the model, we get the following result for our test period:
model = RandomForestARModel(n_lags = 2, log_transform = True, first_differences = True, seasonal_differences = 12)
model.fit(df_train)
predictions_forest = model.sample_forecast(n_periods=len(df_test), n_samples=10000)
means_forest = np.mean(predictions_forest,1)
lowers_forest = np.quantile(predictions_forest,0.05,1)
uppers_forest = np.quantile(predictions_forest,0.95,1)
plt.figure(figsize = (18,7))
plt.grid(alpha=0.5)
plt.plot(df.iloc[-120:], label = "Training observations (truncated)")
plt.plot(df_test, color = "blue", label = "Out-of-sample observations", ls="dashed")
plt.plot(df_test.index,means_forest,color="purple", label = "RF mean forecast")
plt.fill_between(df_test.index, lowers_forest, uppers_forest, color="purple", alpha=0.5, label = "RF 90% forecast inverval")
plt.legend(fontsize=13)
plt.margins(x=0)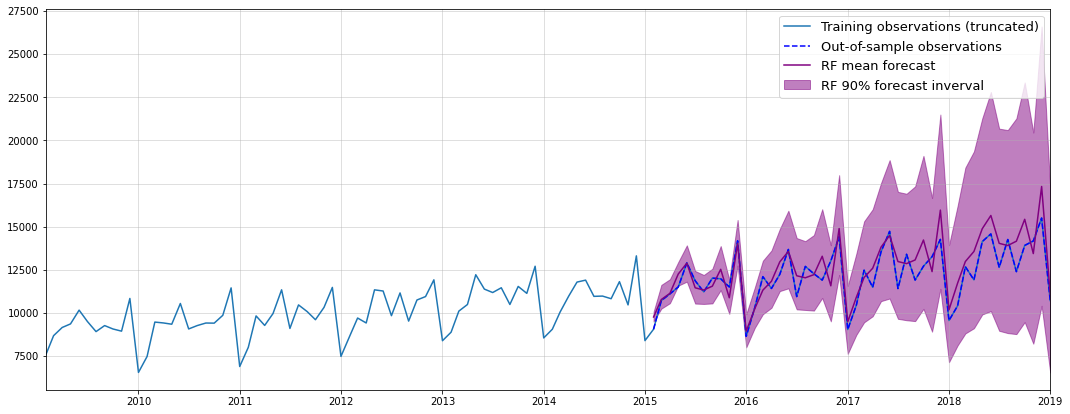
This looks quite good. To verify that we were not just lucky, we use a simple benchmark for comparison:
from scipy.stats import gaussian_kde
df_train_diffed = np.log(df_train["sales"]).diff().dropna()
df_train_trans = df_train_diffed.diff(12).dropna()
kde = gaussian_kde(df_train_trans.values)
target_range = np.linspace(np.min(df_train_trans.values)-0.5,np.max(df_train_trans.values)+0.5,num=100)
full_sample_toy = []
np.random.seed(123)
for i in range(10000):
draw = kde.resample(len(df_test)).reshape(-1)
result = list(df_train_diffed.iloc[-12:].values)
for t in range(len(df_test)):
result.append(result[t]+draw[t])
full_sample_toy.append(np.exp(np.array((np.log(df_train.values[-1])+np.cumsum(result[12:]))).reshape(-1,1)))
predictions_toy = np.concatenate(full_sample_toy,1)
means_toy = np.mean(predictions_toy,1)
lowers_toy = np.quantile(predictions_toy,0.05,1)
uppers_toy = np.quantile(predictions_toy,0.95,1)
plt.figure(figsize = (18,7))
plt.grid(alpha=0.5)
plt.plot(df.iloc[-120:], label = "Training observations (truncated)")
plt.plot(df_test, color = "blue", label = "Out-of-sample observations", ls="dashed")
plt.plot(df_test.index,means_toy,color="red", label = "Benchmark mean forecast")
plt.fill_between(df_test.index, lowers_toy, uppers_toy, color="red", alpha=0.5, label = "Benchmark 90% forecast inverval")
plt.legend(fontsize=13)
plt.margins(x=0)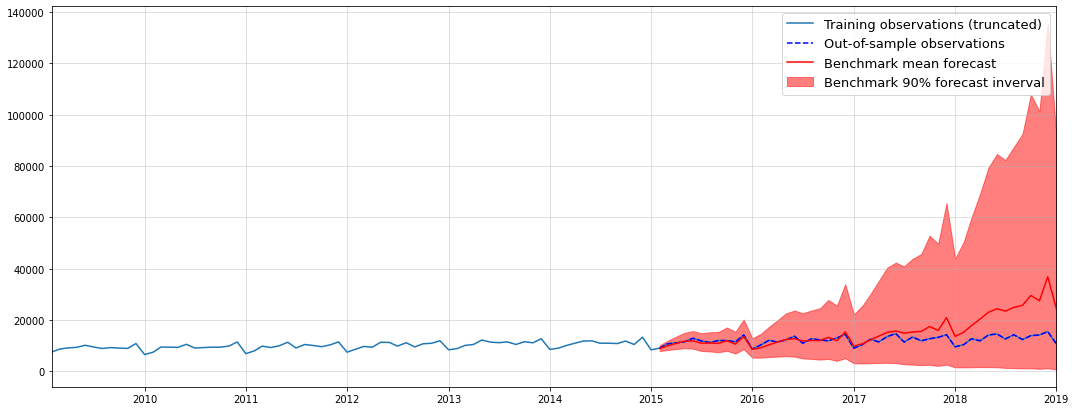
Apparently, the benchmark intervals are much worse than for the Random Forest. The mean forecast starts out reasonably but quickly deteriorates after a few steps.
Let’s compare both mean forecasts in a single chart:
plt.figure(figsize = (18,7))
plt.grid(alpha=0.5)
plt.plot(df.iloc[-120:], label = "Training observations (truncated)")
plt.plot(df_test, color = "blue", label = "Out-of-sample observations", ls="dashed")
plt.plot(df_test.index,means_forest,color="purple", label = "RF mean forecast",lw = 3)
plt.plot(df_test.index,means_toy,color="red", label = "Benchmark mean forecast", lw = 3)
plt.legend(fontsize=13)
plt.margins(x=0)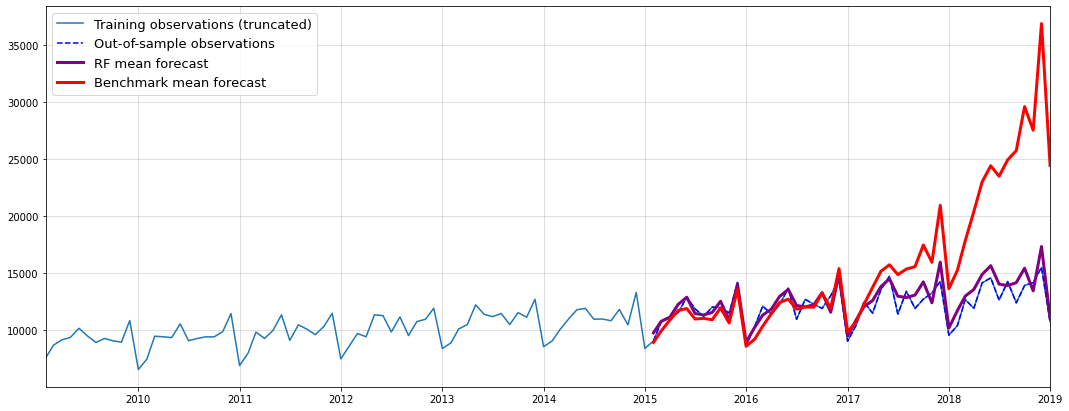
rmse_forest = np.sqrt(np.mean((df_test.values[:,0] - means_forest)**2))
rmse_toy = np.sqrt(np.mean((df_test.values[:,0] - means_toy)**2))
print("Random Forest: {}".format(rmse_forest))
print("Benchmark: {}".format(rmse_toy))Random Forest: 909.7996221364062
Benchmark: 6318.1429838549Clearly, the Random Forest is far superior for longer horizon forecasts.
Conclusion
Hopefully, this article gave you some insights on the do’s and dont’s of forecasting with tree models. While a single Decision Tree might be useful sometimes, Random Forests are usually more performant. That is, unless your dataset is very tiny in which case you could still reduce max_depth of your forest trees.
Obviously, you could add easily add external regressors to either model to improve performance further. As an example, adding monthly indicators to our model might yield more accurate results than right now.
As an alternative to Random Forests, Gradient Boosting could be considered. Nixtla’s mlforecast package has a very powerful implementation - besides all their other great tools for forecasting. Keep in mind however, that we cannot transfer the algorithm for forecast intervals to Gradient Boosting.
On another note, keep in mind that forecasting with advanced machine learning is a double-edged sword. While powerful at the surface, ML for time-series can overfit much quicker than for cross-sectional problems. As long as you properly test your model against some benchmarks, though, they should not be overlooked either.
PS: You can find a full notebook for this article here.
References
[1] Breiman, Leo. Random forests. Machine learning, 2001, 45.1, p. 5-32.
[2] Breiman, Leo, et al. Classification and regression trees. Routledge, 2017.
[3] Hamilton, James Douglas. Time series analysis. Princeton university press, 2020.
Introduction
In an earlier article, we discussed how to replace the conditional Gaussian assumption in a traditional GARCH model. While such gimmicks are a good start, they are far from being useful for actual applications.
One primary limitation is the obvious restriction to a single dimensional time-series. In reality, however, we are typically dealing with multiple time-series. Thus, a multivariate GARCH model would be much more appropriate.
Technically, we could fit a separate GARCH model for each series and handle interdependencies afterwards. As long as correlations between the time-series can be presumed constant, this can be a valid and straightforward solution. Once correlation becomes dynamic, however, we could lose important information that way.
As a motivating example, consider stock market returns of correlated assets. It is a commonly observed phenomenon that asset returns’ correlation tends to increase heavily during times of crisis. In consequence, ignoring such dynamics would be rather unreasonable given such convincing evidence.
Multivariate GARCH models, namely models for dynamic conditional correlation (DCC), are what we need in this case. The DCC model dates back to the early 2000s, starting with a seminal paper by Robert Engle. For this article, we will closely work with his notation.
From GARCH to multivariate GARCH and DCC
Remember that, for univariate Normal GARCH, we have the following formulas: For a deeper look at GARCH and its predecessor ARCH, I recommend reading the original papers (ARCH, GARCH).
Over the years, numerous extensions have been proposed to address the shortcomings of this base model - for example
- FIGARCH to model long memory of shocks in the conditional variance equation
- EGARCH for asymmetric effects of positive and negative shocks in the conditional variance
- …and various approaches to make the conditional variance term non-linear As we will see, all these variations of univariate GARCH can be used in a multivariate GARCH/DCC model.
General introduction to multivariate GARCH
First, let us introduce a bi-variate random variable with covariance matrix
In addition, we define
It can easily be seen that this matrix generalizes the squared observation term from the univariate GARCH model.
We could now generalize this to higher variate random variables and higher lag dependencies. For convenience, however, let us stick with the above.
Our goal then is to find an explicit formula to model the covariance matrix’ dependency on the past. For this, we follow the tradition of GARCH models. I.e., we condition covariance linearly on past covariances and past realizations of the actual random variables.
Notice that the obvious linear transformation (with
positive semi-definite) would be reasonable but highly inefficient for higher dimensions. After all, for a lag-5 model, we would already have 375 free variables. In relation to daily time-series, this is more than a year worth of data.
As a first restriction, it makes sense to avoid redundancies due to the symmetry of the covariance matrix. We introduce the following operation: Put simply, we stack all elements of the matrix into a vector while removing duplicates. This allows the following simplification to our initial multivariate GARCH model:
For the order 5-lag model, this specification reduces the amount of free variables to 45. As this is still quite high, we could impose some restrictions on our model matrices, for example
i.e. the matrices a diagonal. Going back, again, to the lag-5 model, we would now be down to 15 free variables.
Multivariate GARCH with constant and dynamic correlation
Another class of multivariate GARCH specifications has been proposed by Bollerslev and Engle. The core idea is to splitconditional covariance into conditional standard deviations and conditional correlations: Now, the conditional standard deviations can be modelled as the square roots of independent GARCH models. This leaves room for choosing any GARCH model that is deemed appropriate.
The correlation component can be presumed constant (= Constant conditional correlation, CCC) or auto-regressive (= Dynamic conditional correlation, DCC). For the latter, we can do the following: where
(positive semi-definite) and
As you can see, the un-normalized conditional correlation now follows an error-correction like term. Finally, to reduce the amount of free parameters, we can replace the matrices by scalars to get
where
On the one hand this formulation is less expressive than before. On the other hand, ensuring stationarity is much easier from a programmatic point of view.
Using Python and Tensorflow to implement DCC
Let us start with the full implementation and then look at the details:
import tensorflow as tf
import tensorflow_probability as tfp
class MGARCH_DCC(tf.keras.Model):
"""
Tensorflow/Keras implementation of multivariate GARCH under dynamic conditional correlation (DCC) specification.
Further reading:
- Engle, Robert. "Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models."
- Bollerslev, Tim. "Modeling the Coherence in Short-Run Nominal Exchange Rates: A Multi-variate Generalized ARCH Model."
- Lütkepohl, Helmut. "New introduction to multiple time series analysis."
"""
def __init__(self, y):
"""
Args:
y: NxM numpy.array of N observations of M correlated time-series
"""
super().__init__()
n_dims = y.shape[1]
self.n_dims = n_dims
self.MU = tf.Variable(np.mean(y,0)) #use a mean variable
self.sigma0 = tf.Variable(np.std(y,0)) #initial standard deviations at t=0
#we initialize all restricted parameters to lie inside the desired range
#by keeping the learning rate low, this should result in admissible results
#for more complex models, this might not suffice
self.alpha0 = tf.Variable(np.std(y,0))
self.alpha = tf.Variable(tf.zeros(shape=(n_dims,))+0.25)
self.beta = tf.Variable(tf.zeros(shape=(n_dims,))+0.25)
self.L0 = tf.Variable(np.float32(np.linalg.cholesky(np.corrcoef(y.T)))) #decomposition of A_0
self.A = tf.Variable(tf.zeros(shape=(1,))+0.9)
self.B = tf.Variable(tf.zeros(shape=(1,))+0.05)
def call(self, y):
"""
Args:
y: NxM numpy.array of N observations of M correlated time-series
"""
return self.get_conditional_dists(y)
def get_log_probs(self, y):
"""
Calculate log probabilities for a given matrix of time-series observations
Args:
y: NxM numpy.array of N observations of M correlated time-series
"""
return self.get_conditional_dists(y).log_prob(y)
@tf.function
def get_conditional_dists(self, y):
"""
Calculate conditional distributions for given observations
Args:
y: NxM numpy.array of N observations of M correlated time-series
"""
T = tf.shape(y)[0]
#create containers for looping
mus = tf.TensorArray(tf.float32, size = T) #observation mean container
Sigmas = tf.TensorArray(tf.float32, size = T) #observation covariance container
sigmas = tf.TensorArray(tf.float32, size = T+1)
us = tf.TensorArray(tf.float32, size = T+1)
Qs = tf.TensorArray(tf.float32, size = T+1)
#initialize respective values for t=0
sigmas = sigmas.write(0, self.sigma0)
A0 = tf.transpose(self.L0)@self.L0
Qs = Qs.write(0, A0) #set initial unnormalized correlation equal to mean matrix
us = us.write(0, tf.zeros(shape=(self.n_dims,))) #initial observations equal to zero
#convenience
sigma0 = self.sigma0
alpha0 = self.alpha0**2 #ensure positivity
alpha = self.alpha
beta = self.beta
A = self.A
B = self.B
for t in tf.range(T):
#tm1 = 't minus 1'
#suppress conditioning on past in notation
#1) calculate conditional standard deviations
u_tm1 = us.read(t)
sigma_tm1 = sigmas.read(t)
sigma_t = (alpha0 + alpha*sigma_tm1**2 + beta*u_tm1**2)**0.5
#2) calculate conditional correlations
u_tm1_standardized = u_tm1/sigma_tm1
Psi_tilde_tm1 = tf.reshape(u_tm1_standardized, (self.n_dims,1))@tf.reshape(u_tm1_standardized, (1,self.n_dims))
Q_tm1 = Qs.read(t)
Q_t = A0 + A*(Q_tm1 - A0) + B*(Psi_tilde_tm1 - A0)
R_t = self.cov_to_corr(Q_t)
#3) calculate conditional covariance
D_t = tf.linalg.LinearOperatorDiag(sigma_t)
Sigma_t = D_t@R_t@D_t
#4) store values for next iteration
sigmas = sigmas.write(t+1, sigma_t)
us = us.write(t+1, y[t,:]-self.MU) #we want to model the zero-mean disturbances
Qs = Qs.write(t+1, Q_t)
mus = mus.write(t, self.MU)
Sigmas = Sigmas.write(t, Sigma_t)
return tfp.distributions.MultivariateNormalFullCovariance(mus.stack(), Sigmas.stack())
def cov_to_corr(self, S):
"""
Transforms covariance matrix to a correlation matrix via matrix operations
Args:
S: Symmetric, positive semidefinite covariance matrix (tf.Tensor)
"""
D = tf.linalg.LinearOperatorDiag(1/(tf.linalg.diag_part(S)**0.5))
return D@S@D
def train_step(self, data):
"""
Custom training step to handle keras model.fit given that there is no input-output structure in our model
Args:
S: Symmetric, positive semidefinite covariance matrix (tf.Tensor)
"""
x,y = data
with tf.GradientTape() as tape:
loss = -tf.math.reduce_mean(self.get_log_probs(y))
trainable_vars = self.trainable_weights
gradients = tape.gradient(loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
return {"Current loss": loss}
def sample_forecast(self, y, T_forecast = 30, n_samples=500):
"""
Create forecast samples to use for monte-carlo simulation of quantities of interest about the forecast (e.g. mean, var, corr, etc.)
WARNING: This is not optimized very much and can take some time to run, probably due to Python's slow loops - can likely be improved
Args:
y: numpy.array of training data, used to initialize the forecast values
T_forecast: number of periods to predict (integer)
n_samples: Number of samples to draw (integer)
"""
T = tf.shape(y)[0]
#create lists for looping; no gradients, thus no tf.TensorArrays needed
#can initialize directly
mus = []
Sigmas = []
us = [tf.zeros(shape=(self.n_dims,))]
sigmas = [self.sigma0]
Qs = []
#initialize remaining values for t=0
A0 = tf.transpose(self.L0)@self.L0
Qs.append(A0)
#convenience
sigma0 = self.sigma0
alpha0 = self.alpha0**2 #ensure positivity
alpha = self.alpha
beta = self.beta
A = self.A
B = self.B
#'warmup' to initialize latest lagged features
for t in range(T):
#tm1 = 't minus 1'
#suppress conditioning on past in notation
u_tm1 = us[-1]
sigma_tm1 = sigmas[-1]
sigma_t = (alpha0 + alpha*sigma_tm1**2 + beta*u_tm1**2)**0.5
u_tm1_standardized = u_tm1/sigma_tm1
Psi_tilde_tm1 = tf.reshape(u_tm1_standardized, (self.n_dims,1))@tf.reshape(u_tm1_standardized, (1,self.n_dims))
Q_tm1 = Qs[-1]
Q_t = A0 + A*(Q_tm1 - A0) + B*(Psi_tilde_tm1 - A0)
R_t = self.cov_to_corr(Q_t)
D_t = tf.linalg.LinearOperatorDiag(sigma_t)
Sigma_t = D_t@R_t@D_t
sigmas.append(sigma_t)
us.append(y[t,:]-self.MU) #we want to model the zero-mean disturbances
Qs.append(Q_t)
mus.append(self.MU)
Sigmas.append(Sigma_t)
#sample containers
y_samples = []
R_samples = []
sigma_samples = []
for n in range(n_samples):
mus_samp = []
Sigmas_samp = []
sigmas_samp = [sigmas[-1]]
us_samp = [us[-1]]
Qs_samp = [Qs[-1]]
#forecast containers
ys_samp = []
sig_samp = []
R_samp = []
for t in range(T_forecast):
u_tm1 = us_samp[-1]
sigma_tm1 = sigmas_samp[-1]
sigma_t = (alpha0 + alpha**2 + beta*u_tm1**2)**0.5
u_tm1_standardized = u_tm1/sigma_tm1
Psi_tilde_tm1 = tf.reshape(u_tm1_standardized, (self.n_dims,1))@tf.reshape(u_tm1_standardized, (1,self.n_dims))
Q_tm1 = Qs_samp[-1]
Q_t = A0 + A*(Q_tm1 - A0) + B*(Psi_tilde_tm1 - A0)
R_t = self.cov_to_corr(Q_t)
D_t = tf.linalg.LinearOperatorDiag(sigma_t)
Sigma_t = D_t@R_t@D_t
sigmas_samp.append(sigma_t)
Qs_samp.append(Q_t)
ynext = tfp.distributions.MultivariateNormalFullCovariance(self.MU, Sigma_t).sample()
ys_samp.append(tf.reshape(ynext,(1,1,-1)))
sig_samp.append(tf.reshape(sigma_t,(1,1,-1)))
R_samp.append(tf.reshape(R_t,(1,1,self.n_dims,self.n_dims)))
us_samp.append(ynext-self.MU)
y_samples.append(tf.concat(ys_samp,1))
R_samples.append(tf.concat(R_samp,1))
sigma_samples.append(tf.concat(sig_samp,1))
return tf.concat(y_samples,0).numpy(), tf.concat(R_samples,0).numpy(), tf.concat(sigma_samples,0).numpy()While the code is quite lengthy, its primary purpose is only twofold:
- Calculate the in-sample distribution (get_conditional_dists(…)) - is needed for optimization via maximum likelihood. This function calculates the likelihood values of each observation given the MGARCH model.
- Forecast the out-of sample distribution (sample_forecast(…)) - as the formulas for the model as a whole are quite complex, it’s difficult to calculate the forecast distributions in closed form. However, we can, more or less, easily sample from the target distribution. With a sufficiently large sample, we can estimate all relevant quantities of interest (e.g. forecast mean and quantiles).
Notice that here, we have specified the conditional distribution as a multivariate Gaussian. Given the theory from above, this is nevertheless not a necessity. A multivariate T-distribution, for example, could work equally well or even better. Obviously, though, a Gaussian is always nice to work with.
Now, the remaining functions are basically just helpers to maintain some structure. I decided to not break down the key functions down further in order to keep the calculations in one place. If we were unit testing our model, it would actually be sensible to split things up into better testable units.
As we want to use the Keras API for training, we need to customize the training procedure (train_step(…)). Contrary to typical Keras use-cases, our training data is not split between input and output data. Rather, we only have one set of data, namely the time-series observations.
Finally, each training step needs to process all training observations at once. (no mini-batching). Also the observations must always remain in order (no shuffling).
This yields the following generic training loop:
model.fit(ts_data, ts_data, batch_size=len(ts_data), shuffle=False, epochs = 300, verbose=False)
Multivariate GARCH in Python - an example
We can now test our model on a simple example and see what happens. Given Python’s seamless interaction with Yahoo Finance, we can pull some data for DAX and S&P 500:
import yfinance as yf
import numpy as np
import matplotlib.pyplot as plt
data = yf.download("^GDAXI ^GSPC", start="2017-09-10", end="2022-09-10", interval="1d")
close = data["Close"]
returns = np.log(close).diff().dropna()
fig, axs = plt.subplots(2,1, figsize = (22,5*2))
for i in range(2):
axs[i].plot(returns.iloc[:,i])
axs[i].grid(alpha=0.5)
axs[i].margins(x=0)
axs[i].set_title("{} - log-returns".format(returns.columns[i]),size=20)[*********************100%***********************] 2 of 2 completed
The typical volatility clusters are visible for both time-series. To see what happens with correlation between both stocks over time, we can plot the 60-day rolling correlation:
import pandas as pd
rolling_corrs = returns.rolling(60,min_periods=0).corr()
gdaxi_sp500_rollcorr = rolling_corrs["^GDAXI"][rolling_corrs.index.get_level_values(1)=="^GSPC"]
plt.figure(figsize = (22,5))
plt.title("60 day rolling correlation - DAX vs. S&P500",size=20)
plt.plot(returns.index[30:],gdaxi_sp500_rollcorr.values[30:],c="green", label="60 day rolling correlation")
plt.grid(alpha=0.5)
plt.margins(x=0)
It appears as if correlation between both indices has dropped since the beginning of the pandemic. Afterwards, correlation seems to fluctuate in cycles.
All in all, the pattern looks like a discretized version of an Ornstein-Uhlenbeck process. The error correction formulation in our model should be able to capture this behaviour accordingly.
After splitting the data into train and test set (last 90 observations), we can fit the model. Then we take samples from the (90 days ahead) forecast distribution as follows (this takes some time):
np.random.seed(123)
tf.random.set_seed(123)
train = np.float32(returns)[:-90,:]
test = np.float32(returns)[-90:,:]
model = MGARCH_DCC(train)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-2))
model.fit(train, train, batch_size=len(train), shuffle=False, epochs = 300, verbose=False)
fcast = model.sample_forecast(train,90,1000)Now, we are particularly interested in the conditional correlation fit and forecasts:
from datetime import timedelta
corrs = fcast[1][:,:,0,1]
corr_means = np.mean(corrs,0)
corr_lowers = np.quantile(corrs,0.05,0)
corr_uppers = np.quantile(corrs,0.95,0)
conditional_dists = model(np.float32(returns.values))
conditional_correlations = [model.cov_to_corr(conditional_dists.covariance()[i,:,:])[0,1].numpy() for i in range(len(returns))]
idx_train = returns[:-90].index
idx_test = pd.date_range(returns[:-90].index[-1] + timedelta(days=1), returns[:-90].index[-1] + timedelta(days=90))
fig, axs = plt.subplots(2,1,figsize=(20,12), gridspec_kw={'height_ratios': [2, 1]})
axs[0].set_title("Conditional Correlation - DAX, S&P500", size=20)
axs[0].axhline(np.corrcoef(returns.T)[0,1], c="green",alpha=0.75,ls="dashed",lw=2, label="Unconditional sample correlation")
axs[0].plot(idx_train[30:],conditional_correlations[30:-90],c="red", label="MGARCH in-sample conditional correlation")
axs[0].plot(idx_test,conditional_correlations[-90:],c="red",ls="dotted",lw=3, label="MGARCH out-of-sample conditional correlation")
axs[0].plot(idx_test, corr_means,color="blue",lw=3, alpha=0.9, label="MGARCH correlation mean forecast")
axs[0].fill_between(idx_test, corr_lowers, corr_uppers, color="blue", alpha=0.2, label="MGARCH correlation 90% forecast interval")
axs[0].grid(alpha=0.5)
axs[0].legend(prop = {"size":13})
axs[0].margins(x=0)
axs[1].set_title("Sanity check: Model predicted VS. rolling correlation",size=20)
axs[1].plot(returns.index[30:],gdaxi_sp500_rollcorr.values[30:],c="green", label="60 day rolling correlation")
axs[1].plot(returns.index[30:],conditional_correlations[30:],c="red", label="MGARCH in-sample conditional correlation")
axs[1].grid(alpha=0.5)
axs[1].legend(prop = {"size":13})
axs[1].margins(x=0)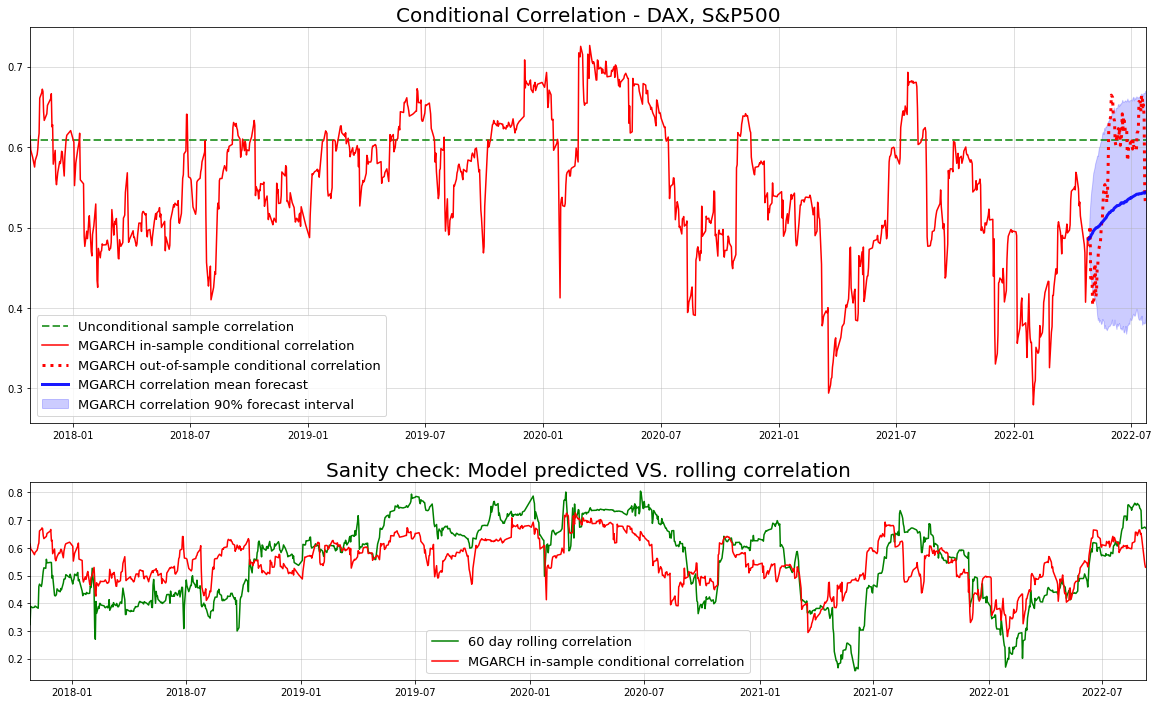
The forecasted correlation (blue) captures the actual correlation (red) under our model quite well. Obviously though, the true correlation is unknown. Nevertheless, our model matches the rolling correlation quite well, even out-of sample. This implies that our approach is - at least - not completely off.
Being able to reliably forecast correlations might be interesting for statistical arbitrage strategies. While those strategies typically use price movements, correlations could be an interesting alternative.
From here, we could also look at price and volatility forecasts as well. To keep this article from becoming bloated, I’ll leave it to the interested reader to do this. You can find the relevant notebook here - feel free to extend with your own experiments.
Conclusion
Today, we took a look at multivariate extensions to GARCH-type models. While a ‘naive’ extension is quite straightforward, we need to be careful not to overparameterize our model. Luckily, there already exists research on useful specifications that mostly avoid this issue.
For deeper insights, it is likely interesting to consider non-linear extensions to this approach. The trade-off between overfitting and flexibility will possible be even more relevant here. If you want to head into that direction, you might want to have a look at some results from Google Scholar.
References
[1] Bollerslev, Tim. Modelling the coherence in short-run nominal exchange rates: a multivariate generalized ARCH model. The review of economics and statistics, 1990, p. 498-505.
[2] Engle, Robert. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. Journal of Business & Economic Statistics 20.3, 2002, p. 339-350.
[3] Lütkepohl, Helmut. New introduction to multiple time series analysis. Springer Science & Business Media, 2005.
Introduction
A standard method in the time-series analysis toolkit are difference transformations or differencing. Despite being dead simple, differencing can be quite powerful. In fact, it allows us to outperform sophisticated time-series models with what is almost a bare white noise process.
Due to its simplicity, differencing is quite popular whenever some unit-root test is significant. While this is fairly safe in the univariate case, things look differently for multivariate time-series.
Let us demonstrate this with a simple example:
A motivating time-series example
To exemplify the underlying issue, I created an artificial, two-dimensional and linear time-series:
import numpy as np
import matplotlib.pyplot as plt
A = np.array([[0.2],[-0.3]])
B = np.array([[-0.9],[0.3]])
Atilde = A@B.T
sigma = np.array([[0.1],[0.1]])
np.random.seed(987)
ys = [np.random.normal(size=(2,1))*sigma]
for t in range(500):
dy = Atilde@ys[-1] + np.random.normal(size=(2,1))*sigma
ys.append(ys[-1] + dy)
Y = np.concatenate(ys,1).T[1:,:]
Ytrain = Y[:-50,:]
Ytest = Y[-50:,:]
forecast_range = np.arange(len(Ytrain),len(Ytrain)+len(Ytest))
plt.figure(figsize=(16,8))
plt.plot(Ytrain[:,0],c="blue", label="Time-Series 1 - Train set",lw=2)
plt.plot(Ytrain[:,1],c="red", label="Time-Series 2 - Train set",lw=2)
plt.plot(forecast_range, Ytest[:,0],c="blue", ls="dotted", label="Time-Series 1 - Test set")
plt.plot(forecast_range, Ytest[:,1],c="red", ls="dotted", label="Time-Series 2 - Test set")
plt.grid(alpha=0.5)
plt.legend()
There seems to be some connection between both time-series but that might obviously just be a spurious one over time. The next step that you often see done in this setting is to test for unit-roots in both time-series.
An Augmented-Dickey Fuller test from statsmodels shows significance scores of 0.8171 and 0.8512. This underlines the visible unit-roots in both time-series. Thus, the difference transformation appears to be the logical next step. Let’s do that for the train set to forecast the test set further down the line:
Ytrain_diff = Ytrain[1:,:]-Ytrain[:-1,:]
fig, ax = plt.subplots(2, 1, figsize = (16,8))
ax[0].plot(Ytrain_diff[:,0], c="blue", lw=2)
ax[0].grid(alpha=0.5)
ax[0].set_title("Time Series 1 - Train set differenced")
ax[1].plot(Ytrain_diff[:,1], c="red", lw=2)
ax[1].grid(alpha=0.5)
ax[1].set_title("Time Series 2 - Train set differenced")Text(0.5, 1.0, 'Time Series 2 - Train set differenced')
Next, we can check forecast performance for two VAR(1) models - one trained on the original time-series and one on the transformed one:
from statsmodels.tsa.api import VAR
from scipy.stats import norm
model_nodiff = VAR(Ytrain).fit(1,trend='n')
pred_mean_nodiff = model_nodiff.forecast(Ytrain,steps=len(Ytest))
pred_std_nodiff = np.sqrt(np.array(list(map(lambda x: np.diag(x),list(model_nodiff.forecast_cov(steps=len(Ytest)))))))
pred_lower_nodiff = norm(pred_mean_nodiff,pred_std_nodiff).ppf(0.025)
pred_upper_nodiff = norm(pred_mean_nodiff,pred_std_nodiff).ppf(0.975)
plt.figure(figsize=(16,8))
plt.plot(Ytrain[:,0],c="blue",lw=2)
plt.plot(Ytrain[:,1],c="red",lw=2)
plt.plot(forecast_range, Ytest[:,0],c="blue", ls="dotted")
plt.plot(forecast_range, Ytest[:,1],c="red", ls="dotted")
plt.plot(forecast_range, pred_mean_nodiff[:,0],c="blue",ls="dashed",lw=2, label="Time-Series 1 - Point forecast")
plt.plot(forecast_range, pred_mean_nodiff[:,1],c="red",ls="dashed",lw=2, label="Time-Series 2 - Point forecast")
plt.fill_between(forecast_range, pred_lower_nodiff[:,0], pred_upper_nodiff[:,0],color="blue",alpha=0.3,label="Time-Series 1 - 95% forecast interval")
plt.fill_between(forecast_range, pred_lower_nodiff[:,1], pred_upper_nodiff[:,1],color="red",alpha=0.3,label="Time-Series 2 - 95% forecast interval")
plt.grid(alpha=0.5)
plt.legend()
The summed MSE over both time-series forecasts is at 0.3463. Clearly, the model with training data differenced should perform better:
model_diff = VAR(Ytrain_diff).fit(1,trend='n')
pred_mean_diff = Ytrain[-1,:].reshape(1,-1)+np.cumsum(model_diff.forecast(Ytrain_diff,steps=len(Ytest)),0)
pred_std_diff = np.sqrt(np.cumsum(np.array(list(map(lambda x: np.diag(x),list(model_diff.forecast_cov(steps=len(Ytest)))))),0))
pred_lower_diff = norm(pred_mean_diff,pred_std_diff).ppf(0.025)
pred_upper_diff = norm(pred_mean_diff,pred_std_diff).ppf(0.975)
plt.figure(figsize=(16,8))
plt.plot(Ytrain[:,0],c="blue",lw=2)
plt.plot(Ytrain[:,1],c="red",lw=2)
plt.plot(forecast_range, Ytest[:,0],c="blue", ls="dotted")
plt.plot(forecast_range, Ytest[:,1],c="red", ls="dotted")
plt.plot(forecast_range, pred_mean_diff[:,0],c="blue",ls="dashed",lw=2, label="Time-Series 1 - Point forecast")
plt.plot(forecast_range, pred_mean_diff[:,1],c="red",ls="dashed",lw=2, label="Time-Series 2 - Point forecast")
plt.fill_between(forecast_range, pred_lower_diff[:,0], pred_upper_diff[:,0],color="blue",alpha=0.3,label="Time-Series 1 - 95% forecast interval")
plt.fill_between(forecast_range, pred_lower_diff[:,1], pred_upper_diff[:,1],color="red",alpha=0.3,label="Time-Series 2 - 95% forecast interval")
plt.grid(alpha=0.5)
plt.legend()
This time, the summed MSE is 0.5105 - approximately 50% higher. Also, the forecast interval for time-series 1 is much larger than without any differencing. Something seems to be off with the popular difference transformation.
Why cointegration matters
Right now, you might - rightfully - argue that the underperformance of the differencing model was due to pure chance. Indeed, we would need much broader experiments to verify our initial claim empirically.
It is, however, possible to actually prove why differencing can be bad for multivariate time-series analysis. To do so, let us take a step back to univariate time-series models and why difference transformations work here.
We will only look at AR(1) and VAR(1) time-series for simplicity. All results can be shown to hold for higher-order AR/VAR, too.
Unit-Root AR(1) time-series - when differencing is likely safe
Mathematically, an AR(1) time-series looks as follows: In order for differencing to make sense, we need the time-series to have a unit root. This is the case when solution of characteristic polynomial
lies on the unit-circle, i.e.
The only choice for the AR-parameter is therefore
and thus
To make this equation stationary, we subtract the lagged variable from both sides:
Clearly, the best possible forecast now is to predict white noise. Keep in mind that we could equally well fit a model on the untransformed variable. However, the differenced time-series directly uncovers the lack of any truly autoregressive component.
On the one hand, differencing is clearly a good choice in univariate time-series with unit-roots. Things are not as simple for multivariate time-series, though.
Multivariate time-series with cointegration
Consider now a VAR(1) time where we replace the scalars in the AR(1) model with vectors (bold, lower-case) and vectors (upper case): A unit-root in a VAR(1) time-series imply, similarly to the AR(1) case, that
In the trivial case, the autoregression parameter is the identity matrix. This implies that the marginals in our VAR(1) time-series are all independent and unit-root. If we exclude this case and proceed as for AR(1), we get
The last line is also called an Vector Error Correcting Representation of a VAR time-series. If you scroll back to our simulation, this is the exact formula that was used to generate the time-series.
By making Atilde rank-deficient, the time-series becomes cointegrated, as explained by Lütkepohl. There exists another, broader definition of cointegration but we won’t cover that today.
Clearly, a cointegrated VAR(1) time-series differs from the univariate AR(1) case. Even after differencing, the transformed values depend on the past of the original time-series. We would therefore lose important information if we don’t account for the original time-series anymore.
If you are working with multivariate data, you should therefore not just blindly apply differencing.
How to deal with cointegration
The above result begs the question of what we should do to handle cointegration. Typically, time-series analysis is concerned either with forecasting or inference. Therefore, two different approaches come to mind:
Cross-validation and backtesting - the pragmatic, ‘data sciency’ approach. If our goal is primarily to build the most accurate forecast, we don’t necessarily need to detect cointegration at all. As long as the resulting model is performant and reliable, nearly anything goes.
As usually, the ‘best’ model can be selected based on cross-validation and out-of-sample performance tests. The primary implication from cointegration is then to apply differencing with some care.
On the other hand, the above result also suggests that adding the original time-series as a feature might be a good idea in general.
Statistical tests - the classical statistics way. Obviously, cointegration is nothing new to econometricians and statisticians. If you are interested in learning about the generating process itself, this approach is likely more expedient.
Luckily, the work of James MacKinnon provides extensive insights into tests for cointegration. Other popular cointegration tests have been developed by Engle and Granger and Søren Johansen.
In Python, you can find the MacKinnon test in the statsmodels library. For the above time-series, the test yields a p-value of almost zero.
Conclusion
Hopefully, this article was an eye-opener to you to not just difference every time-series straight ahead. You should be aware by now that cointegration is a peculiarity of multivariate time-series that needs to be treated with care.
Keep in mind that standard cointegration is concerned with linear time-series only. Once non-linear dynamics are present, things could become even more messy and differencing might be even less suitable.
Indeed, there exists some recent research on non-linear cointegration. You might want to take a look at it for further details.
References
[1] Engle, Robert F.; Granger, Clive WJ. Co-integration and error correction: representation, estimation, and testing. Econometrica: journal of the Econometric Society, 1987, p. 251-276.
[2] Hamilton, James Douglas. Time series analysis. Princeton university press, 2020.
[3] Lütkepohl, Helmut. New introduction to multiple time series analysis. Springer Science & Business Media, 2005.
Introduction
Facebook Prophet is arguably one of the most widely known tools for time-series forecasting and related tasks. Ask any data scientist who works with time-series data if they know Prophet and the answer is likely either a yes or an annoyed yes.
After all, Facebook Prophet has become quite a controversial tool for time-series problems. Some people don’t want to work without it anymore, others clearly hate it.
However, whether you like it or not, Prophet users seem to face considerable challenges when it comes to modelling the Covid-19 shock. While, by now, people have found workaround, I’d argue that these issues are caused by a deeper problem with Facebook Prophet:
The fundamental flaw of Facebook Prophet
The most problematic aspect of Facebook Prophet is that it reduces time-series modelling to a curve-fitting task. Other approaches make auto-regressive dynamics a fundamental assumption. Prophet, on the other hand, merely tries to draw a least-error line through time against your data.
More technically, the evolution of almost all dynamical systems depend on past realizations. We can write this as follows: Where we only consider dependence on the last observation and no hidden states.
Most time-series models focus on the right-hand side. Facebook Prophet, however, is concerned with the left-hand side of the equation. Even worse, Prophet implicitly makes the following assumptions on top (see Facebook Prophet paper, page 14, for reference): This is problematic for at least three reasons:
- Dependence on past realizations is completely ignored. In the real-world, a single, large shock will quickly change the whole future trajectory of the time-series. This can trivially be accounted for by a dynamical model but not by Facebook Prophet.
- The mean function needs to extrapolate outside the range of observed values. The way that Prophet frames the modelling problem inevitably leads to the problem of out-of-distribution generalization. All your future t’s will lie outside your training domain by design.
- Variance is presumed to be constant. Related to 1. - if random shocks have impact on the future, variance - as a measure of uncertainty - should grow as we are forecasting further ahead.
As a general rule of thumb: If the forecast intervals of your model do not grow over time, something is likely wrong with it. Unless you know exactly what you are doing, you should consider an alternative.
Facebook Prophet underperforms against a toy benchmark
To exemplify the above, I ran a pretty simple forecasting benchmark on German economic data. While the example is a little artificial and too small to generalize, the implications should be clear.
I used the following dataset: Retail sale in non-specialised stores (ex. food) - Jan 2012 - May 2022 (monthly; available [here]). The train set consists of all data from Jan 2021 to Dec 2019; the test set uses all data from Jan 2020 - May 2022:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from datetime import date
df = pd.read_excel("../data/45212-0004.xlsx")
ts = df.iloc[804:937,2].replace("...",np.nan).dropna()
df = pd.concat([pd.Series(pd.date_range(date(2012,1,1),date(2022,6,1),freq="M")),ts.reset_index(drop=True)],1)
df.columns = ["ds","y"]
df.index = df["ds"]
df_train = df.iloc[:96,:]
df_test = df.iloc[96:,:]
plt.figure(figsize = (14,8))
plt.plot(df_train["y"], label = "Train")
plt.plot(df_test["y"], label = "Test")
plt.grid(alpha = 0.5)
plt.legend()
plt.title("Germany, Retail sale in non-specialised stores (ex. food) - Jan 2012 - May 2022")/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/openpyxl/styles/stylesheet.py:226: UserWarning: Workbook contains no default style, apply openpyxl's default
warn("Workbook contains no default style, apply openpyxl's default")
/var/folders/2d/hl2cr85d2pb2kfbmsng3267c0000gn/T/ipykernel_63305/4068186796.py:9: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only.
df = pd.concat([pd.Series(pd.date_range(date(2012,1,1),date(2022,6,1),freq="M")),ts.reset_index(drop=True)],1)Text(0.5, 1.0, 'Germany, Retail sale in non-specialised stores (ex. food) - Jan 2012 - May 2022')
A reasonable forecasting model should be able to anticipate at least the possibility of random shocks. This would usually be visible by increasing forecast intervals. After all, the further we look ahead, the more opportunities for high impact events.
In this case, the time-series does not go completely bonkers after the shock from Corona. Thus, Facebook Prophet should not struggle too much here. Let’s see how it does:
A simple Prophet forecast
from prophet import Prophet
m = Prophet()
m.fit(df_train)
prph_pred = m.predict(df_test)
plt.figure(figsize = (14,8))
plt.plot(df_train["y"], label = "Train")
plt.plot(df_test["y"], label = "Test")
plt.grid(alpha = 0.5)
plt.title("Germany, Retail sale in non-specialised stores (ex. food) - Jan 2012 - May 2022")
plt.plot(df_test.index,prph_pred["yhat"],label = "Prophet Forecast")
plt.fill_between(df_test.index,prph_pred["yhat_lower"],prph_pred["yhat_upper"],alpha=0.3,color="green")
plt.legend()18:21:49 - cmdstanpy - INFO - Chain [1] start processing
18:21:50 - cmdstanpy - INFO - Chain [1] done processing
For the mean forecast Prophet was able to reasonably predict out-of-sample - at least to some extent. The forecast intervals, however, are completely ludicrous. Our model simply took roughly the residuals from the in-sample data and projected their intervals into the future.
This clearly shows that Facebook Prophet did not really learn the inherent dynamics but merely a function of time. If the impact of Covid on the underlying dynamics were worse, we would likely not even see reasonable point forecasts either. I am sure that there are many data scientists out there where this was exactly the case.
An even simpler forecast model
As you might have heard by now, Prophet does not learn anything about the underlying system dynamics. Thus, our goal is to now create a competitor that is a) very simple and b) capable of actually modelling the dynamics.
From the time-series plot, we see that there is a clear yearly seasonality. After removing that via seasonal differencing, I saw that there was a remaining integration component that I removed via another round of first-order differencing.
Obviously, this is not a full diagnostic but sufficient for our simple toy example. Also, since the time-series is non-negative, I initially transformed it by taking the square-root. This ensures that the re-transformed series will be non-negative as well.
All the above leads us to the following, relatively simple model: In summary, we assume that, after ‘square-rooting’ and differencing, only a noise term remains. Here, we even assume that the noise distribution stays constant over time. A more sophisticated model should obviously check for time-varying noise.
The only thing that our model now needs to learn is the distribution of the noise. Afterwards, we draw noise samples and re-integrate (i.e. re-transform the differencing operations). Finally, we estimate point and interval forecasts.
To learn the noise distribution, I used scipy’s gaussian_kde function. This fits a Gaussian kernel density estimator to the data. We can then use this estimate to draw noise samples:
from scipy.stats import gaussian_kde
#reverting the order of differencing yields the same result but makes re-transformation easier
diffed = np.sqrt(df_train["y"]).diff().dropna()
diffed_s = diffed.diff(12).dropna()
plt.figure(figsize = (10,8))
plt.grid(alpha = 0.5)
plt.hist(diffed_s,bins=20,density = True,alpha=0.5, label = "Histogram of diffed time-series")
kde = gaussian_kde(diffed_s)
target_range = np.linspace(np.min(diffed_s)-0.5,np.max(diffed_s)+0.5,num=100)
plt.plot(target_range, kde.pdf(target_range),color="green",lw=3, label = "Gaussian Kernel Density of diffed time-series")
plt.legend()
Next, we draw samples and re-transform them into a forecast of our original time-series:
np.random.seed(321)
full_sample = []
for i in range(10000):
draw = kde.resample(len(df_test)).reshape(-1)
result = list(diffed.iloc[-12:].values)
for t in range(len(df_test)):
result.append(result[t]+draw[t])
full_sample.append(np.array((np.sqrt(df_train.iloc[-1]["y"])+np.cumsum(result[12:]))).reshape(-1,1)**2)
reshaped = np.concatenate(full_sample,1)
result_mean = np.mean(reshaped,1)
lower = np.quantile(reshaped,0.05,1)
upper = np.quantile(reshaped,0.95,1)
plt.figure(figsize = (14,8))
plt.plot(df_train["y"], label = "Train")
plt.plot(df_test["y"], label = "Test")
plt.grid(alpha = 0.5)
plt.title("Germany, Retail sale in non-specialised stores (ex. food) - Jan 2012 - May 2022 + Forecast")
plt.plot(df_test.index, result_mean,label = "Toy model forecast",color="blue")
plt.fill_between(df_test.index,lower,upper,alpha=0.3,color="blue")
plt.legend()
Especially the forecast interval makes much more sense than for Facebook Prophet. As desired, the forecast intervals grow larger over time which implies increasing uncertainty.
Let us also do a side-by-side comparison:
plt.figure(figsize = (14,8))
plt.plot(df_train["y"], label = "Train")
plt.plot(df_test["y"], label = "Test")
plt.grid(alpha = 0.5)
plt.title("Germany, Retail sale in non-specialised stores (ex. food) - Jan 2012 - May 2022 + Forecast")
plt.plot(df_test.index, result_mean,label = "Toy model forecast",color="blue")
plt.fill_between(df_test.index,lower,upper,alpha=0.3,color="blue")
plt.plot(df_test.index,prph_pred["yhat"],label = "Prophet Forecast",color="green")
plt.legend()
We can also calculate the RMSE for both mean forecasts:
rmse_simple = np.sqrt(np.mean((result_mean-df_test["y"].values)**2))
rmse_prophet = np.sqrt(np.mean((prph_pred["yhat"].values[-len(df_test):]-df_test["y"].values)**2))
print("Simple Model: {}".format(rmse_simple))
print("Prophet: {}".format(rmse_prophet))Simple Model: 20.745456460849358
Prophet: 22.49447614293072Takeaways for the dedicated Prophet user
The question is, what do we make out of this? Clearly, the large, long-term user-base of Facebook Prophet indicates that people are getting some value from it. Also, Facebook/Meta employs some very bright people - it’s highly unlikely that they would produce a completely useless library.
Going back to our initial considerations, we can deduce the following:
Prophet should work fine as long as it correctly depicts the conditional mean and the conditional variance. Mathematically,
for all forecast periods
.
This could be the case when the underlying system is in a nice, equilibrium, e.g. when the economy is in a non-volatile state. However, as soon as there is a large shock, the variance requirement is almost certain to be broken. This is exactly what we saw in the example time-series above.
Thus, should you drop Prophet altogether? If the results are good and if your forecasts going completely nuts does not have a large negative impact, I’d argue that you should keep it. Never change a running system, at least not over night.
If you are heavily dependent on a model that can randomly break at any time, though, you might want to start looking for alternatives.
Another use-case where Facebook Prophet makes more sense in my opinion, is outlier and change point detection. If you are simply interested in deviations from the expected trajectory, prophet can score you some quick and easy wins. As soon as forecast quality becomes a thing, however, you should be careful.
Will [Neural Prophet], a.k.a. Facebook Prophet 2.0, make things better? At least their Deep-AR module now considers past realizations to predict the future. On the other hand, Neural Prophet still makes heavy use of curve fitting. Thus, you should be wary of the Prophet upgrade, too.
If you decide that you are going to use either of the Prophets, I recommend benchmarking against trivial alternatives. When a simple but theoretically more sound model - as in our example - performs comparably, you might want to reconsider your choice.
Alternatives to Facebook Prophet
No mini-rant without trying to offer a solution. On the one hand, these alternatives will require more manual work to find a suitable model. On the other hand, chances are good that the product will be more robust than a convenient Prophet().fit().
- Kats: While Kats is a broad library for general time-series analysis, it offers some endpoints for forecasting as well. Just like Prophet, it has also been open sources by Facebook/Meta.
- Darts: Specifically aimed at forecasting problems. Darts provides support for a variety of modelling options.
- tsfresh: This package only creates a large set of time-series summary statistics for you. Then, you can use those features as predictors in a custom forecasting model. Pretty flexible, but also more manual work.
Conclusion
Despite its popularity, Facebook Prophet contains some serious theoretical issues. These flaws can easily render its forecasts useless. On the one hand, Prophet makes building forecast models at scale more or less a breeze. This convenience, however, comes at the cost of a fair amount of unreliability.
To summarize all the above: As long as you expect your time-series to remain somewhat stable, Prophet can be a helpful plug-and-play solution. However, don’t get fooled by Prophet being right many times. Worst case, you ultimately go bust when it suddenly isn’t anymore.
Introduction
According to the famous principle of [Occam’s Razor], simpler models are more likely to be close to truth than complex ones. For change point detection problems - as in IoT or finance applications - arguably the simplest one is the Cumulative Sum (CUSUM) algorithm.
Despite its simplicity though, it can nevertheless be a powerful tool. In fact, CUSUM requires only a few loose assumptions on the underlying time-series. If these assumptions are met, it is possible to prove a plethora of helpful statistical properties.
A quick look at CUSUM
In summary, CUSUM detects shifts in the mean of a time-series that is stationary between two changepoints. Consider the following time-series:

This example is stationary between each pair of change points and thus a perfect use-case for our CUSUM algorithm. For change point detection on a non-stationary time-series like the next one, CUSUM will likely not work as intended:
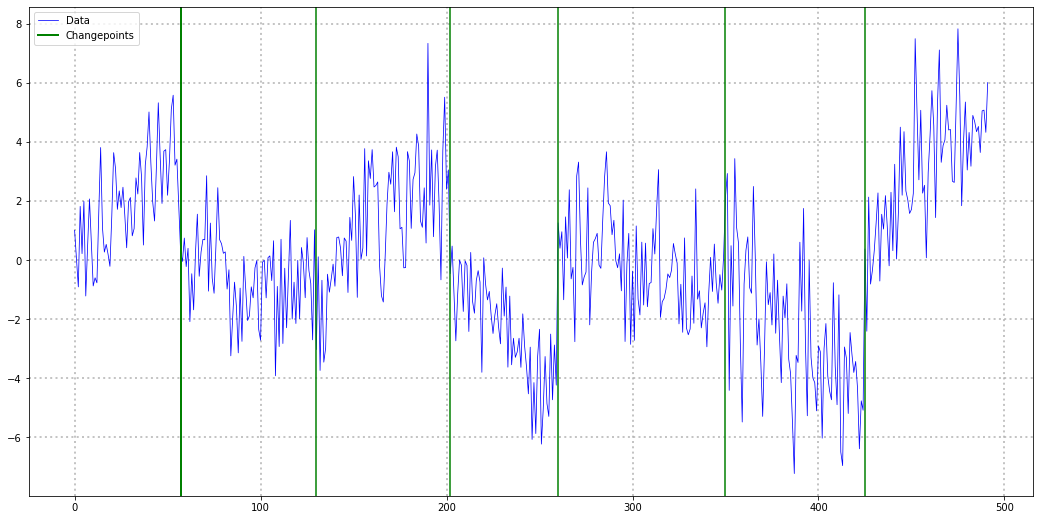
While CUSUM might still be able to detect shifts from a stationary to a non-stationary segment, there is no guarantee that is does so reliably anymore.
In general, the idea behind CUSUM can roughly be summarized as follows:
If a time-series has constant zero mean, the cumulative sum of its realizations converges to a zero-mean Normal distribution (given some relatively loose technical assumptions). Thus, if the cumulative sum diverges from a zero-mean Normal distribution, a change-point in the underlying time-series might have occurred.
We can derive this from one of the many central limit theorems (CLTs). While each CLT has some additional requirements (e.g. independent draws and finite variance for the Lyapunov CLT), chances are good that your particular time-series fulfils one of them.
In practice, we would estimate the mean of the current regime, subtract it from the time-series and calculate the cumulative sum. This only leaves the question of setting rule for when a change point has happened.
The standard CUSUM algorithm as in Wikipedia suggests to sum the z-standardized realizations of the time-series. A change point then occurs whenever this sum exceeds a pre-defined threshold. This whole procedure is therefore an ‘online’ algorithm, i.e. we can use it on a live data stream.
Some problems with the standard CUSUM algorithm
You might have already asked yourself how you should set the change point threshold values in CUSUM. After all, setting the threshold too loose will lead to undetected change points. On the other hand, narrow thresholds can easily lead to frequent false alarms.
Unfortunately, it is not easy to find clear instructions to solve this question. While a rule-of-thumb or experimenting with some setting might occasionally work, this is clearly not a reliable solution. Also, it is not feasible when we want to apply CUSUM on a large number of data streams.
Another issue concerns the level of anomaly that a given subsequence exhibits. Even if no change point happens, it might still be relevant to discover when a time-series is behaving unexpectedly.
Luckily, we can approach both challenges with a slight modification of the raw CUSUM algorithm.
A probabilistic version of CUSUM
At this point, we will finally need some equations. First, we define the standardized observations of an arbitrary subsequence of our time-series: The hat-notation stresses that we can only ever work with estimates of the mean and standard deviation of our series. We can calculate these values, for example, by using the first N realizations for our estimates.
If we presume that the conditions of some CLT hold for our sequence, the following holds approximately and in the limit By dividing the cumulative sum by the square root of the time-frame, we get a (theoretical) standard Normal distribution. Thus, as long as our CLT assumptions are valid, the following holds for the standardized, cumulative sum of the realized time-series:
where
denotes the c.d.f. of a standard Normal distribution.
The resulting value can be interpreted as the probability of the theoretical cumulative sum being as small as the one we are observing. This is actually equivalent to the definition of a p-value in classical hypothesis testing.
Notice however that the above quantity currently only works in one direction, i.e. if the standardized sum is negative. In order to make this a two-sided statistic, we can ask for the probability of the standardized sum being at least as far away from the mean as our realized value. Since our sum is a scalar value, we can define ‘distance from zero’ simply as the absolute value and simplify: We can now use this probability instead of the raw standardized CUSUM sum for change point detection. Contrary to the original sum, this measure has a clear, probabilistic interpretation. For each new datapoint we directly obtain a measure of how extreme the respective observation is.
Once a certain threshold of ‘unlikeliness’ is surpassed, we mark the respective timestamp as a change point and restart the algorithm.
Roughly, the algorithm looks as follows: 0) Define 1) Collect observations
while
2) If
, calculate
3) Calculate
for
and
4) If
, detect change point and reset
In Python, a possible implementation could look as follows. I used PyTorch to allow for potential future extensions with autograd functionality:
import torch
import numpy as np
from typing import Tuple
class CusumMeanDetector():
def __init__(self, t_warmup = 30, p_limit = 0.01) -> None:
self._t_warmup = t_warmup
self._p_limit = p_limit
self._reset()
def predict_next(self, y: torch.tensor) -> Tuple[float,bool]:
self._update_data(y)
if self.current_t == self._t_warmup:
self._init_params()
if self.current_t >= self._t_warmup:
prob, is_changepoint = self._check_for_changepoint()
if is_changepoint:
self._reset()
return (1-prob), is_changepoint
else:
return 0, False
def _reset(self) -> None:
self.current_t = torch.zeros(1)
self.current_obs = []
self.current_mean = None
self.current_std = None
def _update_data(self, y: torch.tensor) -> None:
self.current_t += 1
self.current_obs.append(y.reshape(1))
def _init_params(self) -> None:
self.current_mean = torch.mean(torch.concat(self.current_obs))
self.current_std = torch.std(torch.concat(self.current_obs))
def _check_for_changepoint(self) -> Tuple[float,bool]:
standardized_sum = torch.sum(torch.concat(self.current_obs) - self.current_mean)/(self.current_std * self.current_t**0.5)
prob = float(self._get_prob(standardized_sum).detach().numpy())
return prob, prob < self._p_limit
def _get_prob(self, y: torch.tensor) -> bool:
p = torch.distributions.normal.Normal(0,1).cdf(torch.abs(y))
prob = 2*(1 - p)
return probProbabilistic CUSUM in practice
Let us try the above algorithm on two examples. First, we use the simulated, constant mean dataset from the introduction:
import matplotlib.pyplot as plt
np.random.seed(456)
torch.manual_seed(456)
segment_lengths = [np.random.randint(30,100) for _ in range(7)]
y = torch.concat([torch.normal(torch.zeros(seg_len)+np.random.uniform(-5,5),np.random.uniform()+1) for seg_len in segment_lengths])
test = CusumMeanDetector()
outs = [test.predict_next(y[i]) for i in range(len(y))]
cps = np.where(list(map(lambda x: x[1], outs)))[0]
probs = np.array(list(map(lambda x: x[0], outs)))
X, Y = np.meshgrid(np.arange(len(y)),np.linspace(-11,11))
Z = probs[X]
plt.figure(figsize=(18,9))
plt.contourf(X,Y,Z,alpha=0.3,cmap="Reds")
plt.plot(np.arange(len(y)),y.detach().numpy(),lw=0.75,label="Data",color="blue")
plt.axvline(np.cumsum(segment_lengths)[0], color="green",label="Actual changepoints",lw=2)
[plt.axvline(cp, color="green") for cp in np.cumsum(segment_lengths)[1:-1]]
plt.axvline(cps[0], color="red", linestyle="dashed",label="Detected changepoints",lw=2)
[plt.axvline(cp, color="red", linestyle="dashed",lw=2) for cp in cps[1:]]
plt.grid(alpha=0.75, linestyle="dotted",lw=2)
plt.legend()
Our modified version of CUSUM was able to detect all change points, albeit some delay in detection. However, all change points fell in regions where our probability metric already detected unusual behavior. Thus, with some fine-tuning, critical change points might have been detected even earlier.
For our second example, let us use an excerpt from the Skoltech Anomaly Benchmark dataset from Kaggle. I chose the time-series with the assumptions behind CUSUM in mind (in particular the constant mean assumption). Thus, the result should not serve as a reliable benchmark but rather as an illustrative example:
import pandas as pd
df = pd.read_csv("../data/SKAB/other/11.csv",sep=";")
df["datetime"] = pd.to_datetime(df["datetime"])
df = df.sort_values("datetime")
y = torch.tensor(df.iloc[:,5].values)
test = CusumMeanDetector()
outs = [test.predict_next(y[i]) for i in range(len(y))]
cps = np.where(list(map(lambda x: x[1], outs)))[0]
probs = np.array(list(map(lambda x: x[0], outs)))
X, Y = np.meshgrid(np.arange(len(y)),np.linspace(torch.min(y).detach().numpy(),torch.max(y).detach().numpy()))
Z = probs[X]
plt.figure(figsize=(18,9))
plt.contourf(X,Y,Z,alpha=0.3,cmap="Reds")
plt.plot(np.arange(len(y)),y.detach().numpy(),lw=0.75,label="Data",color="blue")
plt.axvline(cps[0], color="red", linestyle="dashed",label="Detected changepoints",lw=2)
[plt.axvline(cp, color="red", linestyle="dashed",lw=2) for cp in cps[1:]]
plt.grid(alpha=0.75, linestyle="dotted",lw=2)
plt.legend()
While our CUSUM variant had some problems with linear trend patterns, the overall result looks reasonable. This also demonstrates the limitations of this algorithm, once the constant mean assumption is violated. Nevertheless, despite its simplicity, CUSUM appears to be a useful choice.
Conclusion
Although CUSUM is a very simple algorithm, it can be quite powerful as long as the underlying assumptions are met. With a simple, probabilistic modification we can easily improve the standard version of CUSUM and make it more expressive and intuitive.
For more complex problems though, more sophisticated algorithms are likely necessary. One particularly useful algorithm is Bayesian Online Changepoint Detection which I can hopefully cover in the future.
Introduction
As commonly known, LSTMs (Long short-term memory networks) are great for dealing with sequential data. One such example are multivariate time-series data. Here, LSTMs can model conditional distributions for complex forecasting problems.
For example, consider the following conditional forecasting distribution: -
LSTM mean output given hidden state
-
LSTM covariance cholesky output given hidden state
Notice that we predict the cholesky decomposition of the conditional covariance matrix. This ensures that the resulting covariance matrix is positive semi-definite. Now, this approach would allow us to model quite complex dynamical problems.
On the other hand, however, the degrees of freedom in this model will rapidly explode with increasing dimensionality D of the multivariate time-series. After all, we need (D^2+D)/2 LSTM outputs for the covariance structure alone. This can clearly lead to overfitting quite easily.
Another disadvantage is the assumption of a conditionally Gaussian time-series. As soon as our time-series is not a vector of real-numbers, this model does not work anymore.
Thus, a potential solution should satisfy two properties:
- Allow to parsimoniously handle high-dimensional time-series
- Work with conditionally non-Gaussian time-series
LSTMs with Gaussian Copula
As a potential solution, we could separate the dependency among the time-series from their marginal distribution. Hence, let us presume constant conditional dependency between the time-series but varying conditional marginals. This indicates that a Copula model might be a good approach - for simplicity, we use a Gaussian Copula.
Since the basics of the Gaussian Copula have been discussed in this previous article, we won’t repeat them here.
In summary, our model looks as follows: -
-th marginal forecast density of
-th time-series -
-
-th conditional parameter vector modelled as the output of the LSTM -
Gaussian Copula density with dependency parameter matrix
-
d-th marginal forecast c.d.f. This allows us to deal with arbitrary continuous marginal distributions. In fact, we could even work with mixed continuous marginal distributions. In order to achieve sparsity in the copula parameter matrix, we could, for example, add a regularization term as is typically done when estimating high-dimensional covariance matrices.
The only drawback now is the assumption of a constant dependency over time. If this contradicts the data at hand, we might need to model the copula parameter in an auto-regressive manner as well. A low-rank matrix approach could preserve some parsimony then.
To show how this could be implemented in the case of Gaussian marginals, I have created a quick Jupyter notebook with tensorflow. Regarding the Copula part, the tensorflow example on Gaussian Copulas has a ready-made implementation using tensorflow probability bijectors.
Implementation (sketch, not too much explanations from here on)
Data taken from https://www.kaggle.com/datasets/vagifa/usa-commodity-prices. We will use only culinary oil price, presuming that there is some underlying correlation among them.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("../data/commodity-prices-2016.csv")
df = df.set_index("Date")
df.index = pd.to_datetime(df.index)
oils = df[["Olive Oil","Palm oil","Soybean Oil"]]
oils.plot(figsize=(16,8))
plt.grid(alpha=0.5)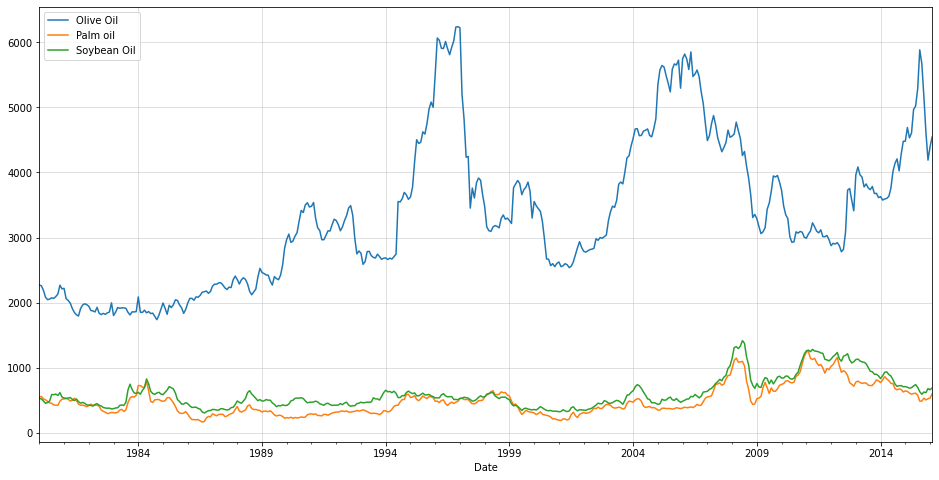
Use log-difference prices for standardization
(i.e. ‘log-returns’)
import numpy as np
oils_ld = np.log(oils).diff().iloc[1:,:]
fig, ax = plt.subplots(3,1, figsize = (16,10))
ax[0].plot(oils_ld["Olive Oil"],label="Olive Oil",color="C0")
ax[1].plot(oils_ld["Palm oil"], label="Palm oil",color="C1")
ax[2].plot(oils_ld["Soybean Oil"], label="Soybean Oil",color="C2")
[a.grid(alpha=0.5) for a in ax]
[a.legend() for a in ax]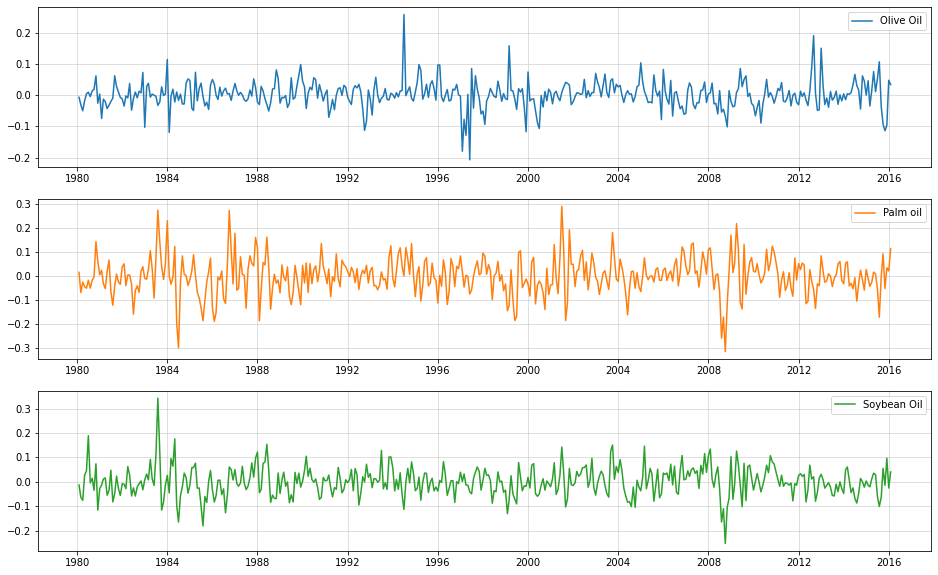
Create lag-1 features as input
We might want to go to higher lags for increased accuracy.
oils_lagged = pd.concat([oils_ld.shift(1),oils_ld],1).iloc[1:,:]
oils_lagged.columns = [c+"_l1" for c in oils_ld.columns] + list(oils_ld.columns)
oils_lagged/var/folders/2d/hl2cr85d2pb2kfbmsng3267c0000gn/T/ipykernel_61976/3710246824.py:1: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only.
oils_lagged = pd.concat([oils_ld.shift(1),oils_ld],1).iloc[1:,:]| Olive Oil_l1 | Palm oil_l1 | Soybean Oil_l1 | Olive Oil | Palm oil | Soybean Oil | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 1980-03-01 | -0.006731 | 0.014993 | -0.013089 | -0.030768 | -0.069312 | -0.063604 |
| 1980-04-01 | -0.030768 | -0.069312 | -0.063604 | -0.050111 | -0.025850 | -0.076200 |
| 1980-05-01 | -0.050111 | -0.025850 | -0.076200 | -0.017756 | -0.045196 | 0.026527 |
| 1980-06-01 | -0.017756 | -0.045196 | 0.026527 | 0.004272 | -0.050933 | 0.046044 |
| 1980-07-01 | 0.004272 | -0.050933 | 0.046044 | 0.009627 | -0.018182 | 0.189117 |
| ... | ... | ... | ... | ... | ... | ... |
| 2015-10-01 | -0.036858 | -0.002459 | -0.063183 | -0.092682 | 0.092317 | 0.055295 |
| 2015-11-01 | -0.092682 | 0.092317 | 0.055295 | -0.114045 | -0.052427 | -0.014648 |
| 2015-12-01 | -0.114045 | -0.052427 | -0.014648 | -0.096288 | 0.034072 | 0.096772 |
| 2016-01-01 | -0.096288 | 0.034072 | 0.096772 | 0.047791 | 0.020941 | -0.025876 |
| 2016-02-01 | 0.047791 | 0.020941 | -0.025876 | 0.033650 | 0.114146 | 0.040106 |
432 rows × 6 columns
X_train = oils_lagged.iloc[:-12,:3].values
y_train = oils_lagged.iloc[:-12,3:].values
X_test = oils_lagged.iloc[-12:,:3].values
y_test = oils_lagged.iloc[-12:,3:].valuesCreate the model (https://www.tensorflow.org/probability/examples/Gaussian_Copula#:~:text=Gaussian-,Copula,-To%20illustrate%20how)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
class GaussianCopulaTriL(tfd.TransformedDistribution):
def __init__(self, loc, scale_tril):
super(GaussianCopulaTriL, self).__init__(
distribution=tfd.MultivariateNormalTriL(
loc=loc,
scale_tril=scale_tril),
bijector=tfb.NormalCDF(),
validate_args=True,
name="GaussianCopulaTriLUniform")
class CopulaLSTMModel(tf.keras.Model):
def __init__(self, input_dims=3, output_dims=3):
super().__init__()
self.input_dims = input_dims
self.output_dims = output_dims
#use LSTM state to ease training and testing state transition
self.c0 = tf.Variable(tf.ones([1,input_dims]), trainable = True)
self.h0 = tf.Variable(tf.ones([1,input_dims]), trainable = True)
self.lstm = layers.LSTM(input_dims,
batch_size=(1,1,input_dims),
return_sequences=True,
return_state=True
)
self.mean_layer = layers.Dense(output_dims)
self.std_layer = layers.Dense(output_dims,activation=tf.nn.softplus)
self.chol = tf.Variable(tf.random.normal((output_dims,output_dims)), trainable = True)
def call(self, inputs):
lstm_out = self.lstm(inputs, initial_state = [self.c0, self.h0])[0]
means = self.mean_layer(lstm_out)
stds = self.std_layer(lstm_out)
distributions = tfd.Normal(means, stds)
return distributions
def call_with_state(self, inputs, c_state, h_state):
#explicitly use and return the initial state - primarily for forecasting
lstm_out, c_out, h_out = self.lstm(inputs, initial_state = [c_state, h_state])
means = self.mean_layer(lstm_out)
stds = self.std_layer(lstm_out)
distributions = tfd.Normal(means, stds)
return distributions, c_out, h_out
def get_normalized_covariance(self):
unnormalized_covariance = self.chol@tf.transpose(self.chol)
normalizer = tf.eye(self.output_dims) * 1./(tf.linalg.tensor_diag_part(unnormalized_covariance)**0.5)
return normalizer@unnormalized_covariance@normalizer
def conditional_log_prob(self, inputs, targets):
marginals = self.call(inputs)
marginal_lpdfs = tf.reshape(marginals.log_prob(targets),(-1,self.output_dims))
copula_transformed = marginals.cdf(y_train)
normalized_covariance = self.get_normalized_covariance() #need covariance matrix with unit diagonal for Gaussian Copula
copula_dist = GaussianCopulaTriL(loc=tf.zeros(self.output_dims),scale_tril = tf.linalg.cholesky(normalized_covariance))
copula_lpdfs = copula_dist.log_prob(copula_transformed)
return tf.reduce_mean(tf.math.reduce_sum(marginal_lpdfs,1) + copula_lpdfs)
def train_step(self, data):
#custom training steps due to custom loglikelihood-loss
x, y = data
with tf.GradientTape() as tape:
loss = -self.conditional_log_prob(x,y)
trainable_vars = self.trainable_weights + self.lstm.trainable_weights + self.mean_layer.trainable_weights + self.std_layer.trainable_weights
gradients = tape.gradient(loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
return {"Current loss": loss}
def sample_forecast(self, X_train, y_train, forecast_periods = 12):
#this is still quite slow; should be optimized if used for a real-world problem
normalized_covariance = self.get_normalized_covariance()
copula_dist = tfp.distributions.MultivariateNormalTriL(scale_tril = tf.linalg.cholesky(normalized_covariance))
copula_sample = tfp.distributions.Normal(0,1).cdf(copula_dist.sample(forecast_periods))
sample = []
input_current = y_train
for t in range(forecast_periods):
_, c_current, h_current = self.lstm(X_train)
new_dist, c_current, h_current = self.call_with_state(tf.reshape(input_current,(1,1,self.input_dims)), c_current, h_current)
input_current = new_dist.quantile(tf.reshape(copula_sample[t,:],(1,1,self.output_dims)))
sample.append(tf.reshape(input_current,(1,self.output_dims)).numpy().reshape(1,self.output_dims))
return np.concatenate(sample)Train the model
np.random.seed(123)
tf.random.set_seed(123)
test = CopulaLSTMModel()
test.compile(optimizer="adam")
test.fit(X_train.reshape(1,-1,3),y_train.reshape(1,-1,3), epochs = 250, verbose=0) #relatively fast<keras.callbacks.History at 0x1469271c0>Raw log-diff predictions
np.random.seed(123)
tf.random.set_seed(123)
samples = [test.sample_forecast(X_train.reshape(1,-1,3),y_train[-1,:].reshape(1,1,3)) for _ in range(500)] #very slow, grab a coffee or two
samples_restructured = [np.concatenate(list(map(lambda x: x[:,i].reshape(-1,1),samples)),1) for i in range(3)]
means = [np.mean(s,1) for s in samples_restructured]
lowers = [np.quantile(s,0.05,1) for s in samples_restructured]
uppers = [np.quantile(s,0.95,1) for s in samples_restructured]
fig, ax = plt.subplots(3,1, figsize = (16,10))
[ax[i].plot(y_test[:,i],label=oils.columns[i],color="C{}".format(i)) for i in range(3)]
[ax[i].plot(means[i], label = "Mean forecast", color = "red") for i in range(3)]
[ax[i].fill_between(np.arange(len(y_test)),lowers[i],uppers[i], label = "Forecast interval", color="red", alpha=0.2) for i in range(3)]
[a.grid(alpha=0.5) for a in ax]Actual price predictions
samples_retrans = [np.exp(np.log(oils.iloc[-13,i+3])+np.cumsum(samples_restructured[i],0)) for i in range(3)]
means_retrans = [np.mean(s,1) for s in samples_retrans]
lowers_retrans = [np.quantile(s,0.025,1) for s in samples_retrans]
uppers_retrans = [np.quantile(s,0.975,1) for s in samples_retrans]
fig, ax = plt.subplots(3,1, figsize = (16,10))
[ax[i].plot(oils.values[:,i],label=oils.columns[i],color="C{}".format(i)) for i in range(3)]
[ax[i].set_xlim((1,len(oils))) for i in range(3)]
[ax[i].plot(np.arange(len(oils)-13,len(oils)),np.concatenate([[oils.iloc[-13,i]],means_retrans[i]]), label = "Mean forecast", color = "purple") for i in range(3)]
[ax[i].fill_between(np.arange(len(oils)-13,len(oils)),np.concatenate([[oils.iloc[-13,i]],lowers_retrans[i]]),np.concatenate([[oils.iloc[-13,i]],uppers_retrans[i]]), label = "Forecast interval", color="purple", alpha=0.2) for i in range(3)]
[a.grid(alpha=0.5) for a in ax]Sample trajectories
fig, ax = plt.subplots(3,1, figsize = (16,10))
for s in range(500):
[ax[i].plot(np.arange(len(oils)-13,len(oils)),np.concatenate([[oils.iloc[-13,i+3]],samples_retrans[i][:,s]]), label = "Mean forecast", color = "purple", lw=0.1) for i in range(3)]
[ax[i].plot(oils.values[:,i],label=oils.columns[i],color="C{}".format(i), lw=5) for i in range(3)]
[ax[i].set_xlim((375,len(oils))) for i in range(3)]
[a.grid(alpha=0.5) for a in ax]Conclusion
This was just a rough collection of ideas on how a Copula-LSTM time-series model could look like. Feel free to contact me for more information.
References
[1] Hochreiter, Sepp; Schmidhuber, Jürgen. Long short-term memory. Neural computation, 1997, 9.8, p. 1735-1780.
[2] Nelsen, Roger B. An introduction to copulas. Springer Science & Business Media, 2007.
Introduction
For financial time-series data, GARCH (Generalized AutoRegressive Conditional Heteroscedasticity) models play an important role. While forecasting mean returns is usually futile, stock volatility appears to be predictable, at least to some extent. However, standard GARCH relies on the potentially limiting assumption of conditional Gaussian data.
Just like last time, we could use a Copula approach to remove such Gaussianity assumptions. Given that stock time-series typically have a lot of observations, a more flexible approach might be superior. In fact, it would be great if our model could simply infer the conditional distribution from the data provided.
A popular approach in Machine Learning to such problems are Normalizing Flows. In summary, Normalizing Flows allow to transform a known base distribution to a complex one in a differentiable manner. Let us briefly look at the technicalities:
A short intro to Normalizing Flows
When choosing a probability model, we typically see a trade-off between flexibility and tractability. While the Gaussian distribution is nice to work with, real world data is obviously much more complex on most occasions.
On the other extreme, we see modern generative models like GANs that can produce complex data at the cost of an intractable distribution. This requires the use of sampling estimators for parameter estimation which can be quite inefficient.
Somewhere in the middle, we have Normalizing Flows. One the one hand, the expressiveness of Normalizing Flows might still be too limited for advanced image generation. Nonetheless, they are likely sufficient as a replacement for a mere Normal distribution.
The core principle behind Normalizing Flows
At the heart of Normalizing Flows, we have the change-of-variables formula. The latter tells us how the density of a random variable changes under monotone transformations. As we are only interested in transformations of univariate variables, we will focus on the respective variant:
Let
denote the probability density of a (univariate) random variable
. Let
denote a strictly monotonic transformation. For the probability density
of
we have :
In summary, this formula allows us to generate new random variables from known ones. At the same time, we can calculate the probability density of the derived random variable in closed form. Of course, the limiting factor here is the restriction of to strictly monotonic functions. As we will see, however, this still leaves plenty of room for reasonably flexible distributions.
In Normalizing Flows, we now make the following crucial observation:
Chaining strictly monotonic functions results in another, more complex strictly monotonic function.
Put into an equation, this looks as follows:
Let
be strictly monotonic. It then follows that
is also strictly monotonic.
If we define the outcome variable after the m-th transformation as we can derive the (log-) density for the resulting variable after the M-th transformation by applying the chain rule:
which can then be used for maximum likelihood optimization. Notice that we used the inverse function theorem to exchange the transformation with its inverse.
Now, all boils down to a reasonable choice of the component-wise transformations.
Planar Normalizing Flows
A simple type of Normalizing Flows are Planar Normalizing Flows defined as where
denotes a smooth, non-linear function. The corresponding derivative is
This looks quite similar to residual layers in Residual Neural Networks. Thanks to the residual x in the left summand, the requirements on h are more loose than the initial monotonicity assumption. A common choice for the latter is simply the
tanh function.
Intuitively, the Planar Flow takes the original variable and adds a non-linear transformation. We can expect the result to resemble the input with some variation, depending on the magnitude of and
.
To run our experiments, we can use the Bijectors.jl package which conveniently contains a Planar Flow layer:
using Distributions, Plots, StatsPlots, Bijectors, Random
Random.seed!(321)
baseDist = MvNormal(zeros(1),ones(1)) #standard Gaussian as vector random variable Bijectors.PlanarLayer expects vector valued r.v.s
planarLayer1 = PlanarLayer([0.5],[1.],[0.])
planarLayer2 = PlanarLayer([1.],[1.],[-1.])
planarLayer3 = PlanarLayer([5.],[2.],[-2.])
flowDist1 = transformed(baseDist, planarLayer1)
flowDist2 = transformed(baseDist, planarLayer2)
flowDist3 = transformed(baseDist, planarLayer3)
line = Matrix(transpose(collect(-4:0.01:4)[:,:]))
base_plot = plot(line[:],pdf(baseDist,line)[:],legend=:none,title = "Standard Gaussian base distribution", fmt=:png)
flow1_plot = plot(line[:],pdf(flowDist1,line)[:],legend=:none,title = "Planar Flow - low non-linearity", fmt=:png)
flow2_plot = plot(line[:],pdf(flowDist2,line)[:],legend=:none,title = "Planar Flow - medium non-linearity", fmt=:png)
flow3_plot = plot(line[:],pdf(flowDist3,line)[:],legend=:none,title = "Planar Flow - strong non-linearity", fmt=:png)
flow_plot = plot(flow1_plot, flow2_plot, flow3_plot,layout = (1,3))
plot(base_plot, flow_plot, layout = (2,1), size = (1200,600))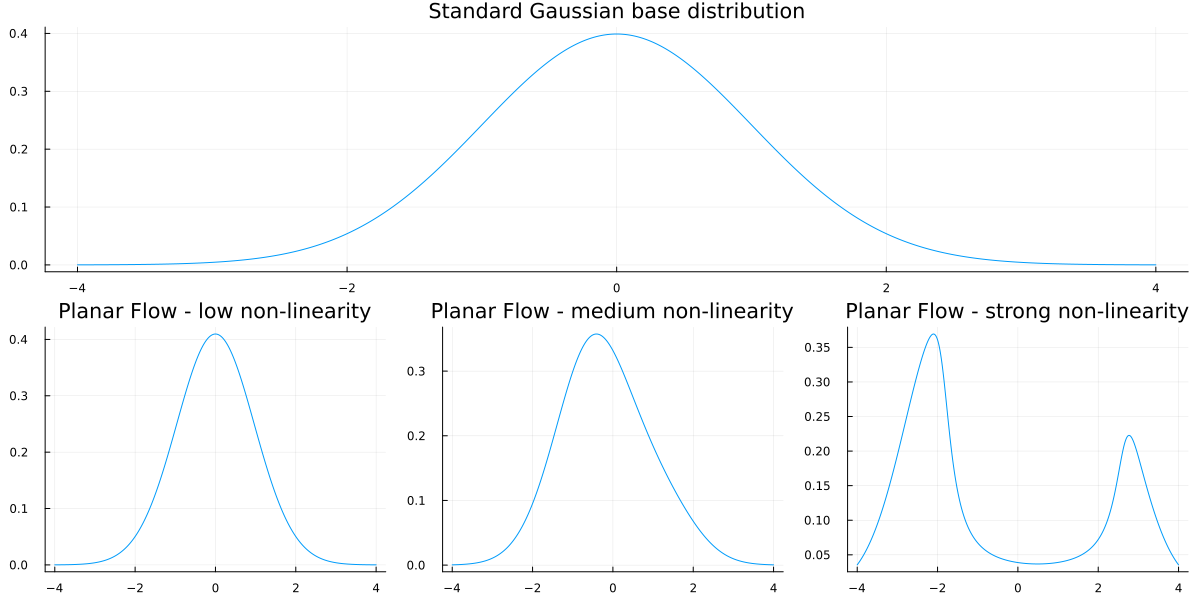
Non-Gaussian GARCH via Planar Normalizing Flows
By combining GARCH with Normalizing Flows, we aim for two goals:
- Remove the assumption of conditional Gaussian realizations while, at the same time
- Preserve the autoregressive volatility property that is inherent to GARCH models
For this article, we will focus on a simple GARCH(1,1) model. In an applied setting, we would want to try out different GARCH models and select the best one(s).
Recall that, for GARCH(1,1) with zero mean, we have: With the above restrictions, the GARCH model can be shown to be stationary. While the conditional distributions are all Gaussian, the unconditional ones are not.
Now, in order to combine this with Normalizing Flows, we apply the following transformation: where
is a Normalizing Flow
This choice can be justified by the fact that a 1D Normalizing Flow is a monotone transformation and by the invariance property of quantiles: > Let denote the
-quantile of univariate random variable
In addition, let
denote a monotone transformation then
With this result, we can draw the following conclusions about the transformed GARCH process: has constant median,
If , then
and
This follows via
(where
the
-th quantile of a standard Normal) and therefore,
similarly for
Thus, the risk of extreme events for the transformed process moves in conjunction with the underlying GARCH process. We could probably derive results for the variance of the Planar Flow GARCH as well. However, this might potentially turn this post into a full-fledged research paper so we shall content ourselves with the above.
Either way, we now have reassurance that our process will react to random shocks in a similar way as plain GARCH.
Simulating a Planar Flow GARCH(1,1) process
After clarifying the fundamentals of our model, we are ready for a quick simulation. For that, let us re-use the highly non-linear Planar Flow from before. The remaining model parameters are drawn from a standard Gaussian and mapped to the correct domains during inference:
using Flux
struct PF_GARCH #(=Planar-Flow-GARCH)
sigma0 #prior variance
gamma
alpha
beta
flow
end
Flux.@functor PF_GARCH #for differentiability later on
function simulate(m::PF_GARCH, T=250)
gamma = softplus(m.gamma[1,1])
alpha = σ(m.alpha[1,1])
beta = σ(m.beta[1,1]) * (1-alpha) #constrain alpha and beta to sum to < 1
sigeps = zeros(2,T+1)
sigeps[1,1] = softplus(m.sigma0[1,1])
for t in 2:T+1
sigeps[1,t] = sqrt(gamma + alpha * sigeps[1,t-1]^2 + beta * sigeps[2,t-1]^2)
sigeps[2,t] = randn()*sigeps[1,t]
end
return m.flow(sigeps[2:2,2:end])[:]
end
Random.seed!(123)
pf_garch = PF_GARCH(randn(1,1), randn(1,1), randn(1,1), randn(1,1), PlanarLayer([5.],[2.],[-2.]))
pf_garch_draw = simulate(pf_garch)
gauss_garch_draw = inverse(pf_garch.flow)(Matrix(transpose(pf_garch_draw[:,:])))[:]
plot(pf_garch_draw,label="Planar Flow GARCH",size=(1000,500),fmt=:png,lw=2)
plot!(gauss_garch_draw,label="Latent Gaussian GARCH",lw=2,color="red")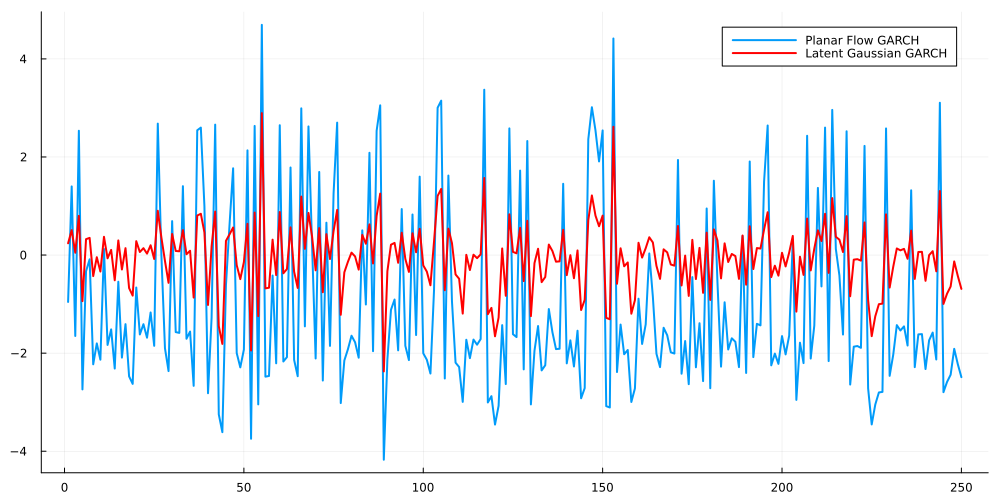
If we take a close look at the graph, we see that Planar Flow GARCH produces values that are either pretty large or pretty low. By scrolling back to the Planar Flow density plots, we see that this makes indeed sense. In fact, the Gaussian-large-non-linear flow generated a bi-modal distribution at around -3 and +3. This matches, approximately, the distribution of values that we see in the Planar Flow GARCH chart.
Planar Flow GARCH on a real-world time series
To validate our model, we can fit it on a stock return time-series and analyze the result. Let us use the Apple adjusted close price as our dataset. I downloaded the data from Yahoo Finance - you can replicate it via this link.
As our target time-series, we use log-returns. Also, we standardize them by subtracting their mean and dividing by their standard deviation. If you look at the range of values of the sample Planar Flow GARCH, this standardization makes sense as log-returns are typically on a much smaller scale. Afterwards, we can easily rescale our results back to actual log-returns.
using CSV, DataFrames, Flux, Zygote, Distributions
adj_close = (CSV.File("../data/AAPL.csv") |> DataFrame)[!,"Adj Close"]
rets = diff(log.(adj_close))
ym = mean(rets)
ys = std(rets)
rets = (rets.-ym)./ys
plot(rets, legend=:none, title = "AAPL log-returns of adjusted close price (standardized)", size = (1000,500),fmt=:png)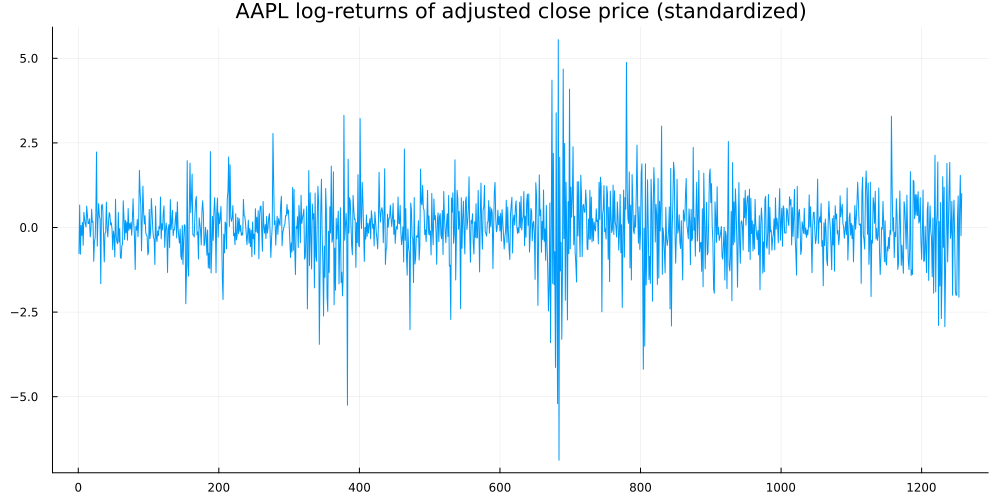
Next, we define the model log-likelihood and use the ADAM optimizer for first-order optimization. By projecting the parameters via softplus and sigmoid, we can perform unconstrained optimization. Unfortunately, Julias AutoDiff packages all errored on the Hessian matrix. Thus, the current implementation does not seem to permit second-order optimization.
For our implementation, we can mostly rely on Distributions.jl and Bijectors.jl. The latter makes the implementation of nested (deep) Planar Flows quite convenient.
using Zygote
function Distributions.logpdf(m::PF_GARCH,y)
T = size(y,2)
inverse_flow = inverse(m.flow)
ytilde = inverse_flow(y) #get the underlying Gaussian GARCH
sigeps = Zygote.Buffer(zeros(2,T+1)) #stores sigma_t (1st row) and epsilon_t (2nd row)
sigeps[2,1] = 0. #set initial epsilon to zero
sigeps[1,1] = softplus(m.sigma0[1,1])
gamma = softplus(m.gamma[1,1])
alpha = σ(m.alpha[1,1])
beta = σ(m.beta[1,1]) * (1-alpha) #constrain alpha and beta to sum to < 1
for t in 2:T+1
sigeps[1,t] = sqrt(gamma[1,1] + alpha[1,1] * sigeps[1,t-1]^2 + beta[1,1] * sigeps[2,t-1]^2) #sigma_t
sigeps[2,t] = ytilde[t-1]/sigeps[1,t] #epsilon_t
end
vars = copy(sigeps)
dists = map(x->MvNormal(zeros(1),x),vars[1,2:end].^2)
flows = Flux.unsqueeze(transformed.(dists,m.flow),1)
lpdfs = Zygote.Buffer(zeros(T),T)
for t in 1:T
lpdfs[t] = logpdf(flows[t],[y[t]]) #Bijectors.Composed flow expects vector valued variables
end
return mean(copy(lpdfs))
end
retsm = Matrix(transpose(rets[:,:])) #Bijectors.jl flows treat 1xN matrices as N observations from a single-value vector valued r.v.
pf_garch = PF_GARCH(zeros(1,1), zeros(1,1), zeros(1,1), zeros(1,1), PlanarLayer([0.5],[1.],[0.1])∘PlanarLayer([0.5],[1.],[0.1])∘PlanarLayer([0.5],[1.],[0.1]))
params = Flux.params(pf_garch)
opt = ADAM(0.025)
for i in 1:1000 #first-order optimization takes quite some time
grads = Zygote.gradient(()->-logpdf(pf_garch,retsm),params)
Flux.Optimise.update!(opt,params,grads)
end;The Planar Flow GARCH model after optimization
In order to check the outcome, let us plot several perspective. First, we start with in-sample and out-of-sample (=forecast) point predictions and predictive intervals. For the former, we use the median as we can calculate it analytically by applying the Normalizing Flow to the Gaussian median. Similarly, we can derive the 5% and 95% quantiles of the transformed variable via the respective Gaussian quantiles.
Additionally, notice that we need to integrate out the unrealized noise terms for the forecast distributions, i.e.: if
lies inside the forecast interval
As this would be tedious, we will use our model to sample from the forecast distribution and integrate the noise out implicitly.
function get_insample_distributions(m::PF_GARCH, y)
T = size(y,2)
inverse_flow = inverse(m.flow)
ytilde = inverse_flow(y)
gamma = softplus(m.gamma[1,1])
alpha = σ(m.alpha[1,1])
beta = σ(m.beta[1,1]) * (1-alpha) #constrain alpha and beta to sum to < 1
sigeps_insample = zeros(2,T+1) #stores sigma_t (1st row) and epsilon_t (2nd row)
sigeps_insample[1,1] = softplus(m.sigma0[1,1])
for t in 2:T+1
sigeps_insample[1,t] = sqrt(gamma + alpha * sigeps_insample[1,t-1]^2 + beta * sigeps_insample[2,t-1]^2)
sigeps_insample[2,t] = ytilde[t-1]/(sigeps_insample[1,t]+1e-6)
end
dists_insample = map(x->MvNormal(zeros(1),x),sigeps_insample[1,2:end].^2)
flows_insample = Flux.unsqueeze(transformed.(dists_insample,m.flow),1)
dists_insample = map(x->MvNormal(zeros(1),x),sigeps_insample[1,2:end].^2)
flows_insample = Flux.unsqueeze(transformed.(dists_insample,m.flow),1)
return flows_insample, sigeps_insample
end
function sample_forecast(m::PF_GARCH, sigeps_insample, forecast_periods=60)
gamma = softplus(m.gamma[1,1])
alpha = σ(m.alpha[1,1])
beta = σ(m.beta[1,1]) * (1-alpha) #constrain alpha and beta to sum to < 1
sigeps_forecast = zeros(2,forecast_periods+1) #stores sigma_t (1st row) and epsilon_t (2nd row)
sigeps_forecast[1,1] = sigeps_insample[1,end]
sigeps_forecast[2,1] = sigeps_insample[2,end]
for t in 2:forecast_periods+1
sigeps_forecast[1,t] = sqrt(gamma + alpha * sigeps_forecast[1,t-1]^2 + beta * sigeps_forecast[2,t-1]^2)
sigeps_forecast[2,t] = randn()
end
dists_forecast = map(x->MvNormal(zeros(1),x),sigeps_forecast[1,:].^2)
flows_forecast = Flux.unsqueeze(transformed.(dists_forecast,m.flow),1)
return vcat(rand.(flows_forecast)[:]...)
end
#--------------------------
pf_garch_insample, sigeps_insample = get_insample_distributions(pf_garch,retsm)
pf_garch_5perc_quantile = [r.transform([quantile(Normal(0,sqrt(r.dist.Σ[1])),0.05)])[1] for r in pf_garch_insample][:] .* ys .+ ym
pf_garch_95perc_quantile = [r.transform([quantile(Normal(0,sqrt(r.dist.Σ[1])),0.95)])[1] for r in pf_garch_insample][:] .* ys .+ ym
pf_garch_median = [r.transform([quantile(Normal(0,sqrt(r.dist.Σ[1])),0.5)])[1] for r in pf_garch_insample][:].* ys .+ ym
forecast = hcat([sample_forecast(pf_garch, sigeps_insample) for _ in 1:75000]...) .* ys .+ ym
forecast_5perc_quantile = mapslices(x->quantile(x,0.05),forecast,dims=2)[:]
forecast_95perc_quantile = mapslices(x->quantile(x,0.95),forecast,dims=2)[:]
forecast_median = mapslices(x->quantile(x,0.5),forecast,dims=2)[:]
plot(pf_garch_median,
ribbon = (pf_garch_median.-pf_garch_5perc_quantile,pf_garch_95perc_quantile.-pf_garch_median),
lw=2,size=(1000,500), fmt=:png, label = "Insample point and interval predictions")
plot!(collect(length(rets):60+length(rets)),forecast_median,ribbon = (forecast_median.-forecast_5perc_quantile,forecast_95perc_quantile.-forecast_median),
lw=2,color="green", label="60 days ahead forecast")
plot!(rets.* ys .+ ym, alpha=0.5,color="red",lw=0.5, label="Realized returns")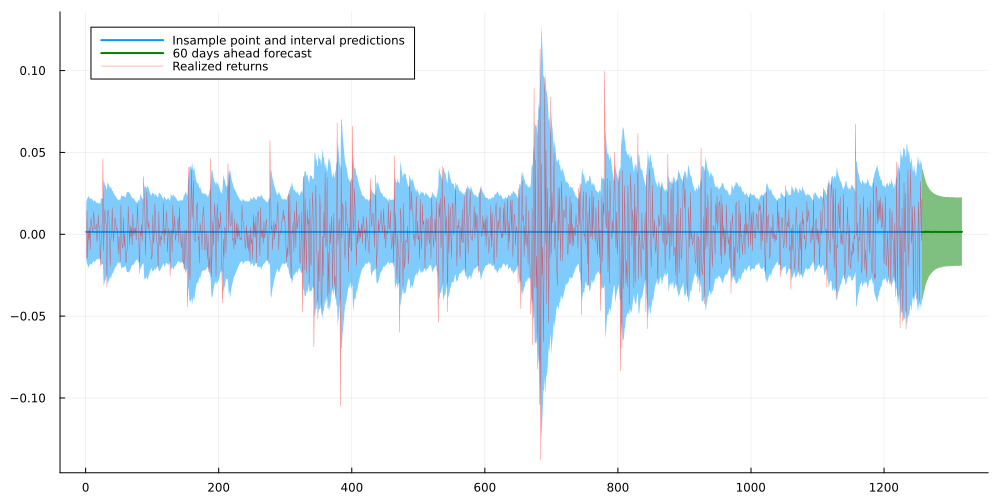
Both in- and out-of-sample predictive intervals and point predictions look reasonable. In case we preferred to use the mean instead of the median as the point estimate, we could, for example, use Monte Carlo samples to estimate the former.
In a real-world scenario, we might want to take a closer look at the forecast predictive interval. As a matter of fact, it appears a little too small and might actually under-estimate potential risk. Apart from that, however, the model seems to correctly depict the typical GARCH volatility clusters.
Finally, let us check the conditional distributions after the largest and smallest amplitudes. This gives us a visual impression of how far our model deviates from Gaussian conditional returns as in standard GARCH.
plot(collect(-10:0.01:10).* ys .+ ym,[pdf(pf_garch_insample[argmin(rets.^2)+1],[x]) for x in collect(-10:0.01:10)],
size=(1000,500), label = "Conditional distribution at t+1 after smallest return amplitude", legendfontsize=7)
plot!(collect(-10:0.01:10).* ys .+ ym,[pdf(pf_garch_insample[argmax(rets.^2)+1],[x]) for x in collect(-10:0.01:10)],
label = "Conditional distribution at t+1 after highest return amplitude", legendfontsize=7)
Indeed, our model is highly non-Gaussian. Also, as expected, the conditional return distribution clearly spreads out after large returns amplitudes - i.e. volatility increases after shocks.
GARCH and Normalizing Flows - Conclusion
In this article, we took a timeless model from quantitative finance and combined it with a popular machine learning approach. The outcome is quite interesting insofar as it can infer conditional return distribution from data. This is in contrast to classic statistical models where the user typically fixes the distribution ex-ante. As long as the time-series is long enough, this might yield better predictive results. After all, Gaussian and related distributional assumptions often simplify the real world too far.
To improve the model further from here, we might want to consider more complex GARCH dynamics. The GARCH(1,1) was mainly for convenience and higher order GARCH models would likely be better suited.
Besides that, we could use a more sophisticated version of GARCH altogether. You might want to take a look at Wikipedia for a non-exhaustive list of advanced versions of GARCH. Finally, we could also replace the Planar Flows with more advanced alternatives. As an example, consider Sylvester Flows which generalize Planar Flows.
As always though, we should not fool ourselves by choosing the complex ML-ish approach just because that is trendy. Rather, all candidate models should be carefully evaluated against each other. Nevertheless, it would be interesting to check if this approach could be useful for an actual real-world trading strategy.
References
[1] Bollerslev, Tim. Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 1986, 31. 3, p. 307-327.
[2] Rezende, Danilo; Mohamed, Shakir. Variational inference with normalizing flows. In: International conference on machine learning. PMLR, 2015. p. 1530-1538.
[3] Kobyzev, Ivan; Prince, Simon JD; Brubaker, Marcus A. Normalizing flows: An introduction and review of current methods. IEEE transactions on pattern analysis and machine intelligence, 2020, 43. 11, p. 3964-3979.
Introduction
ARMA (AutoRegressive – Moving Average) models are arguably the most popular approach to time-series forecasting. Unfortunately, plain ARMA is made for Gaussian distributed data only. On the one hand, you can often still use ARMA by transforming the raw data. On the other hand, this typically makes probabilistic forecasts quite tedious.
One approach to apply ARMA to non-Normal data are Copula models. Roughly, the latter allow us to exchange the Gaussian marginal for any other continuous distribution. At the same time, they preserve the implicit time-dependency between observations that is imposed by ARMA.
If this sounds confusing, I suggest reading the next paragraph carefully. Also, you might want to read some external sources for a deeper understanding, too.
What are Copulas and how can we use them with ARMA?
Informally, Copulas (or Copulae if you are a Latin hardliner) define joint cumulative distribution functions (c.d.f.) for unit-uniform random variables. Formally, we can describe this as That property alone is quite unspectacular as uniform random variables are not very expressive for practical problems. However, an important result in probability theory will make things more interesting.
The probability integral transform states that we can transform any continuous random variable to a uniform one by plugging it into its own c.d.f.:
Let
, then
We can verify this empirically for a standard Normal example:
using Distributions, Plots, StatsPlots, Random
Random.seed!(123)
sample = rand(Normal(),10000)
transformed_sample = cdf.(Normal(), sample)
line = collect(-3:0.01:3)
line_transformed = collect(0:0.1:1)
p_sample = histogram(sample,normalize=true, label=:none,title = "Gaussian sample",fmt=:png)
plot!(p_sample, line, pdf.(Normal(),line),color=:red,lw=3,label="Theoretical density",fmt=:png)
p_transformed = histogram(transformed_sample,normalize=true, label=:none,legend=:bottomright,title="Transformed sample",fmt=:png)
plot!(p_transformed, line_transformed, pdf.(Uniform(),line_transformed),color=:red,lw=3,label="Theoretical density",fmt=:png)
plot(p_sample,p_transformed,size=(1200,600),fmt=:png)
As the inverse of a c.d.f. is the quantile function, we can easily invert this transformation. Even cooler, we can transform a uniform random variable to any continuous random variable via This inverse transformation will become relevant later on.
Combining Copulas and the inverse probability transform
In conjunction with Copulas, this allows us to separate the marginal distributions from the dependency structure of joint random variables.
A concrete example: Consider two random variables, and
with standard Gamma and Beta marginal distributions, i.e.
With the help of a Copula and the probability integral transform, we can now define a joint c.d.f over both variables such that we preserve their marginal distributions:
Introducing the Gaussian Copula
So far, we haven’t specified any Copula function yet. A simplistic one is the Gaussian Copula, which is defined as follows: If we combine this with the Gamma-Beta example from before, we get the following Gaussian Copula joint c.d.f.:
The implicit rationale behind this approach can be described in three steps:
- Transform the Gamma and Beta marginals into Uniform marginals via the respective c.d.f.s
- Transform the Uniform marginals into standard Normal marginals via the quantile functions
- Define the joint distribution via the multivariate Gaussian c.d.f. with zero mean, unit variance and non-zero covariance (covariance matrix R)
By inverting these steps, we can easily sample from a bi-variate random variable that has the above properties. I.e. standard Gamma/Beta marginals with Gaussian Copula dependencies:
- Draw a sample from a bi-variate Gaussian with mean zero, unit variance and non-zero covariance (covariance matrix R). You now have two correlated standard Gaussian variables.
- Transform both variables with the standard Gaussian c.d.f. - you now have two correlated Uniform variables. (= probability integral transform)
- Transform these variables with the standard Beta and Gamma quantile functions - you now have a pair of correlated Gamma-Beta variables. (= inverse probability integral transform)
Notice that we could drop the zero-mean, unit-variance assumption on the multivariate Gaussian. In that case we would have to adjust the Gaussian c.d.f. to the corresponding marginals in order to keep the integral probability transform valid.
Since we are only interested in the dependency structure (i.e. covariances), standard Gaussian marginals are sufficient and easier to deal with.
Now let us sample some data in Julia:
using Measures, Random
Random.seed!(123)
#Step 1: Sample bi-variate Gaussian data with zero mean and unit variance
mu = zeros(2)
R = [1 0.5; 0.5 1]
sample = rand(MvNormal(mu,R),10000)
#Step 2: Transform the data via the standard Gaussian c.d.f.
sample_uniform = cdf.(Normal(), sample)
#Step 3: Transform the uniform marginals via the standard Gamma/Beta quantile functions
sample_transformed = sample_uniform
sample_transformed[1,:] = quantile.(Gamma(),sample_transformed[1,:])
sample_transformed[2,:] = quantile.(Beta(),sample_transformed[2,:])
#Plot the result
scatterplot = scatter(sample_transformed[1,:],sample_transformed[2,:],title="Joint sample",
legend=:none,fmt=:png,xlab="Gamma marginal", ylab="Beta marginal")
gamma_line = collect(0:0.1:10)
g_plot = histogram(sample_transformed[1,:],normalize=true, label=:none,title = "Gamma marginal",fmt=:png)
plot!(g_plot, gamma_line, pdf.(Gamma(),gamma_line),color=:red,lw=3,label="Theoretical density",fmt=:png)
beta_line = collect(0:0.01:1)
b_plot = histogram(sample_transformed[2,:],normalize=true, label=:none,legend=:bottomright,title="Beta marginal",fmt=:png)
plot!(b_plot, beta_line, pdf.(Beta(),beta_line),color=:red,lw=3,label="Theoretical density",fmt=:png)
plot(scatterplot,plot(g_plot,b_plot),layout=(2,1),size=(1200,600),fmt=:png,margin=7.5mm)
Congratulations, you have just sampled from your first Copula model!
But wait - I want to fit a model!
Let’s say we observed the above data without the underlying generating process. We only presume that we know that Gamma-Beta marginals and a Gaussian copula are a good choice. How could we fit the model parameters (i.e. ‘learn’ them in the Machine Learning world)?
As often for statistical models, Maximum Likelihood is a good approach. However, we need a density function for that, so what do we do? We already found out, that a Copula model describes a valid c.d.f. for continuous marginals. Thus, we can derive the corresponding probability density by taking derivatives: (where
is called a ‘Copula density function’;
denotes a probability density function)
Now, for the Gaussian Copula, one can prove the following Copula density function:
ARMA with non-normal data via Copulas
Finally, we can return to our initial problem. For this example, we will focus on the stationary ARMA(1,1) model: For a time-series with
observations, we can derive the unconditional, stationary distribution (see e.g. here):
where
the ARMA
auto-covariance function for lag
:
Informally, the unconditional distribution considers a fixed-length time-series as a single, multivariate random vector. As a consequence, it doesn’t matter whether we are sampling from the unconditional distribution or the usual ARMA equations (for an equally long time-series) themselves.
In some instances, such as this one, the unconditional distribution is easier to work with.
Also, notice that the unconditional marginal distributions (the distributions of the y_t’s) are the same regardless of the time-lag we are looking at. In fact, we have zero-mean Gaussians with variance equal to the auto-covariance function at zero.
Next, let us define: The transformed covariance matrix now implies unit variance while preserving the dependency structure of the unconditional time-series. Literally, we have just derived the correlation matrix but let us stick to the idea of a standardized covariance matrix.
If we plug this back into a Gaussian copula, we obtain what we could call an ARMA(1,1) Copula. Now, we could use the ARMA(1,1) Copula dependency structure together with any continuous marginal distribution. For example, we could define i.e. the unconditional marginals are Exponential-distributed with rate parameter 0.5. Putting everything together, we obtain the following unconditional density:
Let us combine everything so far and plot an example:
using LinearAlgebra
struct ARMA_1_1
phi
theta
sigma
end
Broadcast.broadcastable(m::ARMA_1_1) = (m,)
function construct_autocovariance_matrix(m::ARMA_1_1,T=100)
autocovariance_matrix = get_autocovariance.(m, construct_time_matrix(T))
return autocovariance_matrix
end
function construct_time_matrix(T)
times = collect(0:T-1)
time_matrix = zeros(T,T)
for t in 1:T
time_matrix[t,1:t-1] = reverse(times[2:t])
time_matrix[t,t:T] = times[1:T-t+1]
end
return time_matrix
end
function get_autocovariance(m::ARMA_1_1,h)
if h == 0
return m.sigma^2 * (1 + (m.phi + m.theta)^2 / (1 - m.phi^2))
else
return m.sigma^2 * ((m.phi + m.theta)*m.phi^(h-1) + (m.phi + m.theta)^2*m.phi^h / (1 - m.phi^2))
end
end
function normalize_covariance(Sigma)
G = Diagonal(1 ./ diag(Sigma))
return G*Sigma
end
#-------------------------
Random.seed!(123)
T = 500
arma_model = ARMA_1_1(0.75,-0.5,1)
Sigma = construct_autocovariance_matrix(arma_model,T)
Sigma_tilde = normalize_covariance(Sigma)
unconditional = MvNormal(zeros(T),Sigma_tilde)
arma_sample = rand(unconditional)
exp_target = Exponential(0.5)
exp_sample = quantile.(exp_target, cdf.(Normal(),arma_sample))
arma_plot = plot(arma_sample,legend=:none,title = "ARMA(1,1) sample (standardized covariance matrix)",fmt=:png)
exp_plot = plot(exp_sample,legend=:none,title = "Transformed ARMA(1,1) sample")
plot(
arma_plot,
exp_plot,
layout = (2,1),
size=(1200,600),
fmt=:png
)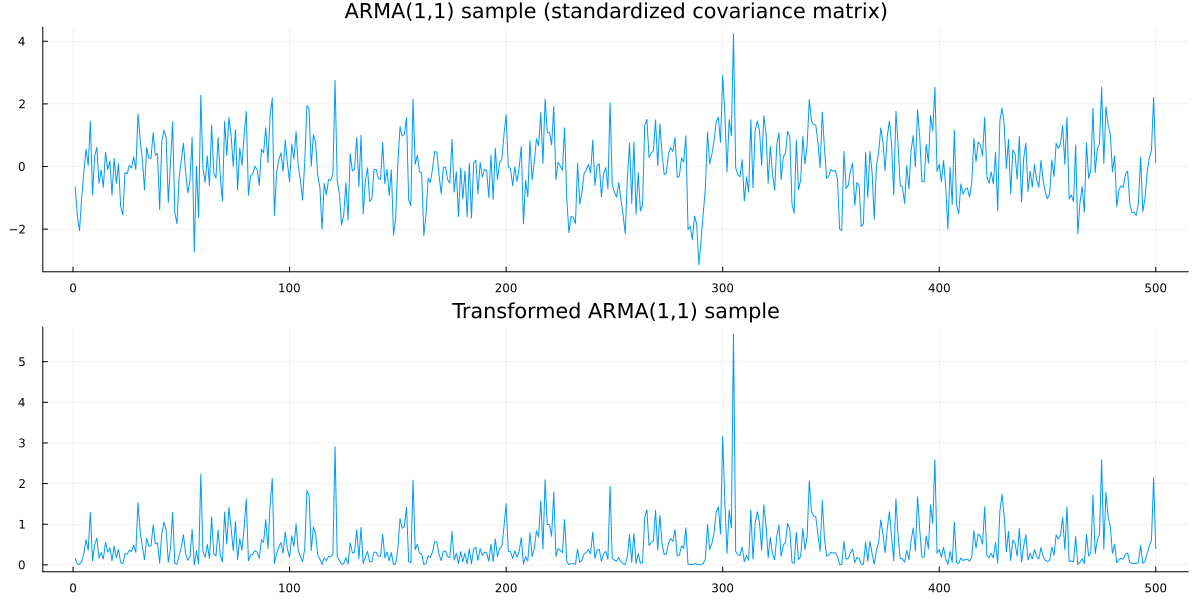
Clearly, the samples from the Copula model are not Gaussian anymore. In fact, we observe a single draw from a ARMA(1,1) Copula with Exponential-distributed marginals.
Parameter estimation with Maximum Likelihood
So far, we have only been able to simulate a time-series from the ARMA(1,1) Copula model. In order to fit the model, we will apply Maximum Likelihood. When using Copulas for cross-sectional data, it is usually possible to separate fitting the marginal distributions from fitting the Copula. Unfortunately, this does not work here.
As we only observe one realization of the process per marginal, fitting a distribution based on the marginals alone is impossible. Rather, we now need to optimize both the marginals and the copula at once. This begs the additional difficulty of having to deal with the marginal’s parameters inside the marginal’s c.d.f..
Namely, our Maximum likelihood objective looks as follows: where -
Standardized Gaussian Copula covariance matrix (with respect to the ARMA parameters) -
c.d.f. of an Exponential distribution with paramater -
probability density of an Exponential distribution with parameter
Optimizing this can become quite ugly as derivatives with respect to a c.d.f.’s parameters are usually fairly complex. Luckily, the Exponential distribution is quite simple and respective derivatives are easily found. Even better, the Optim.jl package can optimize our log-likelihood via finite differences without requiring any derivatives at all.
If we chose another distribution than the Exponential, finite differences might not suffice. In that case, we would have to either implement the c.d.f. derivatives by hand or hope that ChainRules.jl can handle them for us.
Also, we transform our model parameters to the correct domains via exp and tanh instead of applying Box constraints in the Optim optimizer. This worked reasonably accurate and fast here:
using Optim
function gauss_copula_ll(R,y)
n = size(R,2)
yt = transpose(y)
R_stab = R .+ Diagonal(ones(n).*1e-6)
return -0.5 * log(det(R_stab)) -0.5*(yt*(inv(R).-Diagonal(ones(n)))*transpose(yt))[1]
end
function likelihood_loss(params)
y_uniform = cdf.(Exponential(exp(params[1])),exp_sample)
model = ARMA_1_1(tanh(params[2]),tanh(params[3]),exp(params[4]))
autocov = construct_autocovariance_matrix(model,length(exp_sample))
normalized_autocov = Matrix(Hermitian(normalize_covariance(autocov)))
y_normal = quantile.(Normal(), y_uniform)
loss = -gauss_copula_ll(normalized_autocov,y_normal) - sum(logpdf.(Exponential(exp(params[1])),exp_sample))
return loss
end
res = optimize(likelihood_loss,[0.,0.,0.,-1],LBFGS()) * Status: success (objective increased between iterations)
* Candidate solution
Final objective value: 1.180344e+02
* Found with
Algorithm: L-BFGS
* Convergence measures
|x - x'| = 2.73e-10 ≰ 0.0e+00
|x - x'|/|x'| = 2.73e-10 ≰ 0.0e+00
|f(x) - f(x')| = 1.14e-13 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 9.63e-16 ≰ 0.0e+00
|g(x)| = 8.21e-09 ≤ 1.0e-08
* Work counters
Seconds run: 58 (vs limit Inf)
Iterations: 13
f(x) calls: 40
∇f(x) calls: 40Now, let us evaluate the result. For the Exponential distribution, the estimated parameter should be close to the true parameter. Regarding the latent ARMA parameters, we primarily need the estimated auto-covariance to be close to ground-truth. This is indeed the case here:
lambda = exp(res.minimizer[1])
phi = tanh(res.minimizer[2])
theta = tanh(res.minimizer[3])
sigma = exp(res.minimizer[4])
estimated_marginal = Exponential(lambda)
estimated_arma_model = ARMA_1_1(phi,theta,sigma)
true_acf = normalize_covariance(construct_autocovariance_matrix(arma_model,20))[1,:]
model_acf = normalize_covariance(construct_autocovariance_matrix(estimated_arma_model,20))[1,:]
lambda_plot = groupedbar([[0.5] [lambda]],labels=["True Exponential Parameter" "Model Exponential Parameter"]
,xlab="Lag",title="True VS. estimated parameter of Exponential distribution",
fmt=:png,size=(1000,500), margin=5mm)
acf_plot = groupedbar([true_acf model_acf],labels=["True ACF" "Model ACF"],xlab="Lag",title="True VS. estimated ACF",
fmt=:png,size=(1000,500), margin=5mm)
plot(lambda_plot,acf_plot,layout=(2,1))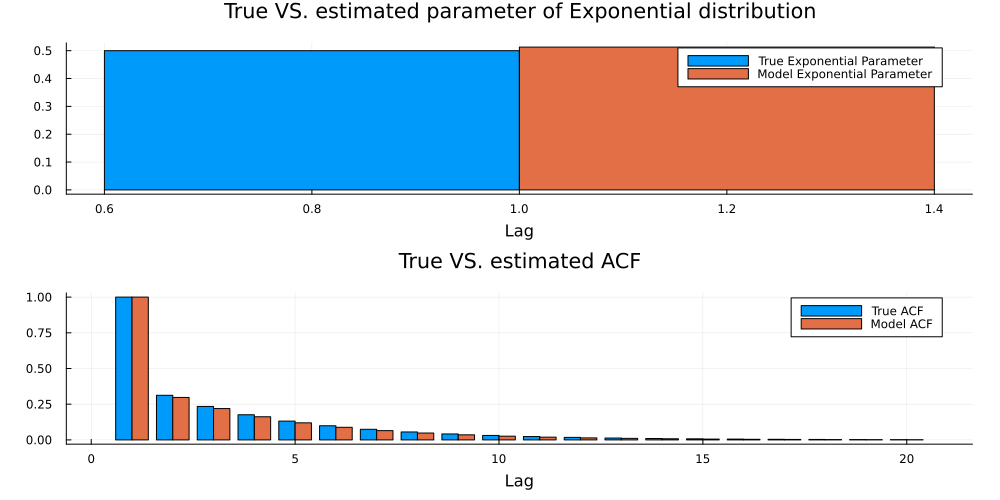
Forecasting with the Copula model
Finally, we want to use our model to produce actual forecasts. Due to the Copula construction, we can derive the conditional forecast density in closed form. As we will see however, mean and quantile forecasts need to be calculated numerically.
First, recall how the Copula model defines a joint density over all ‘training’-observations: In order to forecast a conditional density at h steps ahead, we simply need to follow standard probability laws:
This boils down to the ratio of two Copula evaluations times the marginal density evaluated at the target point. However, we still need to find a way to use this equation to calculate a mean forecast and a forecast interval.
As the density is arguably fairly complex, we won’t even try to derive any of these values in closed form. Rather, we use numerical methods to find the target quantities.
For the mean, we simply use quadrature to approximate the usual integral with U a sufficiently large value to capture most of the probability mass (approximation up to infinity is obviously not possible).
For the forecast interval, we use the 90% prediction interval. Thus, we need to find the 5% and the 95% quantiles of the conditional density. This can be done via another approximation, this time through an Ordinary Differential Equation: with
the quantile function corresponding to
evaluated at
For a derivation of this formula, see, for example, here. Integrating the ODE from zero up to the target quantile yields the respective target quantile value. The latter can be done numerically via DifferentialEquations.jl.
With this, we can finally calculate the forecast and plot the result:
using QuadGK
using DifferentialEquations
#precompute autocovariance matrix to save some computation time
T = 500+20
autocovariance = construct_autocovariance_matrix(estimated_arma_model, T)
normalized_autocov = normalize_covariance(autocovariance)
#this yields the conditional density for any ARMA, any Exponential marginal and at any 'h' in the future
function evaluate_conditional_density_forecast(x, model::ARMA_1_1, marginal::Distributions.Exponential, y, t_forecast=1)
T_train = length(y)
target_cov = normalized_autocov[vcat(collect(1:T_train),T_train+t_forecast),vcat(collect(1:T_train),T_train+t_forecast)]
y_normal = quantile.(Normal(),cdf.(marginal,y))
x_normal = quantile(Normal(),cdf(marginal,x))
copula_density_train = exp(gauss_copula_ll(target_cov[1:T_train,1:T_train],y_normal))
copula_density_full = exp(gauss_copula_ll(target_cov,vcat(y_normal,x_normal)))
marginal_density = pdf(marginal,x)
return marginal_density * copula_density_full/copula_density_train
end
#conditional density at forecast period 't'
p(x,t) = evaluate_conditional_density_forecast(x,estimated_arma_model,estimated_marginal,exp_sample,t)
#mean forecast uses Quadrature to approximate the intractable 'mean'-integral
mean_forecast = [quadgk(x->p(x,t)*x, 0, quantile(estimated_marginal, 1 - 1e-6), rtol=1e-4)[1] for t in 1:20]
#quantile forecast via differential equation:
#homepages.ucl.ac.uk/~ucahwts/lgsnotes/EJAM_Quantiles.pdf
function approximate_quantile(q, t=1)
target_density(x) = p(x,t)
diffeq(u,p,t) = 1/target_density(u)
u0=1e-6
tspan=(0.0,q)
prob = ODEProblem(diffeq,u0,tspan)
sol = solve(prob,Tsit5(),reltol=1e-4,abstol=1e-4)
return sol.u[end]
end
#10% prediction/forecast interval
lower_05 = [approximate_quantile(0.05,t) for t in 1:20]
upper_95 = [approximate_quantile(0.95,t) for t in 1:20]
#plot the final result
ribbon_lower = vcat(exp_sample[end],mean_forecast) .- vcat(exp_sample[end],lower_05)
ribbon_upper = vcat(exp_sample[end],upper_95) .- vcat(exp_sample[end],mean_forecast)
plot(collect(1:500)[end-49:end],exp_sample[end-49:end],fmt=:png,size=(1000,500),label="Last 50 observations from TS")
plot!(collect(500:520),vcat(exp_sample[end],mean_forecast),ribbon=(ribbon_lower,ribbon_upper),fmt=:png, label="Forecast plus interval")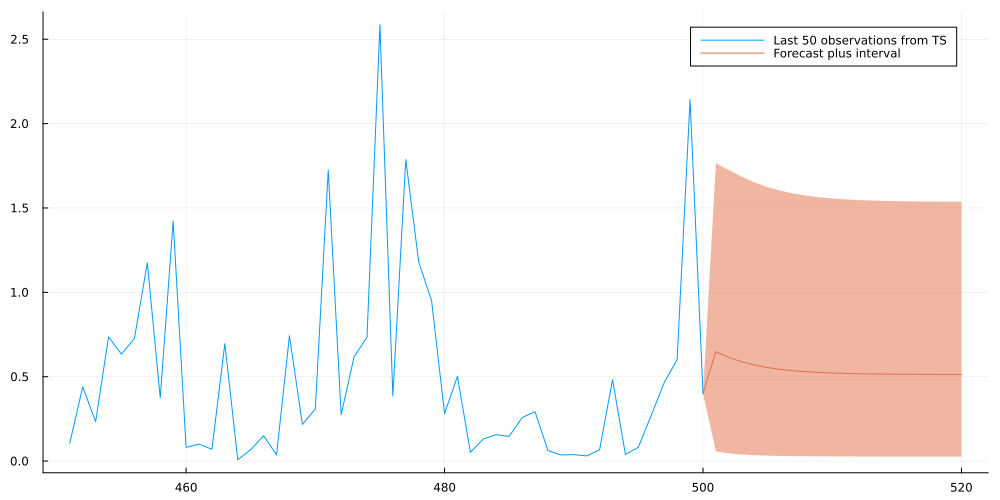
This looks indeed quite reasonable and the forecast appears to converge to a stable distribution as we predict further ahead into the future.
Conclusion
As we have seen, Copulas make it possible to extend well-known models to non-Gaussian data. This allowed us to transfer the simplicity of the ARMA model to Exponential marginals that were only defined for positive values.
One complication arises when the size of the observed time-series becomes very large. In that case, the unconditional covariance matrix will scale poorly and the model fitting step will likely become impossible.
Then, we need to find a computationally more efficient solution. One possible approach are Implicit Copulas which define a Copula density through a chain of conditional densities.
Of course, there are many other ways to integrate Copulas into classical statistical and Machine Learning models. For the latter, research is still a little sparse. However, I strongly believe that there is at least some potential for a modern application of these classic statistical objects.
References
[1] Hamilton, James Douglas. Time series analysis. Princeton university press, 2020.
[2] Nelsen, Roger B. An introduction to copulas. Springer Science & Business Media, 2007.
[3] Smith, Michael Stanley. Implicit copulas: An overview. Econometrics and Statistics, 2021.
Introduction
As I argued in an earlier article, Bayesian Machine Learning can be quite powerful. Building actual Bayesian models in Python, however, is sometimes a bit of a hassle. Most solutions that you will find online are either relatively complex or require learning yet another domain specific language. The latter could easily constrain your expressiveness when you need a highly customized solution.
Doing Bayesian Machine Learning in Julia, on the other hand, allows you to mitigate both these issues. In fact, you just need a few lines of raw Julia code to build, for example, a Bayesian Neural Network for regression. Julia’s Flux and Turing packages will then handle the heavy workload under the hood.
Hence today, I want to show you how to implement and train a Bayesian Neural Network in less than 30 lines of Julia. Before showing you the code, let us briefly recall the main theoretical aspects:
Bayesian Machine Learning in three steps
As always, we want to find a posterior distribution via Bayes’ law: As the data term in the denominator is a constant, we can simplify the above:
To avoid confusion, let us use the following standard wording:
For Bayesian Neural Network regression, we further specify the likelihood function:
This denotes a product of independent normal distributions with means defined by the outputs of a Neural Network. The variance of the Normal distribution is chosen to be a constant.
The corresponding prior distribution could look as follows: The priors for
network weights are independent standard normal distributions. For the square root of the variance (a.k.a. standard deviation), we use a standard Gamma distribution. So, from a theory perspective, we are all set up and ready to go.
Ideally, we now want to implement the Bayesian Neural Network in the following steps:
- Define the likelihood function
- Define the prior distribution
- Train the model
Having these three steps separate from each other in the code, will help us to
- Maintain readability - Besides the corresponding functions being smaller, a potential reader can also easier discern the likelihood from the prior.
- Keep the code testable at a granular level - Likelihood and prior distribution are clearly separate concerns. Thus, we should also be able to test them individually.
With this in mind, let us start building the model in Julia.
Defining the likelihood function
The Flux library provides everything we need to build and work with Neural Networks. It has Dense to build feedforward layers and Chain to combine the layers into a network.
Our Likelihood struct therefore consists of the Neural Network, network, and the standard deviation, sigma. In the feedforward pass, we use the network’s output and sigma to define conditional mean and standard deviation of the Gaussian likelihood:
using Flux, Distributions
struct Likelihood
network
sigma
end
Flux.@functor Likelihood #tell Flux to look for trainable parameters in Likelihood
(p::Likelihood)(x) = Normal.(p.network(x)[:], p.sigma[1]); #Flux only recognizes Matrix parameters but Normal() needs a scalar for sigmaThe dot in Normal.(...) lets us define one Normal distribution per network output, each with standard deviation sigma. We could combine this with logpdf(...) from the Distributions library in order to train the model with maximum likelihood gradient descent. To perform Bayesian Machine Learning, however, we need to add a few more elements.
This leads us to the central function of this article, namely Flux.destructure(). From the documentation:
@doc Flux.destructuredestructure(model) -> vector, reconstructorCopies all trainable, isnumeric parameters in the model to a vector, and returns also a function which reverses this transformation. Differentiable.
Example
julia> v, re = destructure((x=[1.0, 2.0], y=(sin, [3.0 + 4.0im])))
(ComplexF64[1.0 + 0.0im, 2.0 + 0.0im, 3.0 + 4.0im], Restructure(NamedTuple, ..., 3))
julia> re([3, 5, 7+11im])
(x = [3.0, 5.0], y = (sin, ComplexF64[7.0 + 11.0im]))If model contains various number types, they are promoted to make vector, and are usually restored by Restructure. Such restoration follows the rules of ChainRulesCore.ProjectTo, and thus will restore floating point precision, but will permit more exotic numbers like ForwardDiff.Dual.
If model contains only GPU arrays, then vector will also live on the GPU. At present, a mixture of GPU and ordinary CPU arrays is undefined behaviour.
In summary, destructure(...) takes an instantiated model struct and returns a tuple with two elements:
- The model parameters, concatenated into a single vector
- A reconstructor function that takes a parameter vector as in 1. as input and returns the model with those parameters
The latter is important as we can feed an arbitrary parameter vector to the reconstructor. As long as its length is valid, it returns the corresponding model with the given parameter configuration. In code:
likelihood = Likelihood(Chain(Dense(1,5,tanh),Dense(5,1)), ones(1,1))
params, likelihood_reconstructor = Flux.destructure(likelihood)
n_weights = length(params) - 1
likelihood_conditional(weights, sigma) = likelihood_reconstructor(vcat(weights...,sigma));The last function will allow us to provide weights and standard deviation parameters separately to the reconstructor. This is a necessary step in order for Turing to handle the Bayesian inference part.
From here, we are ready to move to the prior distribution.
Defining the prior distribution
This part is very short - we only need to define the prior distributions for the weight vector and the standard deviation scalar:
weight_prior = MvNormal(zeros(n_weights), ones(n_weights))
sigma_prior = Gamma(1.,1.);Having defined both likelihood and prior, we can take samples from the prior predictive distribution,
While this might look complicated as a formula, we are basically just drawing Monte Carlo samples. The prior predictive distribution itself includes the noise from sigma. Prior predictive draws from the network alone, i.e. the prior predictive mean, yield nice and smooth samples:
Xline = Matrix(transpose(collect(-3:0.1:3)[:,:]))
likelihood_conditional(rand(weight_prior), rand(sigma_prior))(Xline)
using Random, Plots
Random.seed!(54321)
plot(Xline[:],mean.(likelihood_conditional(rand(weight_prior), rand(sigma_prior))(Xline)),color=:red, legend=:none, fmt=:png)
plot!(Xline[:],mean.(likelihood_conditional(rand(weight_prior), rand(sigma_prior))(Xline)),color=:red)
plot!(Xline[:],mean.(likelihood_conditional(rand(weight_prior), rand(sigma_prior))(Xline)),color=:red)
plot!(Xline[:],mean.(likelihood_conditional(rand(weight_prior), rand(sigma_prior))(Xline)),color=:red)
plot!(Xline[:],mean.(likelihood_conditional(rand(weight_prior), rand(sigma_prior))(Xline)),color=:red)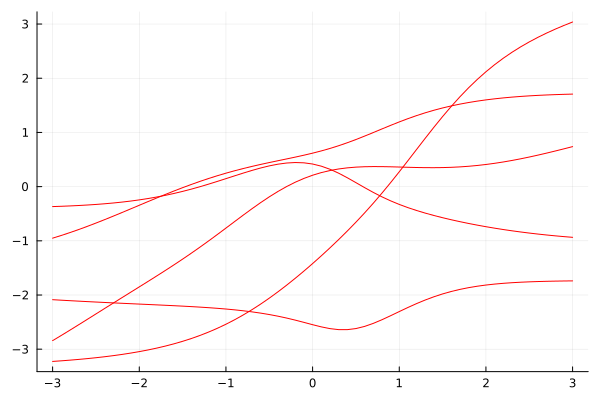
Now, we can actually train the model.
Training the Bayesian Neural Network
For this example, we’ll be using synthetic data, sampled from The latter factor denotes a uniform density over
.
Random.seed!(54321)
X = rand(1,50) .* 4 .- 2
y = sin.(X) .+ randn(1,50).*0.25
scatter(X[:], y[:],color=:green,legend=:none, fmt=:png)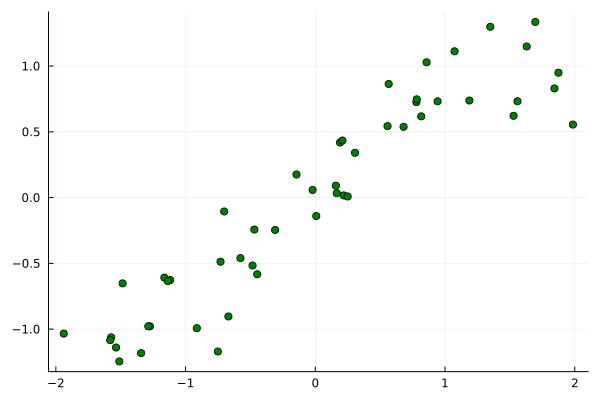
In order to use Turing, we need to define a model as explained in their documentation. Applied on our example, we get the following:
using Turing
@model function TuringModel(likelihood_conditional, weight_prior, sigma_prior, X, y)
weights ~ weight_prior
sigma ~ sigma_prior
predictions = likelihood_conditional(weights,sigma)(X)
y[:] ~ Product(predictions)
end;Finally, we need to choose an algorithm for Bayesian posterior inference. As our model is comparatively small, Hamiltonian Monte Carlo (HMC) is a suitable choice. In fact, HMC is generally considered the gold standard algorithm for Bayesian Machine Learning. Unfortunately, it becomes quite inefficient in high dimensions.
Nevertheless, we now use HMC via Turing and collect the resulting draws from the MCMC posterior:
using Random
Random.seed!(54321)
N = 5000
ch = sample(TuringModel(likelihood_conditional, weight_prior, sigma_prior, X , y), HMC(0.025, 4), N);
weights = Array(MCMCChains.group(ch, :weights).value) #get posterior MCMC samples for network weights
sigmas = Array(MCMCChains.group(ch, :sigma).value); #get posterior MCMC samples for standard deviationSampling: 100%|█████████████████████████████████████████| Time: 0:00:05From here, we can visualize the full posterior predictive distribution, This is done in a similar fashion as for the prior predictive distribution (star-variables denote new inputs outside the training set). The only difference is that we now use the samples from the MCMC posterior distribution.
Random.seed!(54321)
posterior_predictive_mean_samples = []
posterior_predictive_full_samples = []
for _ in 1:10000
samp = rand(1:5000,1)
W = weights[samp,:,1]
sigma = sigmas[samp,:,1]
posterior_predictive_model = likelihood_reconstructor(vcat(W[:],sigma[:]))
predictive_distribution = posterior_predictive_model(Xline)
postpred_full_sample = rand(Product(predictive_distribution))
push!(posterior_predictive_mean_samples,mean.(predictive_distribution))
push!(posterior_predictive_full_samples, postpred_full_sample)
end
posterior_predictive_mean_samples = hcat(posterior_predictive_mean_samples...)
pp_mean = mean(posterior_predictive_mean_samples, dims=2)[:]
pp_mean_lower = mapslices(x -> quantile(x,0.05),posterior_predictive_mean_samples, dims=2)[:]
pp_mean_upper = mapslices(x -> quantile(x,0.95),posterior_predictive_mean_samples, dims=2)[:]
posterior_predictive_full_samples = hcat(posterior_predictive_full_samples...)
pp_full_lower = mapslices(x -> quantile(x,0.05),posterior_predictive_full_samples, dims=2)[:]
pp_full_upper = mapslices(x -> quantile(x,0.95),posterior_predictive_full_samples, dims=2)[:]
plot(Xline[:],pp_mean, ribbon = (pp_mean.-pp_full_lower, pp_full_upper.-pp_mean),legend=:bottomright, label="Full posterior predictive distribution", fmt=:png)
plot!(Xline[:], pp_mean, ribbon = (pp_mean.-pp_mean_lower, pp_mean_upper.-pp_mean), label="Posterior predictive mean distribution (a.k.a. epistemic uncertainty)")
scatter!(X[:],y[:],color=:green, label = "Training data")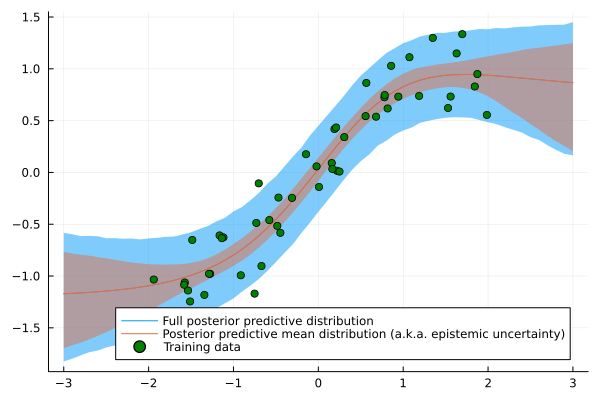
Using the above example, it is easy to try out other prior distributions.
Plug-and-play with different prior distributions
As another big advantage, Turing can use almost all distributions from the Distributions library as a prior. This also allows us to try out some exotic weight priors, say a Semicircle distribution with radius 0.5. All we have to do is replace the Gaussian prior:
weight_prior = Product([Semicircle(0.5) for _ in 1:n_weights]);With the same setup as before, we get the following posterior predictive distribution:
Random.seed!(54321)
N = 5000
ch = sample(TuringModel(likelihood_conditional, weight_prior, sigma_prior, X , y), HMC(0.025, 4), N);
weights = MCMCChains.group(ch, :weights).value #get posterior MCMC samples for network weights
sigmas = MCMCChains.group(ch, :sigma).value #get posterior MCMC samples for standard deviation
posterior_predictive_mean_samples = []
posterior_predictive_full_samples = []
for _ in 1:10000
samp = rand(1:5000,1)
W = weights[samp,:,1]
sigma = sigmas[samp,:,1]
posterior_predictive_model = likelihood_reconstructor(vcat(W[:],sigma[:]))
predictive_distribution = posterior_predictive_model(Xline)
postpred_full_sample = rand(Product(predictive_distribution))
push!(posterior_predictive_mean_samples,mean.(predictive_distribution))
push!(posterior_predictive_full_samples, postpred_full_sample)
end
posterior_predictive_mean_samples = hcat(posterior_predictive_mean_samples...)
pp_mean = mean(posterior_predictive_mean_samples, dims=2)[:]
pp_mean_lower = mapslices(x -> quantile(x,0.05),posterior_predictive_mean_samples, dims=2)[:]
pp_mean_upper = mapslices(x -> quantile(x,0.95),posterior_predictive_mean_samples, dims=2)[:]
posterior_predictive_full_samples = hcat(posterior_predictive_full_samples...)
pp_full_lower = mapslices(x -> quantile(x,0.05),posterior_predictive_full_samples, dims=2)[:]
pp_full_upper = mapslices(x -> quantile(x,0.95),posterior_predictive_full_samples, dims=2)[:]
plot(Xline[:],pp_mean, ribbon = (pp_mean.-pp_full_lower, pp_full_upper.-pp_mean),legend=:bottomright, label="Full posterior predictive distribution", fmt=:png)
plot!(Xline[:], pp_mean, ribbon = (pp_mean.-pp_mean_lower, pp_mean_upper.-pp_mean), label="Posterior predictive mean distribution (a.k.a. epistemic uncertainty)")
scatter!(X[:],y[:],color=:green, label = "Training data")Sampling: 100%|█████████████████████████████████████████| Time: 0:00:05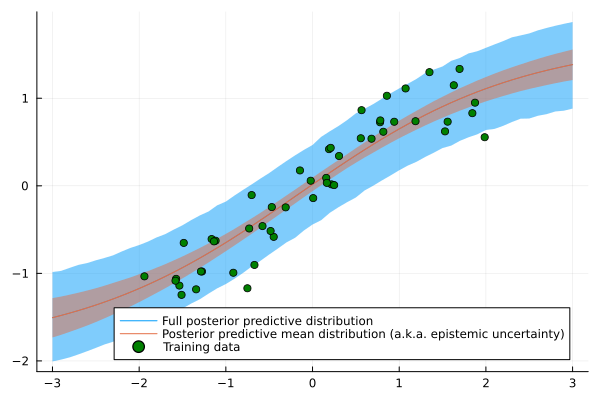
The possibilities obviously don’t stop here. Another fruitful adjustment could be the introduction of hyperprior distributions, e.g. over the standard deviation of the weight priors.
Using a model different from a Neural Network is also quite simple. You only need to adjust the Likelihood struct and corresponding functions.
Conclusion
This article was a brief introduction to Bayesian Machine Learning with Julia. As matter of fact, Julia is not just fast but can also make coding much easier and more efficient.
While Julia is still a young language with some caveats to deploying Julia programs to production, it is definitely an awesome language for research and prototyping. Especially the seamless interoperability between different libraries can considerably shorten iteration cycles both inside and outside of academia.
At this point, I am also quite hopeful that we will, at some point in the near future, see more Julia being used in industry-grade production code.
References
[1] Bezanson, Jeff, et al. Julia: A fast dynamic language for technical computing. arXiv preprint arXiv:1209.5145, 2012.
[2] Ge, Hong; Xu, Kai; Ghahramani, Zoubin. Turing: a language for flexible probabilistic inference. In: International conference on artificial intelligence and statistics. PMLR, 2018. p. 1682-1690.
Introduction
When it comes to Bayesian Machine Learning, you likely either love it or prefer to stay at a safe distance from anything Bayesian. Given that current state-of-the-art models hardly ever mention Bayes at all, there is probably at least some rationale behind the latter.
On the other hand, many high profile research groups are have been working on Bayesian Machine Learning tools for decades. And they still do.
Thus, it is rather unlikely that this field is complete quackery either. As often in life, the truth lies probably somewhere between the two extremes. In this article, I want to share my view on the titled question and point out when Bayesian Machine Learning can be helpful.
To avoid confusion, let us briefly define what Bayesian Machine Learning means in the context of this article:
“The Bayesian framework for machine learning states that you start out by enumerating all reasonable models of the data and assigning your prior belief P(M) to each of these models. Then, upon observing the data D, you evaluate how probable the data was under each of these models to compute P(D|M).” - Zoubin Ghahramani
Less formally, we apply tools and frameworks from Bayesian statistics to Machine Learning models. I will provide some references at the end, in case you are not familiar with Bayesian statistics yet.
Also, our discussion will essentially equate Machine Learning with neural networks and differentiable models in general (particularly Linear Regression). Since Deep Learning is currently the cornerstone of modern Machine Learning, this appears to be a fair approach.
As a final disclaimer, we will differentiate between frequentist and Bayesian Machine Learning. The former includes the standard ML methods and loss functions that you are probably already familiar with.
Finally, the fact that ‘Bayesian’ is written in uppercase but ‘frequentist’ is not has no judgemental meaning.
Now, let us begin with a surprising result:
Your frequentist model is probably already Bayesian
This statement might sound surprising and odd. However, there is a neat connection between the Bayesian and frequentist learning paradigm.
Let’s start with Bayes’ formula and apply it to a Bayesian Neural Network:
As an illustrative example, we could have
i.e. the network output defines the mean of the target variable which, presumably, follows a Normal distribution. For the prior over the network weights - let’s presume we have K weights in total - we might choose
The setup with (
) and (
) is fairly standard for Bayesian Neural Networks. Finding a posterior weight distribution for (
) turns out to be futile in any reasonable setting for Bayesian Networks. This is nothing new for Bayesian models either.
We now have a few options to deal with this issue, e.g. MCMC, Variational Bayes or Maximum a-posteriori estimation (MAP). Technically, the latter only gives us a point estimate for the posterior maximum, not the full posterior distribution: Given that a probability density is strictly positive over its domain, we can introduce logarithms:
Since the last summand does not depend on the model parameters, it does not affect the argmax. Hence, we can leave it out.
From Bayesian MAP to regularized MSE
The purpose of equations () and (
) was only an illustrative one. Let us replace likelihood and prior with the following:
The Z-terms are normalization constants whose sole purpose is to yield valid probability densities.
Now we can plug () and (
) into (
):
As the maximum of a function is equal to the minimum of the negative function, we can write
The final term is nothing more than the standard MSE-objective with regularization. Hence, a regularized MSE objective is equivalent to a Bayesian MAP objective, given specific prior and likelihood.
If you reverse the above, you can find a prior-likelihood pair for almost any frequentist loss function. However, the frequentist objective typically only point you a point solution.
The Bayesian method, on the other hand, gives you a full posterior distribution with uncertainty intervals on top. Using uninformative prior distributions you can also remove the regularization term if necessary. We won’t cover a derivation here, however.
The price of Bayesian Machine Learning in the real world
So, in theory, Bayesian Machine Learning yields a more complete picture than the frequentist approach. The caveat however is the intractability of the posterior distribution and thus the need to approximate or estimate it.
Both approximation and estimation, however, inevitably lead to a loss in precision. Take for example the popular variational inference approach for Bayesian Neural Networks. In order to optimize the model, we need to approximate a so-called ELBO-objective by sampling from the variational distribution.
The usual ELBO-objective looks like this - don’t worry if you don’t understand everything: Our goal is to either maximize (
) or minimize its negative. However, the expectation term is typically not intractable. The easiest solution to this issue is the application of the reparameterization trick. This allows us to estimate the ELBO via
The linearity of the gradient operation then allows us to estimate the gradient of (
) via:
With this formula, we are basically sampling M gradients from a reparametrized distribution. Thereafter, we use those samples to calculate an ‘average’ gradient.
Unbiased gradient estimation for the ELBO
As demonstrated in the landmark paper by Kingma and Welling (2013), we have In essence, equation (
) tells us that our sampling based gradient is, on average, equal to the true gradient. The problem with (
) is that we don’t know anything about the higher order statistical moments of sampled gradient.
For example, our estimate might have a prohibitively large variance. Thus, while we gradient descend in the correct direction on average, we are doing so unreasonably inefficiently.
The additional randomness due to resampling also makes it difficult to find the right stopping time for gradient descent. Add that to the problem of non-convex loss-functions and your chances of underperforming against a non-Bayesian network are fairly high.
In summary, the true posterior in a Bayesian world could give us a more complete picture about the optimal parameters. Since we need to resort to approximation however, we most likely end up with worse performance than with the standard approach.
When does Bayesian Machine Learning actually make sense?
The above considerations beg the question of whether you want to even use Bayesian Machine Learning at all. Personally, I see two particular situations where this could be the case. Keep in mind, that what follows are rules of thumb. The actual decision for or against Bayesian Machine Learning should be based on the specific problem at hand.

Small datasets and informative prior knowledge
Let us move back to the regularized MSE derivation from before. Our objective was There is a clear tradeoff between the size of the dataset,
, and the amount of model parameters,
. For sufficiently large datasets, the prior on the right side becomes irrelevant for the MAP solution and vice-versa. This is also a key property for posterior inference in general.
When the dataset is small in relation to the amount of model parameters, the posterior distribution will closely resemble the prior. Thus, if the prior distribution contains sensible information about the problem, we can mitigate the lack of data to some extent.
Take for example a plain linear regression model. Depending on the signal-to-noise ratio, a lot of data might be necessary before the parameters converge to the ‘best’ value. If you have a well reasoned prior distribution about that ‘best’ solution, your model might actually converge faster.
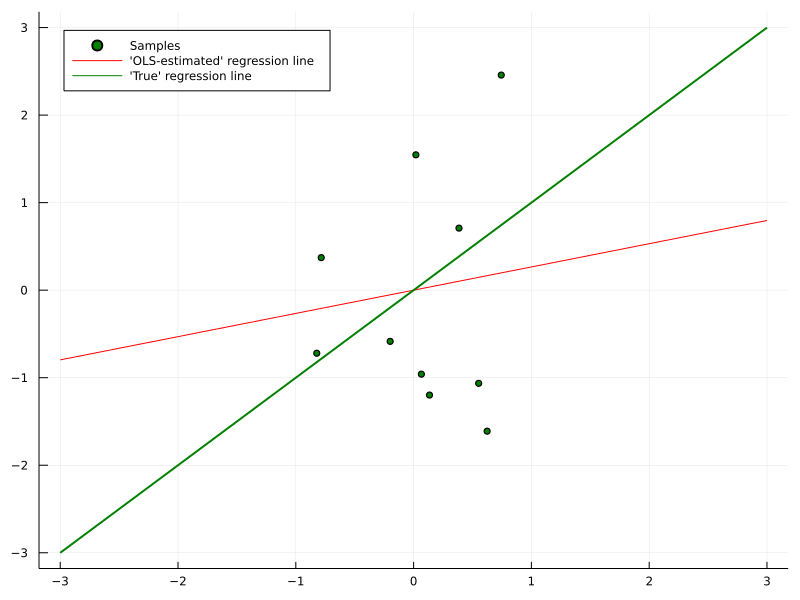
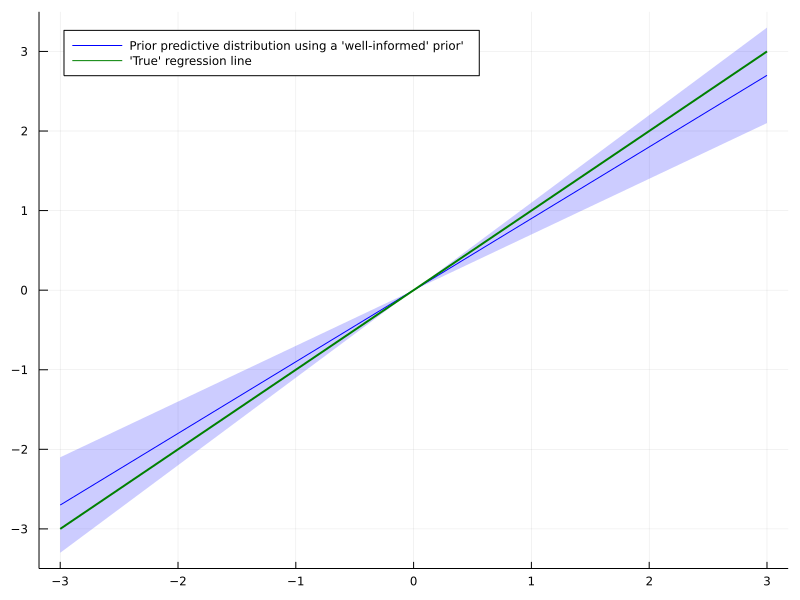
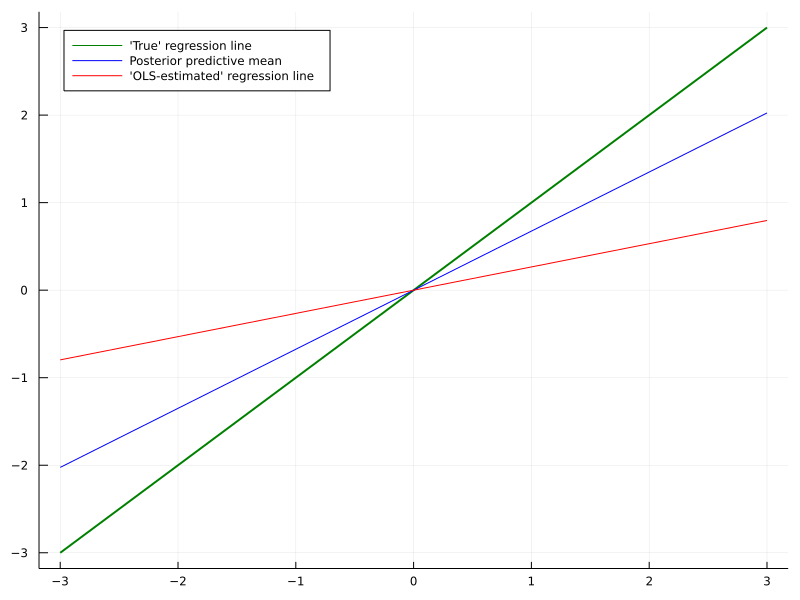
As a result, convergence to the ‘best’ solution could be even slower than without any prior at all. There are more tools in Bayesian statistics to mitigate this reasonable objection and I am keen to cover this topic in a future article.
Also, even if you don’t want to go fully Bayesian, a MAP estimate could still be useful given high-quality prior knowledge.
Functional priors for modern Bayesian Machine Learning
A different issue might be the difficulty of expressing meaningful prior knowledge over neural network weights. If the model is a black-box, how could you actually tell it what to do? Apart from maybe some vague zero-mean Normal distribution over weights?
One promising direction to solve this issue could be functional Bayes. In that approach, we only tell the network what outputs we expect for given inputs, based on our prior knowledge. Hence, we only care about the posterior functions that our model can express. The exact parameter posterior distribution is only of secondary interest.
In short, if you have only limited data but well-informed prior knowledge, Bayesian Machine Learning could actually help.
Importance of uncertainty quantification
For large datasets, the effect of your prior knowledge becomes less and less relevant. In that case, obtaining a frequentist solution might be fully sufficient and the superior approach. At some occasions however, the full picture - a.k.a. posterior uncertainty - could be important.
Consider the case of making a medical decision based on some Machine Learning model. In addition, the model does not produce a final decision but rather supports doctors in their judgement. If Bayesian point accuracy is at least close to a frequentist equivalent, uncertainty output can serve as useful extra information.
Presuming that the expert’s time is limited, they might want to take a closer look at highly uncertain model output. For output with low uncertainty, a quick sanity check might suffice. This of course requires the uncertainty estimates to be valid in the first place.
Hence, the Bayesian approach comes at the additional cost of monitoring uncertainty performance as well. This should of course be taken into account when deciding whether to use a Bayesian model or not.
Another example where Bayesian uncertainty can shine are time-series forecasting problems. If you model a time series in an autoregressive manner, i.e. you estimate your model errors accumulate, the further ahead you are trying to forecast.
Even for a highly simple autoregressive time-series such as a minuscule deviation in your estimated model
can lead to catastrophic error accumulation in the long run:
A full posterior could give a much clearer picture of how other, similarly probable scenarios might play out. Even though the model might be wrong on average, we nevertheless get an idea of how different parameter estimates affect the forecast.
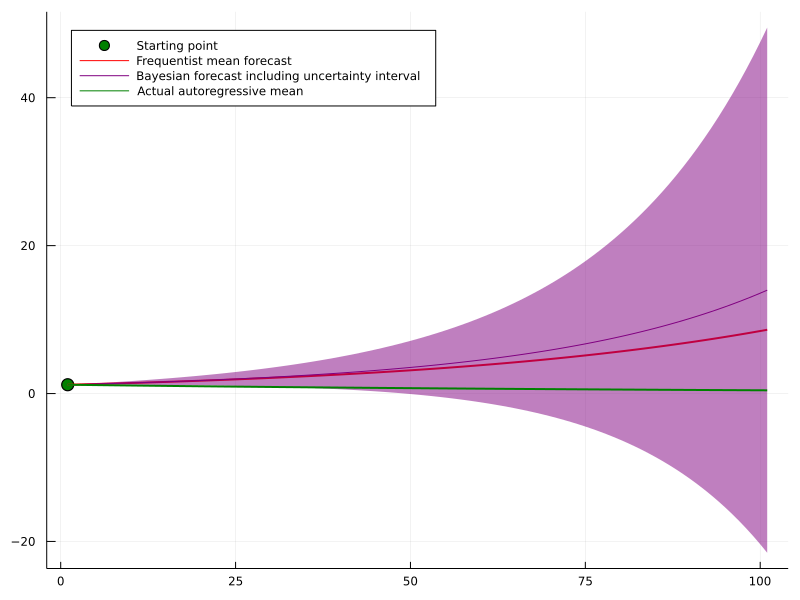
Finally, if the last paragraph has made you interested in trying out Bayesian Machine Learning, here is a great method to start with:
Bayesian Deep Learning light with MC dropout
Luckily, it is nowadays not too costly to train a Bayesian model. Unless you are working with very big models, the increased computational demand of Bayesian inference should not be too problematic.
One particularly straightforward approach to Bayesian inference is MC dropout. The latter was introduced by Gal and Ghahramani and has since become a fairly popular tool. In summary, the authors show that it is sensible to use Dropout during both training and inference of a model. In fact, this is proved to be equivalent to variational inference with a particular, Bernoulli-based, variational distribution.
Hence, MC Dropout can be a great starting point to make your Neural Network Bayes-ish without requiring too much effort upfront.
Pros and cons
On the one hand, MC dropout makes it quite straightforward to make an existing model Bayesian. You can simply re-train it with dropout and leave dropout turned on during inference. The samples you create that way can be seen as draws from the Bayesian posterior predictive distribution.
On the other hand, the variational distribution in MC dropout is based on Bernoulli random variables. This should - in theory - make it an even less accurate approximation than the common Gaussian variational distribution. However, building and using a this model is quite simple, requiring only plain Tensorflow or Pytorch.
Also, there has been some deeper criticism about the validity of the approach. There exists an interesting debate involving one of the authors here.
Whatever you make out of that criticism, MC Dropout can be a helpful baseline for more sophisticated methods. Once you get a hang of Bayesian Machine Learning, you can try to improve performance with more sophisticated model from there.
Conclusion
I hope that this article has given you some insights on the usefulness of Bayesian Machine Learning. Certainly, it is no magic bullet and there are many occasions where it might not be the right choice. If you carefully weigh in the pros and cons though, Bayesian methods can be a highly useful tool.
Also, I am happy to have a deeper discussion on the topic, either in the comments or via private channels.
References
[1] Gelman, Andrew, et al. “Bayesian data analysis”. CRC press, 2013.
[2] Kruschke, John. “Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan.” Academic Press, 2014.
[3] Sivia, Devinderjit, and John Skilling. “Data analysis: a Bayesian tutorial.” OUP Oxford, 2006.
Introduction
A common phenomenon when working on continuous regression problems is the non-constant residual variance, also known as heteroscedasticity. While heteroscedasticity is often seen in Statistics and Econometrics, it doesn’t seem to receive as much attention in mainstream Machine Learning and Data Science literature.
Although predicting the mean via MSE-minimisation is often sufficient and more pragmatic, a proper treatment of the variance can be helpful at times. See for example this past blog post of mine for more thoughts on this topic.
In this article I want to show an example of how we can use Gaussian Processes to model heteroscedastic data. Since explaining every theoretical aspect would go far beyond the scope of this post, I recommend reading the references if you are interested in such models. First, let us start with a brief problem definition.
Problem definition
At the heart of non-constant variance models lies the assumption of some functional relation between the input data and the variance of the target variable. Presuming also a Gaussian target variable, we can construct the following probabilistic setup:
Put plainly, given some input data, the corresponding target should be Gaussian with mean and variance being arbitrary functions of our inputs. Since our focus today is on the variance, let us simplify things a little with a zero-mean function, i.e.
Our task is now to find a suitable function for sigma squared.
If, ex-ante, we don’t know much about our target function, whatever model we come up with should account for our uncertainty about the actual functional form of sigma squared. This is also known as epistemic uncertainty and one of the main considerations in Bayesian Machine Learning. In simple terms, we now don’t expect that a single model would best describe our target function anymore.
Instead, a — possibly infinitely large — set of models is considered and our goal is to place a probability distribution (a.k.a. posterior distribution) on this set such that those models that best describe the data (a.k.a. likelihood) given the assumptions we made (a.k.a. prior distributions) are the most likely ones.
This is usually done in weight space by defining our set of models in an implicit manner via the sets of parameters that describe the models’ behaviour — probably the most famous example in Machine Learning are Bayesian Neural Networks. Another, more abstract approach is to directly work in function space, i.e. we now explicitly look for the most likely functions without requiring parameters to describe them in the first place.
Since we are working in the Bayesian domain, this also means that prior and posterior distributions aren’t put over parameters anymore but also directly over functions. One of the most iconic frameworks for such modelling is Gaussian Process (GP) regression.
If this is a new concept to you and sounds confusing, I recommend to not worry about the underlying assumptions for now and just look at the formulas. One of the — by number of citations — most popular books on Gaussian Process models, Gaussian Processes for Machine Learning (GPML) provides a very clear introduction to the theoretical setup and is completely open source. To prevent this article from overbloating, I will not go too much into details and rather suggest you study the topics you don’t understand yourself.
The model
Our goal will be to model the varying variance of the target variable through a GP, which looks as follows:
This implies that the logarithm of our variance function is a GP — we need to squash the raw GP through an exponential to ensure that the variance will always be greater than zero. Any other function that maps the real line to the positive reals will do here but the exponential arguably the most popular one.
The above also implies that the GP is actually a latent component of our model that we only observe indirectly from the data we collect. Finally, we presumed additional noise on the GP kernel via the delta summand which makes the model more stable in practice.
We can then derive the posterior distribution derived via Bayes’ theorem as follows:
While it is possible to derive the left-hand side in closed form for some basic GP models, we cannot do so in our case. Instead we will apply Laplace Approximation and approximate it through a synthetic multivariate Normal
The exact steps for Laplace Approximation are explained in Chapter 3 of the GPML book for a binary classification model and we only need to adjust the approach to our model.
In summary, the mean parameter of our approximation should match the mode of the posterior, while its covariance matrix is the negative inverse of the Hessian matrix of our data log-likelihood function. We have:
The first equation is derived from the fact that the denominator of the posterior formula does not depend on our target and by monotonicity of the logarithm function. The latter equation is derived from a second-order Taylor-expansion around the maximum of the posterior function.
To find the approximate mean and optimal kernel hyper-parameters for some example data later on, we will plug in the whole loss into an automatic differentiation package and let the computer do the rest. For the covariance matrix of our approximation, we need to actually calculate the Hessian matrix.
A common simplification for GP models is the assumption of independent observations of the target variable given a realisation of the latent GP:
This allows us to simplify the Hessian matrix to be zero everywhere, except for its diagonal which is the second-order derivative of the log-likelihood function with respect to the GP:
The right-hand side can be derived by differentiating the standard Gaussian log-likelihood twice with respect to the variance while accounting for our exponential transform:
Which yields
and
Finally, we need to derive the so-called posterior predictive distribution i.e. our predictions for new, unobserved inputs:
I will only state the results from GPML, chapter 3 for our setup, without the preceding derivations. First, we need to calculate the posterior predictive distribution for the latent GP which, using our approximation from above, is yet another GP:
where the K-variables denote the kernel covariance gram-matrices for training and evaluation dataset and the kernel cross-covariance matrix between training and evaluation datasets. If you are familiar with GP-regression, you can see that the posterior mean and covariance terms are almost the same as in the standard case, except that we accounted for the mean and covariance of our Laplace approximation.
Finally, we can derive the posterior predictive distribution for new data by marginalising out the GP posterior predictive function:
This integral is also intractable — luckily, since we only want to evaluate the posterior predictive distribution, we can sample from the target distribution via Monte Carlo sampling.
To demonstrate this approach in practice, I implemented a brief example in Julia.
A quick example using Julia
The data is a simple, 1D toy-example with 200 observations and generating distributions
i.e. the input variable is sampled uniformly between -3 and 3 and the target is drawn from a zero-mean Gaussian with periodic variance:
using Flux, Zygote, Distributions, DistributionsAD, FastGaussQuadrature, Plots, StatsPlots, KernelFunctions, LinearAlgebra, RandomRandom.seed!(987)
sample_size = 200
X = rand(1,sample_size).*6 .- 3
Xline = Matrix(transpose(collect(-3.9:0.1:3.9)[:,:])) #small, interpolated 1D grid for evalutaion
Xline_train = Xline[(Xline.>=-3) .& (Xline.<=3)]
y = randn(1,sample_size).*sin.(2 .*X)
plot(Xline_train,zeros(length(Xline_train));ribbon=(2 .* sin.(2 .*Xline_train)))
scatter!(X[:],y[:],legend=:none, fmt = :png,size=(1000,500),color=:red)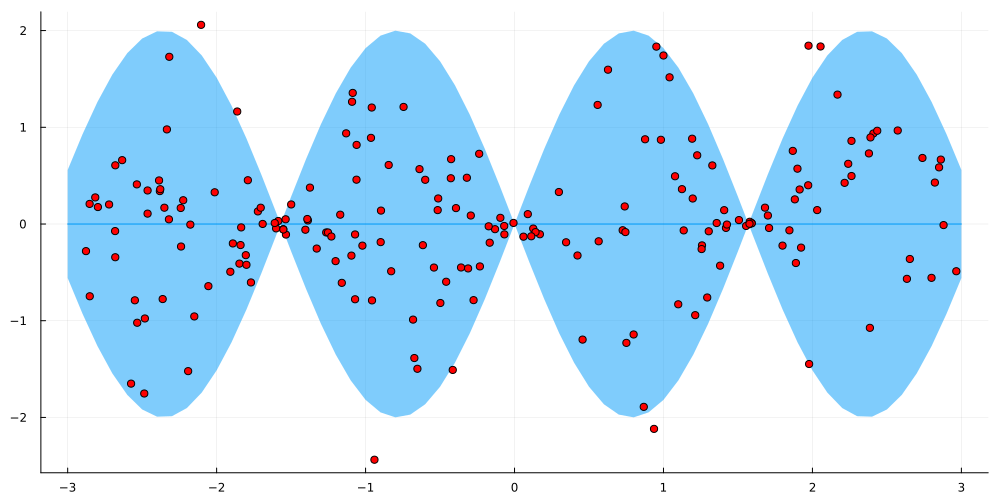
To fully define the GP, we also need to specify the kernel function — here I chose a standard Square-Exponential (SE) kernel plus the already mentioned additive noise term, i.e.
where all three hyper-parameters need to be positive. We now have all the formulas we need to define the necessary functions and structs (Julia’s counterpart to classes in object oriented languages)
mutable struct SEKernel <: KernelFunctions.Kernel
l_log
s_log
end
Flux.@functor SEKernel
SEKernel() = SEKernel(ones(1,1),ones(1,1))
#using KernelFunctions.jl for the primitives, we specify the raw SE-kernel here - the noise term will be added in the full model
KernelFunctions.kernelmatrix(m::SEKernel,x::Matrix,y::Matrix) = exp.(m.s_log)[1,1].*exp.(
-sum(exp.(m.l_log).*(Flux.unsqueeze(x,3).-Flux.unsqueeze(y,2)).^2,dims=1)[1,:,:]
)
KernelFunctions.kernelmatrix(m::SEKernel,x::Matrix) = KernelFunctions.kernelmatrix(m,x,x);mutable struct HeteroscedasticityGPModel
kern
f_hat
nu_log
end
Flux.@functor HeteroscedasticityGPModel
# 'n' specifies the dimensionality or our Laplace Approximation - needs to be equal to the size of the training dataset
HeteroscedasticityGPModel(n) = HeteroscedasticityGPModel(SEKernel(),zeros(1,n),ones(1,1))
# this is the log-likelihood term we need for calculating the optimal mean parameter of the Laplace Approximation - Zygote.jl and Flux.jl will be used for Autodiff
function loss(m::HeteroscedasticityGPModel,y,X)
_,N = size(m.f_hat)
K= kernelmatrix(m.kern,X)
likelihood_term = sum(llnormal.(y[:],zeros(N),m.f_hat[:]))
prior_term = Distributions.logpdf(MvNormal(zeros(N),K.+Diagonal(ones(N).*exp.(m.nu_log)[1,1])),m.f_hat[:])
return -likelihood_term - prior_term #negative since Flux.Optimise minimizes the target but we want to maximize it
end;#Manual derivation of log-likelihood and hessian diagonal of the log-likelihood with respect to f; the gradient is also included
llnormal(x,m,s) = -0.5 * log(2. * 3.14 * exp(s)) - 1 ./(2 .*exp(s))*(x-m)^2.
llnormgrad(x,m,s) = -0.5 + 0.5*1/exp(s)*(x-m)^2
llnormhess(x,m,s) = - 0.5/exp(s)*(x-m)^2
#finite differences test to ensure that the formulas for the gradient and hessian diagonal are correct
eps = 1e-10
@assert abs((llnormal(2,1,1)-llnormal(2,1,1-eps))/eps - llnormgrad(2,1,1)) < 1e-6
@assert abs((llnormgrad(2,1,1)-llnormgrad(2,1,1-eps))/eps - llnormhess(2,1,1)) <1e-6;model = HeteroscedasticityGPModel(sample_size)
params = Flux.params(model);#test that the Zygote.jl gradients are actually working
Zygote.gradient(()->loss(model,y,X),params);opt = ADAM(0.01)
for i in 1:2500
grads = Zygote.gradient(()->loss(model,y,X),params)
Flux.Optimise.update!(opt,params,grads)
if i%250==0
println(loss(model,y,X))
end
end;248.54495027449855
11.759623403151409
-221.67423883166694
-451.1514391636018
-659.5369049784196
-795.0349981998211
-752.3599410064332
-937.6992763973955
-922.2646364618785
-981.90093613224#calculate the posterior distribution of f evaluated at X_star
M,N = size(model.f_hat)
K= kernelmatrix(model.kern,hcat(X,Xline)).+Diagonal(exp(model.nu_log[1,1]).*ones(N+size(Xline)[2]))
A = inv(-Diagonal(llnormhess.(y[:],zeros(N),model.f_hat[:])).+Diagonal(ones(sample_size).*1e-6))
#kernel covariance matrices as
K_NN = K[1:sample_size,1:sample_size]
K_star_star = K[sample_size+1:end,sample_size+1:end]
K_star_N = K[sample_size+1:end,1:sample_size]
#posterior mean and covariance of the GP evaluated at `Xline`
mu_star = model.f_hat*inv(K_NN.+Diagonal(ones(sample_size).*1e-6))*transpose(K_star_N)
S_star = K_star_star.- K_star_N*inv(K_NN.+inv(K_NN.+A .+ Diagonal(ones(sample_size).*1e-6)))*transpose(K_star_N)
#posterior probability distribution of f, evaluated at X_star
p_f_star = MvNormal(mu_star[:],Symmetric(S_star.+Diagonal(ones(size(Xline)[2]).*1e-6)));The resulting functional posterior predictive distribution after optimising the above kernel hyper-parameters and the Laplace Approximation looks as follows:
# Monte Carlo sampling from the posterior predictive distribution for y_star
mc_samples = [randn(size(Xline)[2]).*sqrt.((exp.(rand(p_f_star)))) for _ in 1:100000]
mc_sample_matrix = hcat(mc_samples...)
#posterior predictive mean is zero by our model definition
posterior_predictive_mean = zeros(size(Xline)[2])[:]
posterior_predictive_std = std(mc_sample_matrix,dims=2)[:]
#plot(Xline[:],posterior_predictive_mean,legend=:none,ribbon=(posterior_predictive_mean.-ci_90percent_lower, ci_90percent_upper.-posterior_predictive_mean), fmt = :png,size=(1000,500),
#color=:green)
plot(Xline_train,zeros(length(Xline_train));ribbon=(2 .* sin.(2 .*Xline_train)))
plot!(Xline[:],posterior_predictive_mean,legend=:none,ribbon=2 * posterior_predictive_std, fmt = :png,size=(1000,500), color=:red)
#scatter!(X[:],y[:],color=:red)
To see what happens for data that lies outside of the range of our training data, the evaluation was performed on the interval. As you can see, the posterior predictive variance shows a sharp increase the further we look into the unknown.
This is exactly what should happen under the influence of epistemic uncertainty. To some extent, a model can learn which functions describe the target function in close distance to the training data. On the other hand, the set of candidate functions that might equally well describe data outside our observations grows larger the farther we move away from the training data.
Put simple, the less similar our test data is to the training data, the more uncertain we should be about our predictions. This uncertainty is expressed by the variance of the posterior predictive distribution — larger variance implies larger uncertainty.
We can also see this quite well by comparing the posterior predictive density for an X that lies in the center of observed data vs. the posterior predictive density for an X rather outside that range:
plot(density(mc_sample_matrix[findall(Xline[:].==0.)[1],:],legend=:none,color=:red,lw=4),density(mc_sample_matrix[findall(Xline[:].==-3.5)[1],:],legend=:none,color=:red,lw=4),
size=(1400,500),fmt=:png)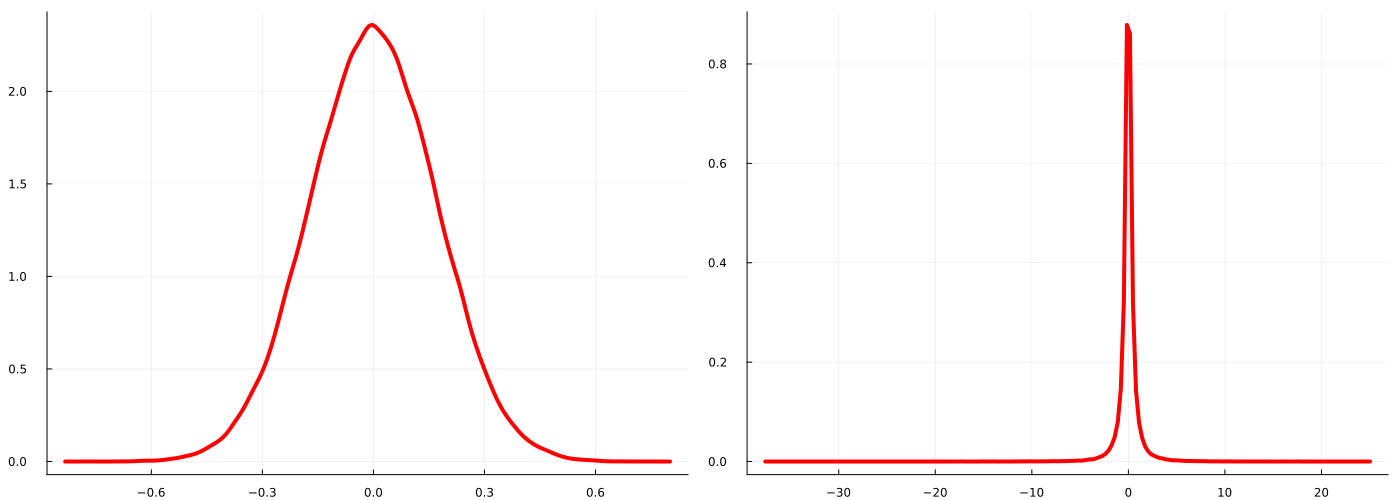
It is quite obvious that the posterior predictive density at -3.5 implies a much broader range of potential values for y than the posterior predictive density at zero. Being able to quantify such uncertainty is one of the most intriguing features of Bayesian Machine Learning and I can highly recommend to dive deeper into this vast topic.
Going further
It is quite obvious that the example we used was only a toy dataset and doesn’t yet prove anything about the real-world capabilities of the proposed model. If you are interested, feel free to use and modify the code and try the model on something more realistic.
One potential application for such models would be financial time-series data which are quite well known to exhibit highly variable variance in periods of crisis. While GARCH models are often consider state-of-the-art here, a GP model might be an interesting alternative. Another possible improvement for general continuous regression problems would be to also model the data mean as a GP.
A final word about scalability: Plain GP models like the one we discussed here are quite infamous for being infeasible for larger datasets. Luckily, many smart people have developed methods to solve these issues, at least to some extent. In case you are interested in such approaches, you can find an overview in these slides from the Gaussian Process Summer School 2019.
And that’s it for today. Thanks for reading this far and let me know in the comments if you have any questions or found any errors in this post
References
[1] RASMUSSEN, Carl Edward. Gaussian processes in machine learning. In: Summer school on machine learning. Springer, Berlin, Heidelberg, 2003.
[2] Bollerslev, Tim. Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 1986, 31. 3, p. 307-327.